 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating localized complexity of white-matter wiring with GANs
Oct 02, 2019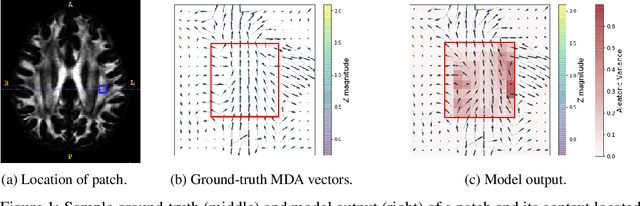
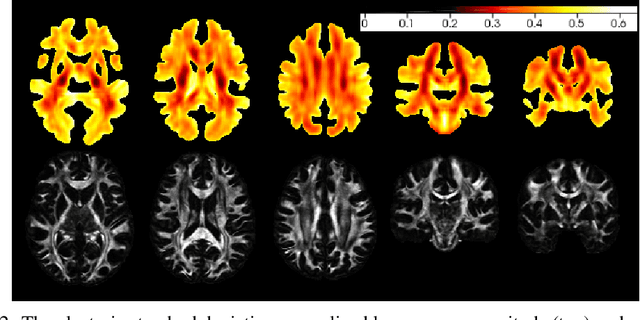
In-vivo examination of the physical connectivity of axonal projections through the white matter of the human brain is made possible by diffusion weighted magnetic resonance imaging (dMRI) Analysis of dMRI commonly considers derived scalar metrics such as fractional anisotrophy as proxies for "white matter integrity," and differences of such measures have been observed as significantly correlating with various neurological diagnosis and clinical measures such as executive function, presence of multiple sclerosis, and genetic similarity. The analysis of such voxel measures is confounded in areas of more complicated fiber wiring due to crossing, kissing, and dispersing fibers. Recently, Volz et al. introduced a simple probabilistic measure of the count of distinct fiber populations within a voxel, which was shown to reduce variance in group comparisons. We propose a complementary measure that considers the complexity of a voxel in context of its local region, with an aim to quantify the localized wiring complexity of every part of white matter. This allows, for example, identification of particularly ambiguous regions of the brain for tractographic approaches of modeling global wiring connectivity. Our method builds on recent advances in image inpainting, in which the task is to plausibly fill in a missing region of an image. Our proposed method builds on a Bayesian estimate of heteroscedastic aleatoric uncertainty of a region of white matter by inpainting it from its context. We define the localized wiring complexity of white matter as how accurately and confidently a well-trained model can predict the missing patch. In our results, we observe low aleatoric uncertainty along major neuronal pathways which increases at junctions and towards cortex boundaries. This directly quantifies the difficulty of lesion inpainting of dMRI images at all parts of white matter.
What Should I Ask? Using Conversationally Informative Rewards for Goal-Oriented Visual Dialog
Jul 28, 2019
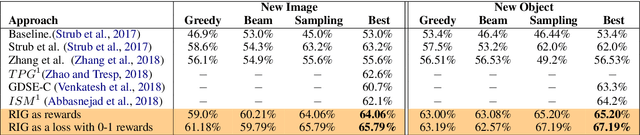
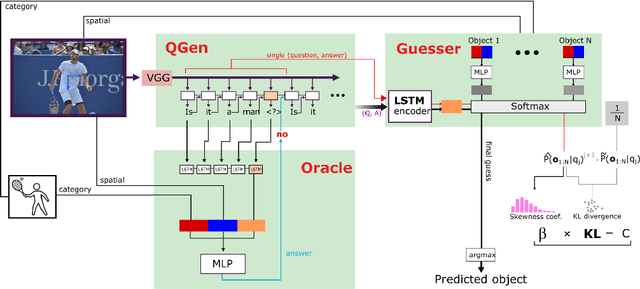
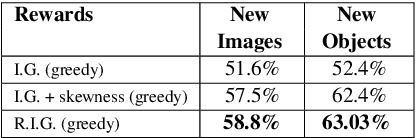
The ability to engage in goal-oriented conversations has allowed humans to gain knowledge, reduce uncertainty, and perform tasks more efficiently. Artificial agents, however, are still far behind humans in having goal-driven conversations. In this work, we focus on the task of goal-oriented visual dialogue, aiming to automatically generate a series of questions about an image with a single objective. This task is challenging since these questions must not only be consistent with a strategy to achieve a goal, but also consider the contextual information in the image. We propose an end-to-end goal-oriented visual dialogue system, that combines reinforcement learning with regularized information gain. Unlike previous approaches that have been proposed for the task, our work is motivated by the Rational Speech Act framework, which models the process of human inquiry to reach a goal. We test the two versions of our model on the GuessWhat?! dataset, obtaining significant results that outperform the current state-of-the-art models in the task of generating questions to find an undisclosed object in an image.