 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Natural Language Processing Models Across Jurisdictions: A pilot Study in Canadian Cancer Registries
Jan 02, 2026Population-based cancer registries depend on pathology reports as their primary diagnostic source, yet manual abstraction is resource-intensive and contributes to delays in cancer data. While transformer-based NLP systems have improved registry workflows, their ability to generalize across jurisdictions with differing reporting conventions remains poorly understood. We present the first cross-provincial evaluation of adapting BCCRTron, a domain-adapted transformer model developed at the British Columbia Cancer Registry, alongside GatorTron, a biomedical transformer model, for cancer surveillance in Canada. Our training dataset consisted of approximately 104,000 and 22,000 de-identified pathology reports from the Newfoundland & Labrador Cancer Registry (NLCR) for Tier 1 (cancer vs. non-cancer) and Tier 2 (reportable vs. non-reportable) tasks, respectively. Both models were fine-tuned using complementary synoptic and diagnosis focused report section input pipelines. Across NLCR test sets, the adapted models maintained high performance, demonstrating transformers pretrained in one jurisdiction can be localized to another with modest fine-tuning. To improve sensitivity, we combined the two models using a conservative OR-ensemble achieving a Tier 1 recall of 0.99 and reduced missed cancers to 24, compared with 48 and 54 for the standalone models. For Tier 2, the ensemble achieved 0.99 recall and reduced missed reportable cancers to 33, compared with 54 and 46 for the individual models. These findings demonstrate that an ensemble combining complementary text representations substantially reduce missed cancers and improve error coverage in cancer-registry NLP. We implement a privacy-preserving workflow in which only model weights are shared between provinces, supporting interoperable NLP infrastructure and a future pan-Canadian foundation model for cancer pathology and registry workflows.
SEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
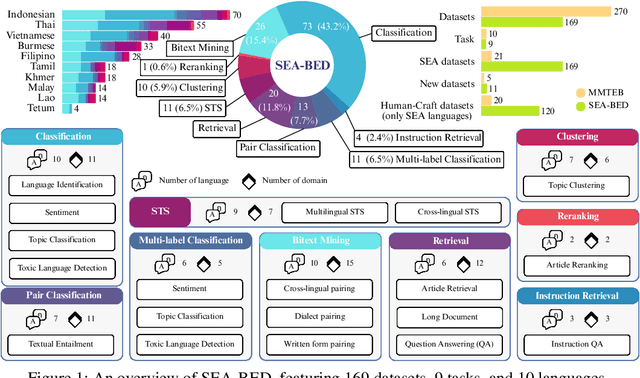


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.
Small or Large? Zero-Shot or Finetuned? Guiding Language Model Choice for Specialized Applications in Healthcare
Apr 29, 2025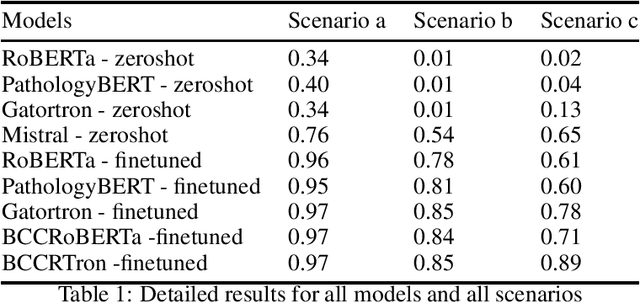
This study aims to guide language model selection by investigating: 1) the necessity of finetuning versus zero-shot usage, 2) the benefits of domain-adjacent versus generic pretrained models, 3) the value of further domain-specific pretraining, and 4) the continued relevance of Small Language Models (SLMs) compared to Large Language Models (LLMs) for specific tasks. Using electronic pathology reports from the British Columbia Cancer Registry (BCCR), three classification scenarios with varying difficulty and data size are evaluated. Models include various SLMs and an LLM. SLMs are evaluated both zero-shot and finetuned; the LLM is evaluated zero-shot only. Finetuning significantly improved SLM performance across all scenarios compared to their zero-shot results. The zero-shot LLM outperformed zero-shot SLMs but was consistently outperformed by finetuned SLMs. Domain-adjacent SLMs generally performed better than the generic SLM after finetuning, especially on harder tasks. Further domain-specific pretraining yielded modest gains on easier tasks but significant improvements on the complex, data-scarce task. The results highlight the critical role of finetuning for SLMs in specialized domains, enabling them to surpass zero-shot LLM performance on targeted classification tasks. Pretraining on domain-adjacent or domain-specific data provides further advantages, particularly for complex problems or limited finetuning data. While LLMs offer strong zero-shot capabilities, their performance on these specific tasks did not match that of appropriately finetuned SLMs. In the era of LLMs, SLMs remain relevant and effective, offering a potentially superior performance-resource trade-off compared to LLMs.
SEA-LION: Southeast Asian Languages in One Network
Apr 08, 2025Recently, Large Language Models (LLMs) have dominated much of the artificial intelligence scene with their ability to process and generate natural languages. However, the majority of LLM research and development remains English-centric, leaving low-resource languages such as those in the Southeast Asian (SEA) region under-represented. To address this representation gap, we introduce Llama-SEA-LION-v3-8B-IT and Gemma-SEA-LION-v3-9B-IT, two cutting-edge multilingual LLMs designed for SEA languages. The SEA-LION family of LLMs supports 11 SEA languages, namely English, Chinese, Indonesian, Vietnamese, Malay, Thai, Burmese, Lao, Filipino, Tamil, and Khmer. Our work leverages large-scale multilingual continued pre-training with a comprehensive post-training regime involving multiple stages of instruction fine-tuning, alignment, and model merging. Evaluation results on multilingual benchmarks indicate that our models achieve state-of-the-art performance across LLMs supporting SEA languages. We open-source the models to benefit the wider SEA community.
Black Swan: Abductive and Defeasible Video Reasoning in Unpredictable Events
Dec 07, 2024



The commonsense reasoning capabilities of vision-language models (VLMs), especially in abductive reasoning and defeasible reasoning, remain poorly understood. Most benchmarks focus on typical visual scenarios, making it difficult to discern whether model performance stems from keen perception and reasoning skills, or reliance on pure statistical recall. We argue that by focusing on atypical events in videos, clearer insights can be gained on the core capabilities of VLMs. Explaining and understanding such out-of-distribution events requires models to extend beyond basic pattern recognition and regurgitation of their prior knowledge. To this end, we introduce BlackSwanSuite, a benchmark for evaluating VLMs' ability to reason about unexpected events through abductive and defeasible tasks. Our tasks artificially limit the amount of visual information provided to models while questioning them about hidden unexpected events, or provide new visual information that could change an existing hypothesis about the event. We curate a comprehensive benchmark suite comprising over 3,800 MCQ, 4,900 generative and 6,700 yes/no tasks, spanning 1,655 videos. After extensively evaluating various state-of-the-art VLMs, including GPT-4o and Gemini 1.5 Pro, as well as open-source VLMs such as LLaVA-Video, we find significant performance gaps of up to 32% from humans on these tasks. Our findings reveal key limitations in current VLMs, emphasizing the need for enhanced model architectures and training strategies.
Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Dec 04, 2024



Cultural biases in multilingual datasets pose significant challenges for their effectiveness as global benchmarks. These biases stem not only from language but also from the cultural knowledge required to interpret questions, reducing the practical utility of translated datasets like MMLU. Furthermore, translation often introduces artifacts that can distort the meaning or clarity of questions in the target language. A common practice in multilingual evaluation is to rely on machine-translated evaluation sets, but simply translating a dataset is insufficient to address these challenges. In this work, we trace the impact of both of these issues on multilingual evaluations and ensuing model performances. Our large-scale evaluation of state-of-the-art open and proprietary models illustrates that progress on MMLU depends heavily on learning Western-centric concepts, with 28% of all questions requiring culturally sensitive knowledge. Moreover, for questions requiring geographic knowledge, an astounding 84.9% focus on either North American or European regions. Rankings of model evaluations change depending on whether they are evaluated on the full portion or the subset of questions annotated as culturally sensitive, showing the distortion to model rankings when blindly relying on translated MMLU. We release Global-MMLU, an improved MMLU with evaluation coverage across 42 languages -- with improved overall quality by engaging with compensated professional and community annotators to verify translation quality while also rigorously evaluating cultural biases present in the original dataset. This comprehensive Global-MMLU set also includes designated subsets labeled as culturally sensitive and culturally agnostic to allow for more holistic, complete evaluation.
COMET-M: Reasoning about Multiple Events in Complex Sentences
May 24, 2023Understanding the speaker's intended meaning often involves drawing commonsense inferences to reason about what is not stated explicitly. In multi-event sentences, it requires understanding the relationships between events based on contextual knowledge. We propose COMET-M (Multi-Event), an event-centric commonsense model capable of generating commonsense inferences for a target event within a complex sentence. COMET-M builds upon COMET (Bosselut et al., 2019), which excels at generating event-centric inferences for simple sentences, but struggles with the complexity of multi-event sentences prevalent in natural text. To overcome this limitation, we curate a multi-event inference dataset of 35K human-written inferences. We trained COMET-M on the human-written inferences and also created baselines using automatically labeled examples. Experimental results demonstrate the significant performance improvement of COMET-M over COMET in generating multi-event inferences. Moreover, COMET-M successfully produces distinct inferences for each target event, taking the complete context into consideration. COMET-M holds promise for downstream tasks involving natural text such as coreference resolution, dialogue, and story understanding.
What happens before and after: Multi-Event Commonsense in Event Coreference Resolution
Feb 21, 2023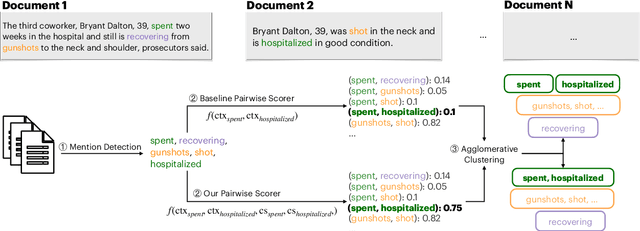
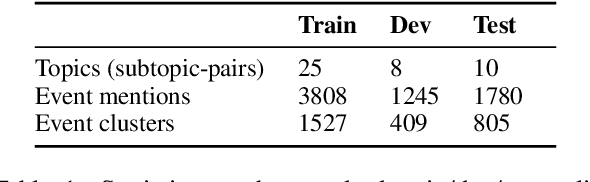

Event coreference models cluster event mentions pertaining to the same real-world event. Recent models rely on contextualized representations to recognize coreference among lexically or contextually similar mentions. However, models typically fail to leverage commonsense inferences, which is particularly limiting for resolving lexically-divergent mentions. We propose a model that extends event mentions with temporal commonsense inferences. Given a complex sentence with multiple events, e.g., "The man killed his wife and got arrested", with the target event "arrested", our model generates plausible events that happen before the target event - such as "the police arrived", and after it, such as "he was sentenced". We show that incorporating such inferences into an existing event coreference model improves its performance, and we analyze the coreferences in which such temporal knowledge is required.
Computational Skills by Stealth in Secondary School Data Science
Oct 08, 2020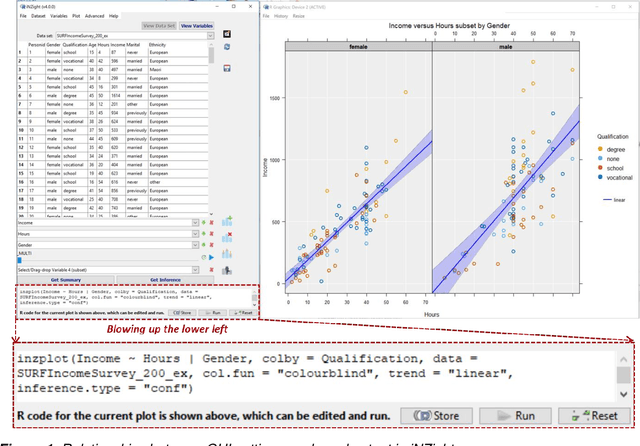
The unprecedented growth in the availability of data of all types and qualities and the emergence of the field of data science has provided an impetus to finally realizing the implementation of the full breadth of the Nolan and Temple Lang proposed integration of computing concepts into statistics curricula at all levels in statistics and new data science programs and courses. Moreover, data science, implemented carefully, opens accessible pathways to stem for students for whom neither mathematics nor computer science are natural affinities, and who would traditionally be excluded. We discuss a proposal for the stealth development of computational skills in students' first exposure to data science through careful, scaffolded exposure to computation and its power. The intent of this approach is to support students, regardless of interest and self-efficacy in coding, in becoming data-driven learners, who are capable of asking complex questions about the world around them, and then answering those questions through the use of data-driven inquiry. This discussion is presented in the context of the International Data Science in Schools Project which recently published computer science and statistics consensus curriculum frameworks for a two-year secondary school data science program, designed to make data science accessible to all.
Dense Forecasting of Wildfire Smoke Particulate Matter Using Sparsity Invariant Convolutional Neural Networks
Sep 23, 2020
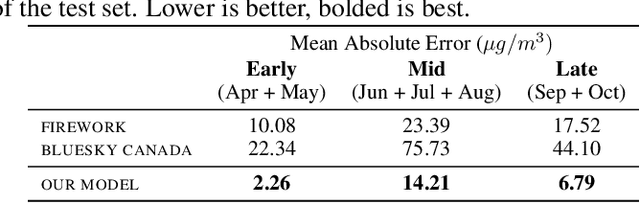
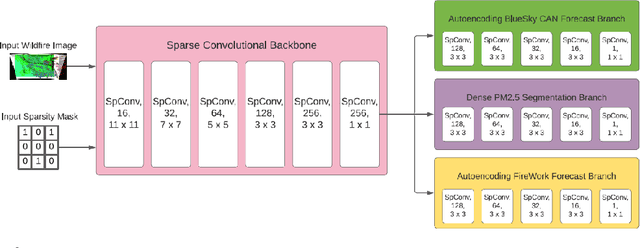
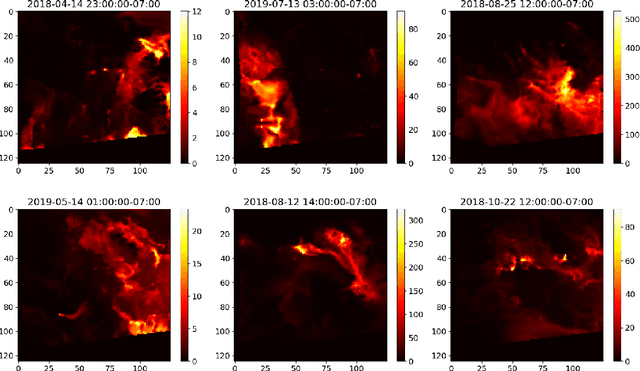
Accurate forecasts of fine particulate matter (PM 2.5) from wildfire smoke are crucial to safeguarding cardiopulmonary public health. Existing forecasting systems are trained on sparse and inaccurate ground truths, and do not take sufficient advantage of important spatial inductive biases. In this work, we present a convolutional neural network which preserves sparsity invariance throughout, and leverages multitask learning to perform dense forecasts of PM 2.5values. We demonstrate that our model outperforms two existing smoke forecasting systems during the 2018 and 2019 wildfire season in British Columbia, Canada, predicting PM 2.5 at a grid resolution of 10 km, 24 hours in advance with high fidelity. Most interestingly, our model also generalizes to meaningful smoke dispersion patterns despite training with irregularly distributed ground truth PM 2.5 values available in only 0.5% of grid cells.