 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Aware Model Adaptation via Feedback-Guided Optimization
Feb 02, 2026Fine-tuning is the primary mechanism for adapting foundation models to downstream tasks; however, standard approaches largely optimize task objectives in isolation and do not account for secondary yet critical alignment objectives (e.g., safety and hallucination avoidance). As a result, downstream fine-tuning can degrade alignment and fail to correct pre-existing misaligned behavior. We propose an alignment-aware fine-tuning framework that integrates feedback from an external alignment signal through policy-gradient-based regularization. Our method introduces an adaptive gating mechanism that dynamically balances supervised and alignment-driven gradients on a per-sample basis, prioritizing uncertain or misaligned cases while allowing well-aligned examples to follow standard supervised updates. The framework further learns abstention behavior for fully misaligned inputs, incorporating conservative responses directly into the fine-tuned model. Experiments on general and domain-specific instruction-tuning benchmarks demonstrate consistent reductions in harmful and hallucinated outputs without sacrificing downstream task performance. Additional analyses show robustness to adversarial fine-tuning, prompt-based attacks, and unsafe initializations, establishing adaptively gated alignment optimization as an effective approach for alignment-preserving and alignment-recovering model adaptation.
Mitigate One, Skew Another? Tackling Intersectional Biases in Text-to-Image Models
May 22, 2025The biases exhibited by text-to-image (TTI) models are often treated as independent, though in reality, they may be deeply interrelated. Addressing bias along one dimension - such as ethnicity or age - can inadvertently affect another, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. To address this, we introduce BiasConnect, a novel tool for analyzing and quantifying bias interactions in TTI models. BiasConnect uses counterfactual interventions along different bias axes to reveal the underlying structure of these interactions and estimates the effect of mitigating one bias axis on another. These estimates show strong correlation (+0.65) with observed post-mitigation outcomes. Building on BiasConnect, we propose InterMit, an intersectional bias mitigation algorithm guided by user-defined target distributions and priority weights. InterMit achieves lower bias (0.33 vs. 0.52) with fewer mitigation steps (2.38 vs. 3.15 average steps), and yields superior image quality compared to traditional techniques. Although our implementation is training-free, InterMit is modular and can be integrated with many existing debiasing approaches for TTI models, making it a flexible and extensible solution.
BiasConnect: Investigating Bias Interactions in Text-to-Image Models
Mar 12, 2025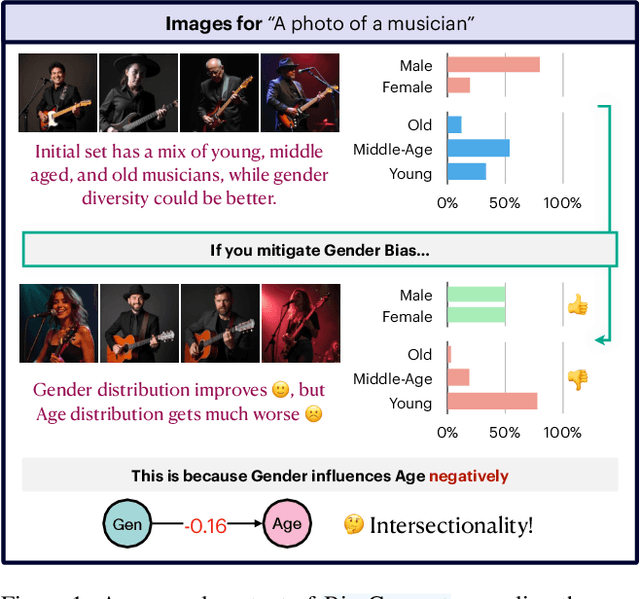
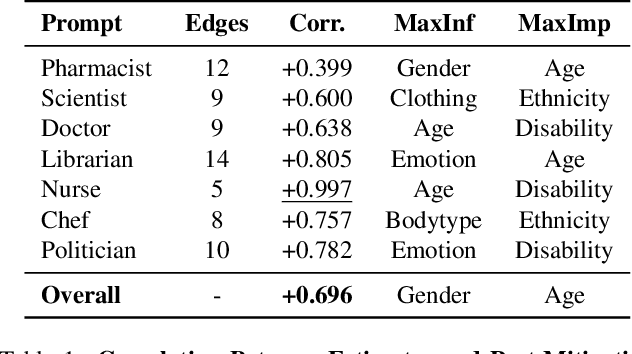
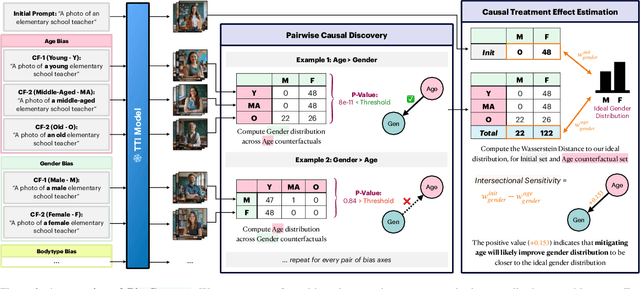
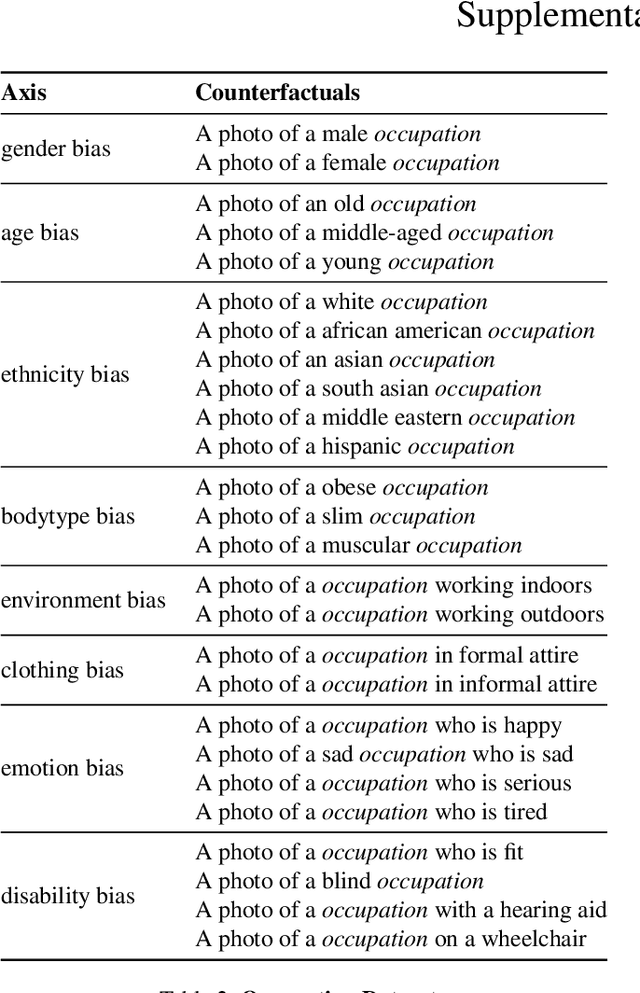
The biases exhibited by Text-to-Image (TTI) models are often treated as if they are independent, but in reality, they may be deeply interrelated. Addressing bias along one dimension, such as ethnicity or age, can inadvertently influence another dimension, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. In this paper, we aim to address these questions by introducing BiasConnect, a novel tool designed to analyze and quantify bias interactions in TTI models. Our approach leverages a counterfactual-based framework to generate pairwise causal graphs that reveals the underlying structure of bias interactions for the given text prompt. Additionally, our method provides empirical estimates that indicate how other bias dimensions shift toward or away from an ideal distribution when a given bias is modified. Our estimates have a strong correlation (+0.69) with the interdependency observations post bias mitigation. We demonstrate the utility of BiasConnect for selecting optimal bias mitigation axes, comparing different TTI models on the dependencies they learn, and understanding the amplification of intersectional societal biases in TTI models.
Black Swan: Abductive and Defeasible Video Reasoning in Unpredictable Events
Dec 07, 2024The commonsense reasoning capabilities of vision-language models (VLMs), especially in abductive reasoning and defeasible reasoning, remain poorly understood. Most benchmarks focus on typical visual scenarios, making it difficult to discern whether model performance stems from keen perception and reasoning skills, or reliance on pure statistical recall. We argue that by focusing on atypical events in videos, clearer insights can be gained on the core capabilities of VLMs. Explaining and understanding such out-of-distribution events requires models to extend beyond basic pattern recognition and regurgitation of their prior knowledge. To this end, we introduce BlackSwanSuite, a benchmark for evaluating VLMs' ability to reason about unexpected events through abductive and defeasible tasks. Our tasks artificially limit the amount of visual information provided to models while questioning them about hidden unexpected events, or provide new visual information that could change an existing hypothesis about the event. We curate a comprehensive benchmark suite comprising over 3,800 MCQ, 4,900 generative and 6,700 yes/no tasks, spanning 1,655 videos. After extensively evaluating various state-of-the-art VLMs, including GPT-4o and Gemini 1.5 Pro, as well as open-source VLMs such as LLaVA-Video, we find significant performance gaps of up to 32% from humans on these tasks. Our findings reveal key limitations in current VLMs, emphasizing the need for enhanced model architectures and training strategies.
From Local Concepts to Universals: Evaluating the Multicultural Understanding of Vision-Language Models
Jun 28, 2024



Despite recent advancements in vision-language models, their performance remains suboptimal on images from non-western cultures due to underrepresentation in training datasets. Various benchmarks have been proposed to test models' cultural inclusivity, but they have limited coverage of cultures and do not adequately assess cultural diversity across universal as well as culture-specific local concepts. To address these limitations, we introduce the GlobalRG benchmark, comprising two challenging tasks: retrieval across universals and cultural visual grounding. The former task entails retrieving culturally diverse images for universal concepts from 50 countries, while the latter aims at grounding culture-specific concepts within images from 15 countries. Our evaluation across a wide range of models reveals that the performance varies significantly across cultures -- underscoring the necessity for enhancing multicultural understanding in vision-language models.
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023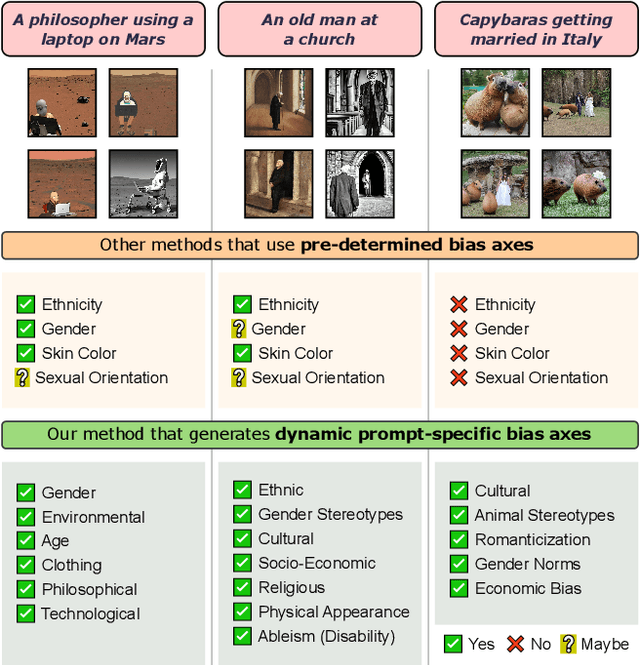

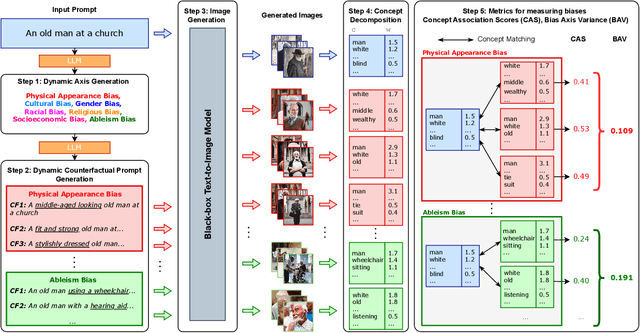
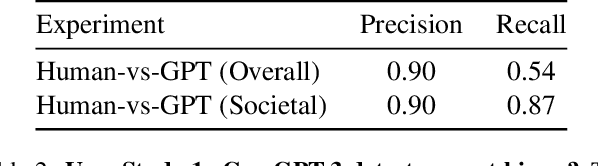
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
VLC-BERT: Visual Question Answering with Contextualized Commonsense Knowledge
Oct 24, 2022There has been a growing interest in solving Visual Question Answering (VQA) tasks that require the model to reason beyond the content present in the image. In this work, we focus on questions that require commonsense reasoning. In contrast to previous methods which inject knowledge from static knowledge bases, we investigate the incorporation of contextualized knowledge using Commonsense Transformer (COMET), an existing knowledge model trained on human-curated knowledge bases. We propose a method to generate, select, and encode external commonsense knowledge alongside visual and textual cues in a new pre-trained Vision-Language-Commonsense transformer model, VLC-BERT. Through our evaluation on the knowledge-intensive OK-VQA and A-OKVQA datasets, we show that VLC-BERT is capable of outperforming existing models that utilize static knowledge bases. Furthermore, through a detailed analysis, we explain which questions benefit, and which don't, from contextualized commonsense knowledge from COMET.