 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfusing Lattice Symmetry Priors in Attention Mechanisms for Sample-Efficient Abstract Geometric Reasoning
Jun 05, 2023



The Abstraction and Reasoning Corpus (ARC) (Chollet, 2019) and its most recent language-complete instantiation (LARC) has been postulated as an important step towards general AI. Yet, even state-of-the-art machine learning models struggle to achieve meaningful performance on these problems, falling behind non-learning based approaches. We argue that solving these tasks requires extreme generalization that can only be achieved by proper accounting for core knowledge priors. As a step towards this goal, we focus on geometry priors and introduce LatFormer, a model that incorporates lattice symmetry priors in attention masks. We show that, for any transformation of the hypercubic lattice, there exists a binary attention mask that implements that group action. Hence, our study motivates a modification to the standard attention mechanism, where attention weights are scaled using soft masks generated by a convolutional network. Experiments on synthetic geometric reasoning show that LatFormer requires 2 orders of magnitude fewer data than standard attention and transformers. Moreover, our results on ARC and LARC tasks that incorporate geometric priors provide preliminary evidence that these complex datasets do not lie out of the reach of deep learning models.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023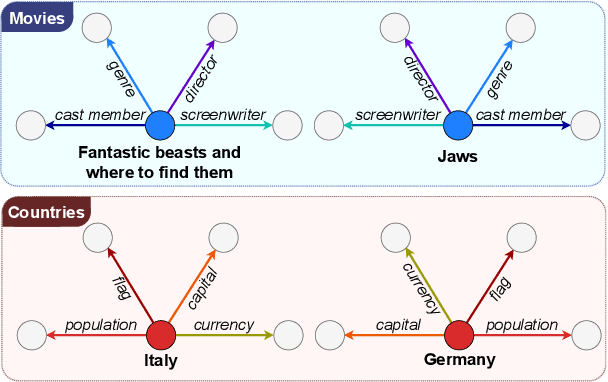
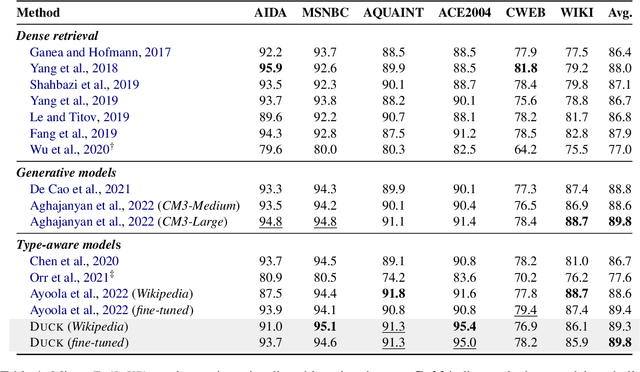
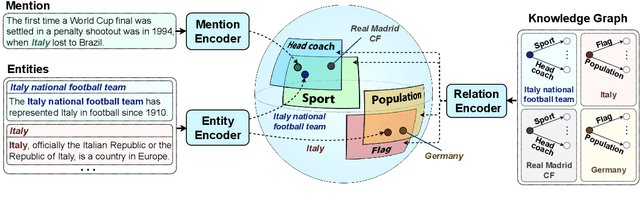
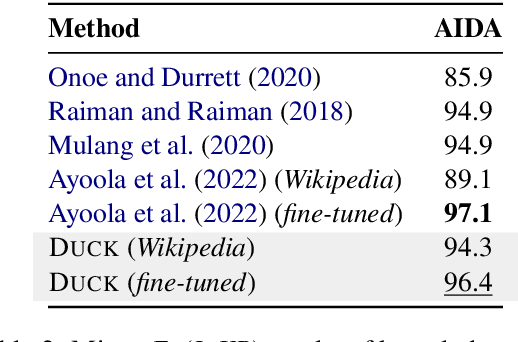
Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.
SQALER: Scaling Question Answering by Decoupling Multi-Hop and Logical Reasoning
Oct 27, 2021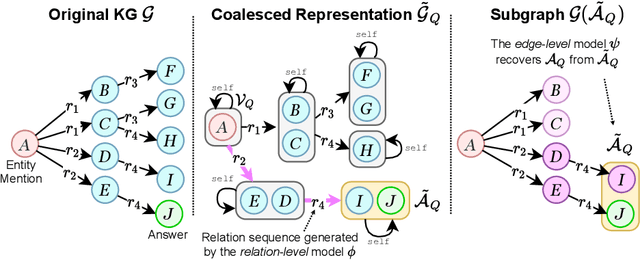
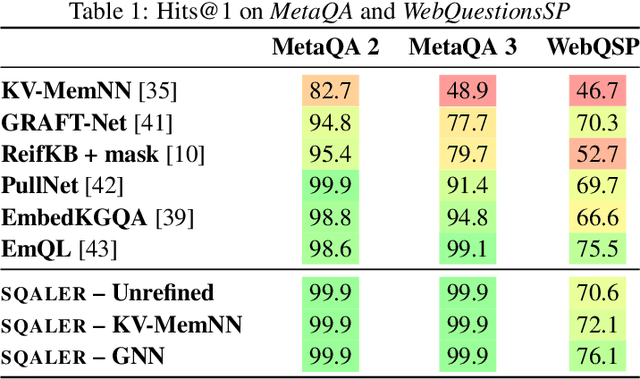
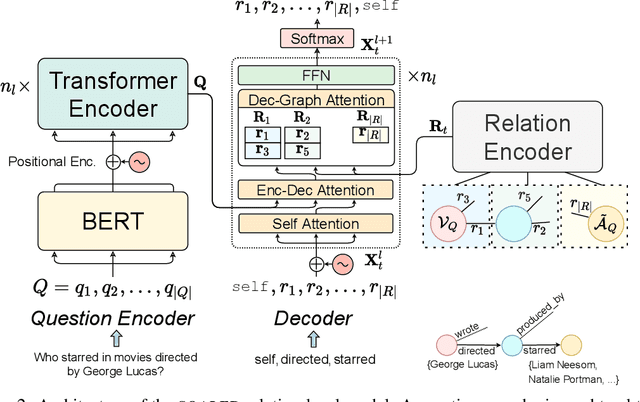
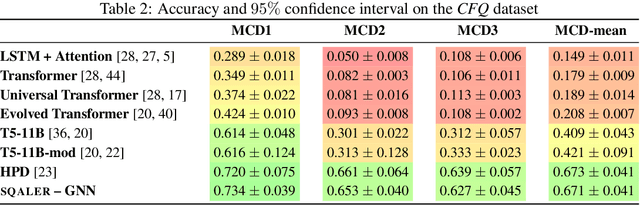
State-of-the-art approaches to reasoning and question answering over knowledge graphs (KGs) usually scale with the number of edges and can only be applied effectively on small instance-dependent subgraphs. In this paper, we address this issue by showing that multi-hop and more complex logical reasoning can be accomplished separately without losing expressive power. Motivated by this insight, we propose an approach to multi-hop reasoning that scales linearly with the number of relation types in the graph, which is usually significantly smaller than the number of edges or nodes. This produces a set of candidate solutions that can be provably refined to recover the solution to the original problem. Our experiments on knowledge-based question answering show that our approach solves the multi-hop MetaQA dataset, achieves a new state-of-the-art on the more challenging WebQuestionsSP, is orders of magnitude more scalable than competitive approaches, and can achieve compositional generalization out of the training distribution.
Case-based Reasoning for Better Generalization in Text-Adventure Games
Oct 16, 2021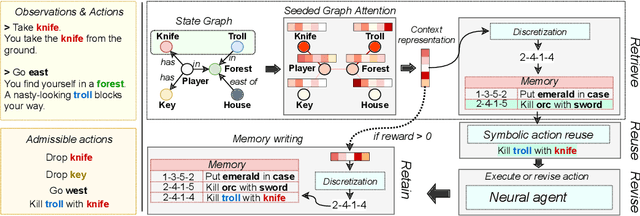
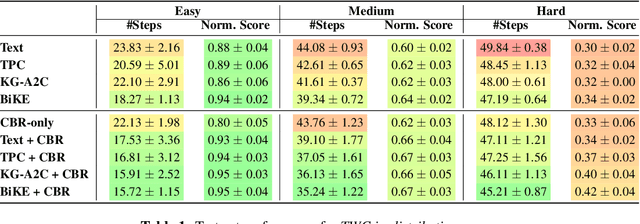
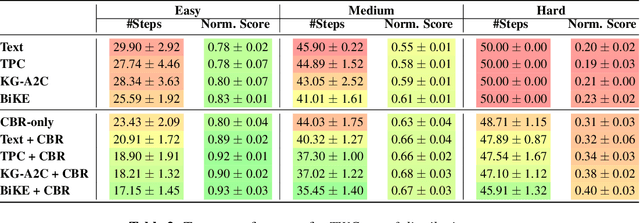
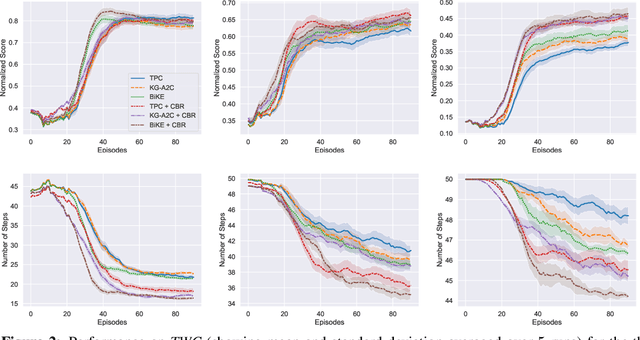
Text-based games (TBG) have emerged as promising environments for driving research in grounded language understanding and studying problems like generalization and sample efficiency. Several deep reinforcement learning (RL) methods with varying architectures and learning schemes have been proposed for TBGs. However, these methods fail to generalize efficiently, especially under distributional shifts. In a departure from deep RL approaches, in this paper, we propose a general method inspired by case-based reasoning to train agents and generalize out of the training distribution. The case-based reasoner collects instances of positive experiences from the agent's interaction with the world in the past and later reuses the collected experiences to act efficiently. The method can be applied in conjunction with any existing on-policy neural agent in the literature for TBGs. Our experiments show that the proposed approach consistently improves existing methods, obtains good out-of-distribution generalization, and achieves new state-of-the-art results on widely used environments.
Business Entity Matching with Siamese Graph Convolutional Networks
May 08, 2021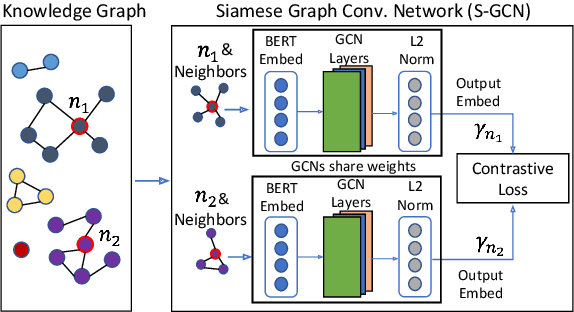

Data integration has been studied extensively for decades and approached from different angles. However, this domain still remains largely rule-driven and lacks universal automation. Recent developments in machine learning and in particular deep learning have opened the way to more general and efficient solutions to data-integration tasks. In this paper, we demonstrate an approach that allows modeling and integrating entities by leveraging their relations and contextual information. This is achieved by combining siamese and graph neural networks to effectively propagate information between connected entities and support high scalability. We evaluated our approach on the task of integrating data about business entities, demonstrating that it outperforms both traditional rule-based systems and other deep learning approaches.
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020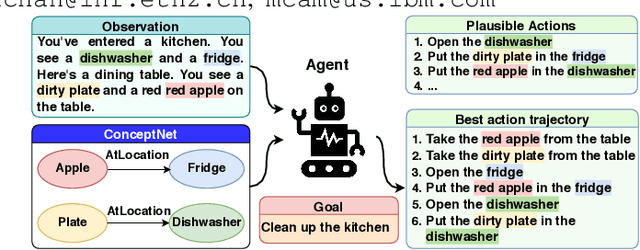


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.
Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge
May 02, 2020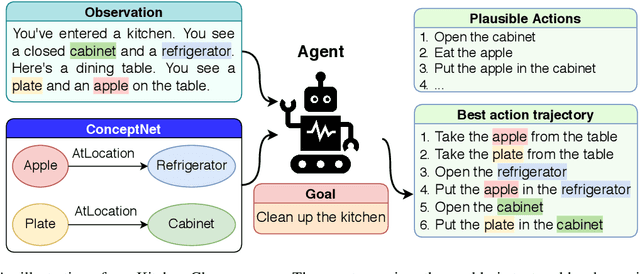
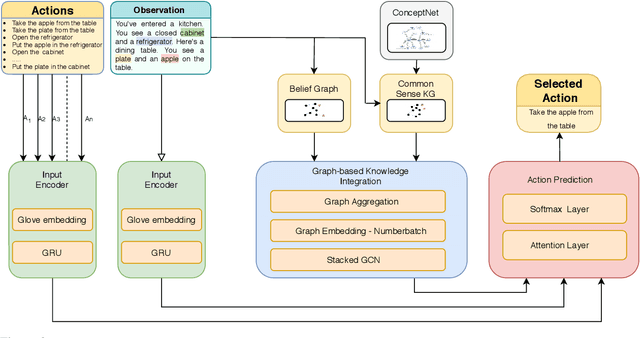
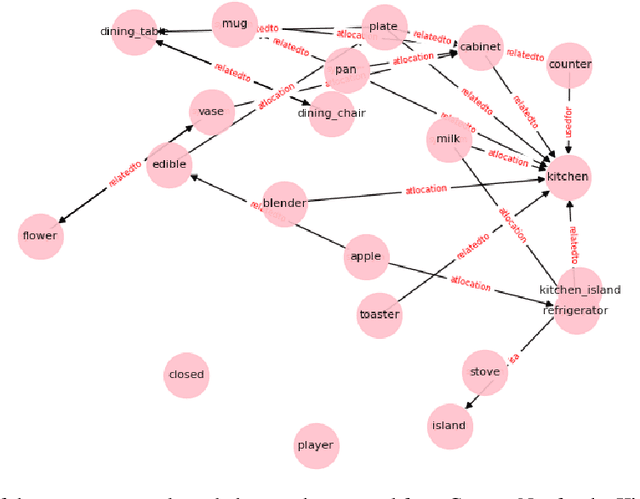
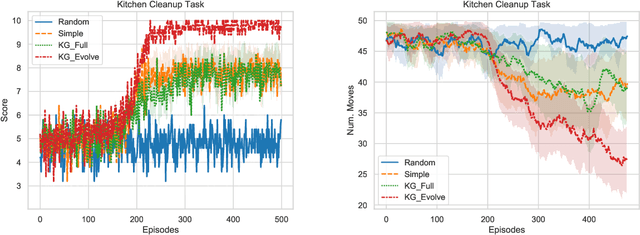
In this paper, we consider the recent trend of evaluating progress on reinforcement learning technology by using text-based environments and games as evaluation environments. This reliance on text brings advances in natural language processing into the ambit of these agents, with a recurring thread being the use of external knowledge to mimic and better human-level performance. We present one such instantiation of agents that use commonsense knowledge from ConceptNet to show promising performance on two text-based environments.
Siamese Graph Neural Networks for Data Integration
Jan 17, 2020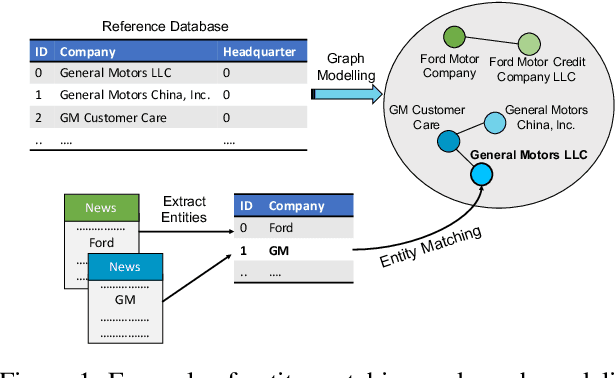

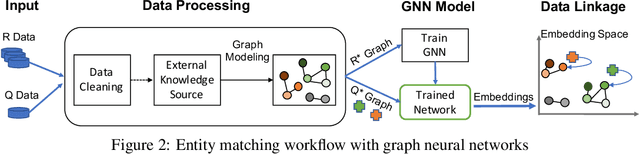
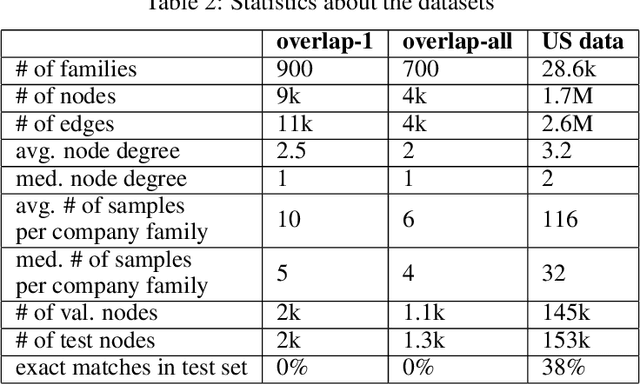
Data integration has been studied extensively for decades and approached from different angles. However, this domain still remains largely rule-driven and lacks universal automation. Recent development in machine learning and in particular deep learning has opened the way to more general and more efficient solutions to data integration problems. In this work, we propose a general approach to modeling and integrating entities from structured data, such as relational databases, as well as unstructured sources, such as free text from news articles. Our approach is designed to explicitly model and leverage relations between entities, thereby using all available information and preserving as much context as possible. This is achieved by combining siamese and graph neural networks to propagate information between connected entities and support high scalability. We evaluate our method on the task of integrating data about business entities, and we demonstrate that it outperforms standard rule-based systems, as well as other deep learning approaches that do not use graph-based representations.