 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and evaluating computer vision models through the lens of counterfactuals
Aug 28, 2025Counterfactual reasoning -- the practice of asking ``what if'' by varying inputs and observing changes in model behavior -- has become central to interpretable and fair AI. This thesis develops frameworks that use counterfactuals to explain, audit, and mitigate bias in vision classifiers and generative models. By systematically altering semantically meaningful attributes while holding others fixed, these methods uncover spurious correlations, probe causal dependencies, and help build more robust systems. The first part addresses vision classifiers. CAVLI integrates attribution (LIME) with concept-level analysis (TCAV) to quantify how strongly decisions rely on human-interpretable concepts. With localized heatmaps and a Concept Dependency Score, CAVLI shows when models depend on irrelevant cues like backgrounds. Extending this, ASAC introduces adversarial counterfactuals that perturb protected attributes while preserving semantics. Through curriculum learning, ASAC fine-tunes biased models for improved fairness and accuracy while avoiding stereotype-laden artifacts. The second part targets generative Text-to-Image (TTI) models. TIBET provides a scalable pipeline for evaluating prompt-sensitive biases by varying identity-related terms, enabling causal auditing of how race, gender, and age affect image generation. To capture interactions, BiasConnect builds causal graphs diagnosing intersectional biases. Finally, InterMit offers a modular, training-free algorithm that mitigates intersectional bias via causal sensitivity scores and user-defined fairness goals. Together, these contributions show counterfactuals as a unifying lens for interpretability, fairness, and causality in both discriminative and generative models, establishing principled, scalable methods for socially responsible bias evaluation and mitigation.
Mitigate One, Skew Another? Tackling Intersectional Biases in Text-to-Image Models
May 22, 2025The biases exhibited by text-to-image (TTI) models are often treated as independent, though in reality, they may be deeply interrelated. Addressing bias along one dimension - such as ethnicity or age - can inadvertently affect another, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. To address this, we introduce BiasConnect, a novel tool for analyzing and quantifying bias interactions in TTI models. BiasConnect uses counterfactual interventions along different bias axes to reveal the underlying structure of these interactions and estimates the effect of mitigating one bias axis on another. These estimates show strong correlation (+0.65) with observed post-mitigation outcomes. Building on BiasConnect, we propose InterMit, an intersectional bias mitigation algorithm guided by user-defined target distributions and priority weights. InterMit achieves lower bias (0.33 vs. 0.52) with fewer mitigation steps (2.38 vs. 3.15 average steps), and yields superior image quality compared to traditional techniques. Although our implementation is training-free, InterMit is modular and can be integrated with many existing debiasing approaches for TTI models, making it a flexible and extensible solution.
BiasConnect: Investigating Bias Interactions in Text-to-Image Models
Mar 12, 2025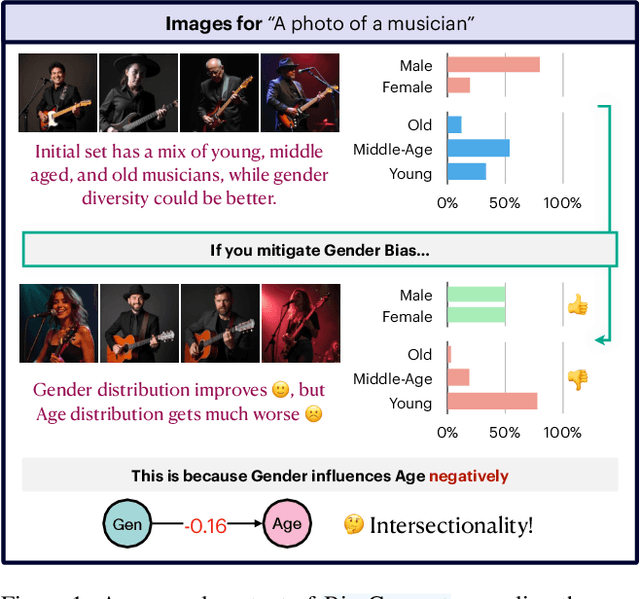
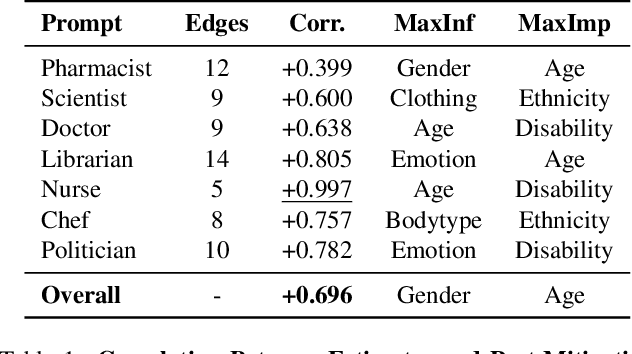
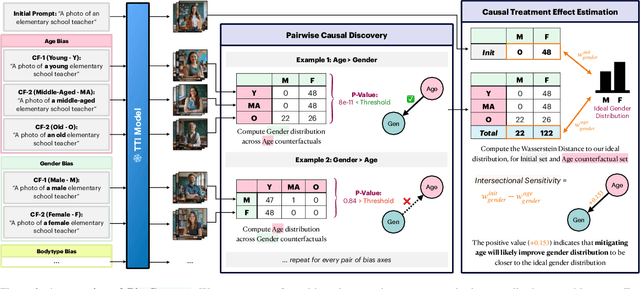
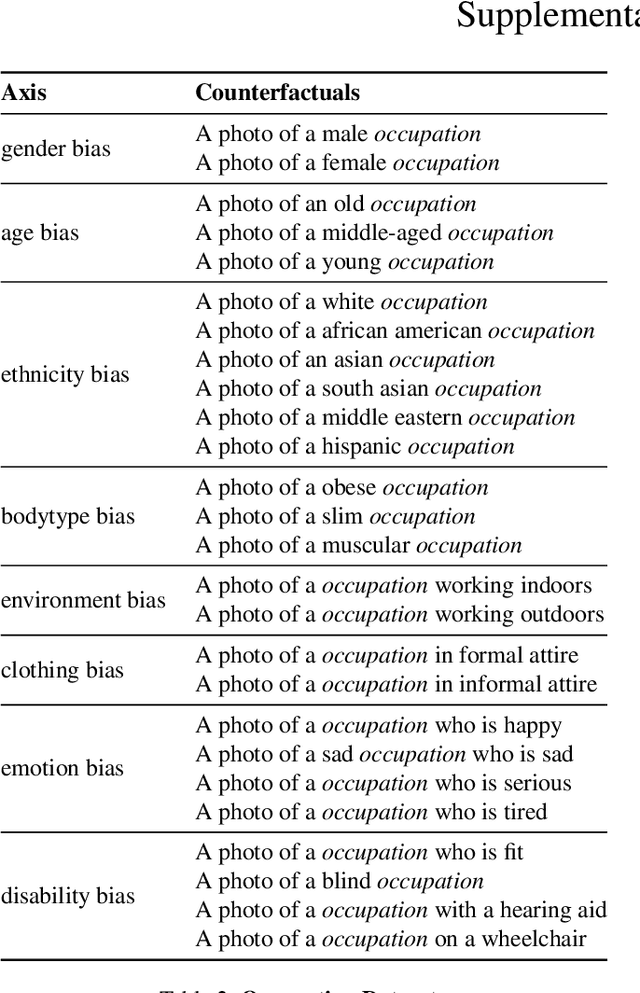
The biases exhibited by Text-to-Image (TTI) models are often treated as if they are independent, but in reality, they may be deeply interrelated. Addressing bias along one dimension, such as ethnicity or age, can inadvertently influence another dimension, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. In this paper, we aim to address these questions by introducing BiasConnect, a novel tool designed to analyze and quantify bias interactions in TTI models. Our approach leverages a counterfactual-based framework to generate pairwise causal graphs that reveals the underlying structure of bias interactions for the given text prompt. Additionally, our method provides empirical estimates that indicate how other bias dimensions shift toward or away from an ideal distribution when a given bias is modified. Our estimates have a strong correlation (+0.69) with the interdependency observations post bias mitigation. We demonstrate the utility of BiasConnect for selecting optimal bias mitigation axes, comparing different TTI models on the dependencies they learn, and understanding the amplification of intersectional societal biases in TTI models.
Utilizing Adversarial Examples for Bias Mitigation and Accuracy Enhancement
Apr 18, 2024

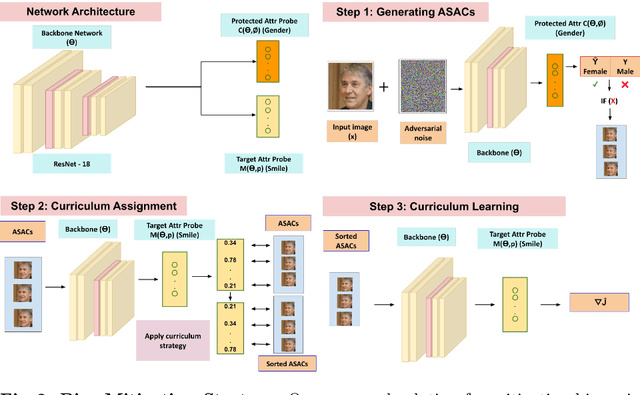

We propose a novel approach to mitigate biases in computer vision models by utilizing counterfactual generation and fine-tuning. While counterfactuals have been used to analyze and address biases in DNN models, the counterfactuals themselves are often generated from biased generative models, which can introduce additional biases or spurious correlations. To address this issue, we propose using adversarial images, that is images that deceive a deep neural network but not humans, as counterfactuals for fair model training. Our approach leverages a curriculum learning framework combined with a fine-grained adversarial loss to fine-tune the model using adversarial examples. By incorporating adversarial images into the training data, we aim to prevent biases from propagating through the pipeline. We validate our approach through both qualitative and quantitative assessments, demonstrating improved bias mitigation and accuracy compared to existing methods. Qualitatively, our results indicate that post-training, the decisions made by the model are less dependent on the sensitive attribute and our model better disentangles the relationship between sensitive attributes and classification variables.
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023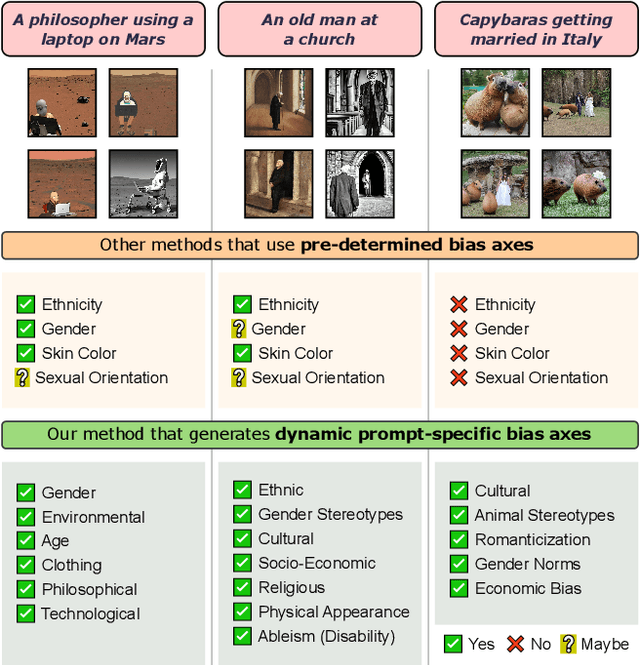

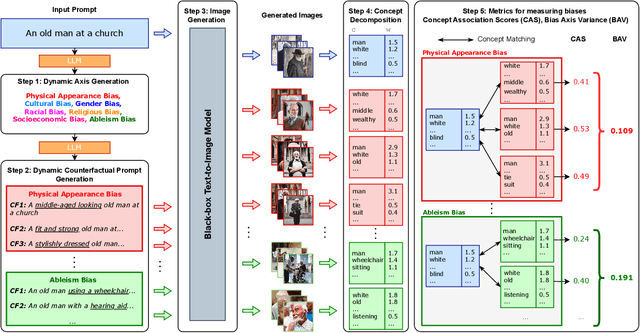
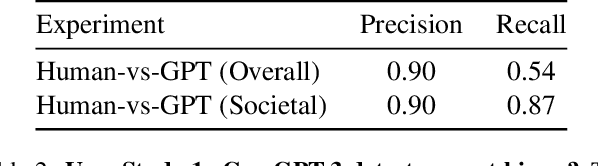
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020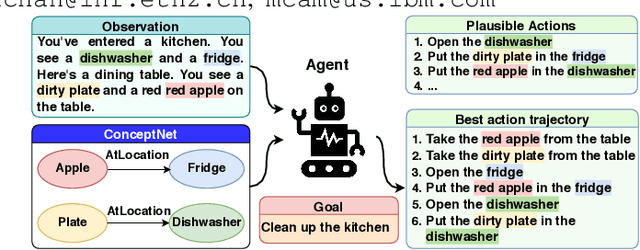


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.
Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge
May 02, 2020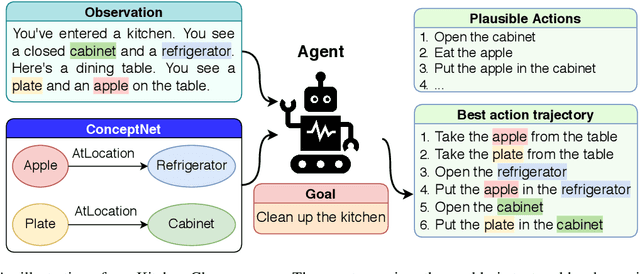
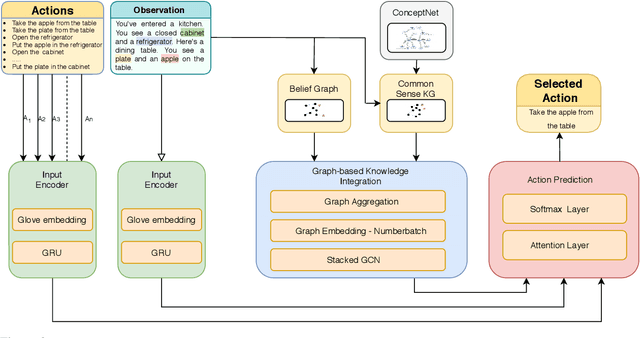
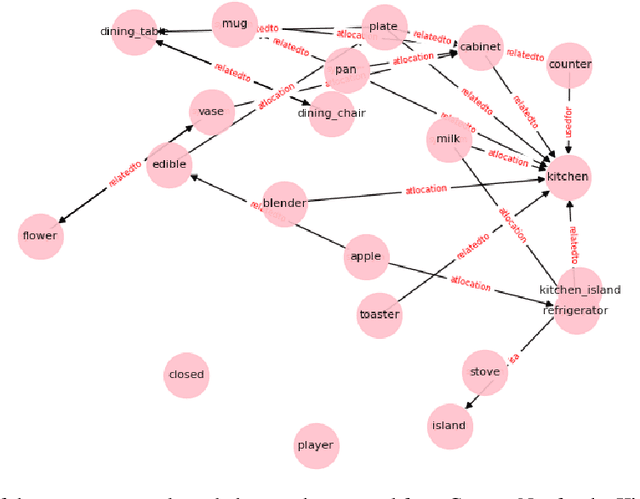
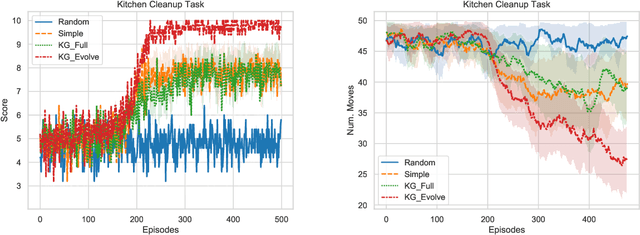
In this paper, we consider the recent trend of evaluating progress on reinforcement learning technology by using text-based environments and games as evaluation environments. This reliance on text brings advances in natural language processing into the ambit of these agents, with a recurring thread being the use of external knowledge to mimic and better human-level performance. We present one such instantiation of agents that use commonsense knowledge from ConceptNet to show promising performance on two text-based environments.
What Should I Ask? Using Conversationally Informative Rewards for Goal-Oriented Visual Dialog
Jul 28, 2019
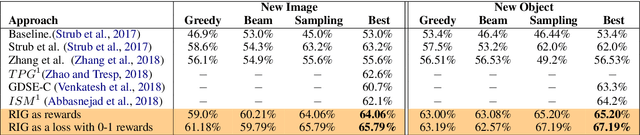
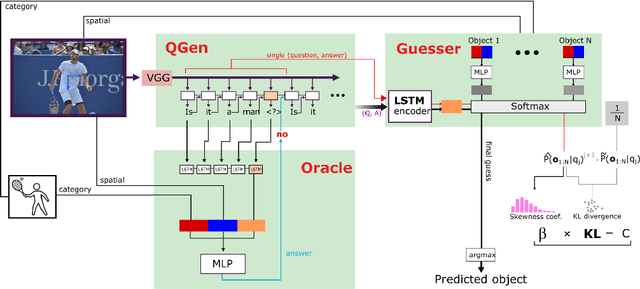
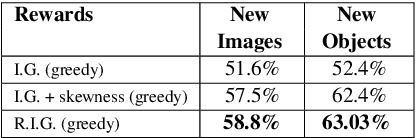
The ability to engage in goal-oriented conversations has allowed humans to gain knowledge, reduce uncertainty, and perform tasks more efficiently. Artificial agents, however, are still far behind humans in having goal-driven conversations. In this work, we focus on the task of goal-oriented visual dialogue, aiming to automatically generate a series of questions about an image with a single objective. This task is challenging since these questions must not only be consistent with a strategy to achieve a goal, but also consider the contextual information in the image. We propose an end-to-end goal-oriented visual dialogue system, that combines reinforcement learning with regularized information gain. Unlike previous approaches that have been proposed for the task, our work is motivated by the Rational Speech Act framework, which models the process of human inquiry to reach a goal. We test the two versions of our model on the GuessWhat?! dataset, obtaining significant results that outperform the current state-of-the-art models in the task of generating questions to find an undisclosed object in an image.