 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-Guard: Culturally Grounded Multilingual Safeguard for Southeast Asia
Feb 02, 2026Culturally aware safeguards are crucial for AI alignment in real-world settings, where safety extends beyond common sense and encompasses diverse local values, norms, and region-specific regulations. However, building large-scale, culturally grounded datasets is challenging due to limited resources and a scarcity of native annotators. Consequently, many safeguard models rely on machine translation of English datasets, often missing regional and cultural nuances. We present a novel agentic data-generation framework to scalably create authentic, region-specific safety datasets for Southeast Asia (SEA). On this foundation, we introduce the SEA-Guard family, the first multilingual safeguard models grounded in SEA cultural contexts. Evaluated across multiple benchmarks and cultural variants, SEA-Guard consistently outperforms existing safeguards at detecting regionally sensitive or harmful content while maintaining strong general safety performance.
MultiLexNorm++: A Unified Benchmark and a Generative Model for Lexical Normalization for Asian Languages
Jan 23, 2026Social media data has been of interest to Natural Language Processing (NLP) practitioners for over a decade, because of its richness in information, but also challenges for automatic processing. Since language use is more informal, spontaneous, and adheres to many different sociolects, the performance of NLP models often deteriorates. One solution to this problem is to transform data to a standard variant before processing it, which is also called lexical normalization. There has been a wide variety of benchmarks and models proposed for this task. The MultiLexNorm benchmark proposed to unify these efforts, but it consists almost solely of languages from the Indo-European language family in the Latin script. Hence, we propose an extension to MultiLexNorm, which covers 5 Asian languages from different language families in 4 different scripts. We show that the previous state-of-the-art model performs worse on the new languages and propose a new architecture based on Large Language Models (LLMs), which shows more robust performance. Finally, we analyze remaining errors, revealing future directions for this task.
Distilling Multilingual Vision-Language Models: When Smaller Models Stay Multilingual
Oct 30, 2025Vision-language models (VLMs) exhibit uneven performance across languages, a problem that is often exacerbated when the model size is reduced. While Knowledge distillation (KD) demonstrates promising results in transferring knowledge from larger to smaller VLMs, applying KD in multilingualism is an underexplored area. This paper presents a controlled empirical study of KD behavior across five distillation approaches, isolating their effects on cross-lingual representation consistency and downstream performance stability under model compression. We study five distillation formulations across CLIP and SigLIP2, and evaluate them on in-domain retrieval and out-of-domain visual QA. We find that some configurations preserve or even improve multilingual retrieval robustness despite halving model size, but others fail to maintain cross-task stability, exposing design-sensitive trade-offs that aggregate accuracy alone does not reveal.
WangchanThaiInstruct: An instruction-following Dataset for Culture-Aware, Multitask, and Multi-domain Evaluation in Thai
Aug 21, 2025Large language models excel at instruction-following in English, but their performance in low-resource languages like Thai remains underexplored. Existing benchmarks often rely on translations, missing cultural and domain-specific nuances needed for real-world use. We present WangchanThaiInstruct, a human-authored Thai dataset for evaluation and instruction tuning, covering four professional domains and seven task types. Created through a multi-stage quality control process with annotators, domain experts, and AI researchers, WangchanThaiInstruct supports two studies: (1) a zero-shot evaluation showing performance gaps on culturally and professionally specific tasks, and (2) an instruction tuning study with ablations isolating the effect of native supervision. Models fine-tuned on WangchanThaiInstruct outperform those using translated data in both in-domain and out-of-domain benchmarks. These findings underscore the need for culturally and professionally grounded instruction data to improve LLM alignment in low-resource, linguistically diverse settings.
SEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
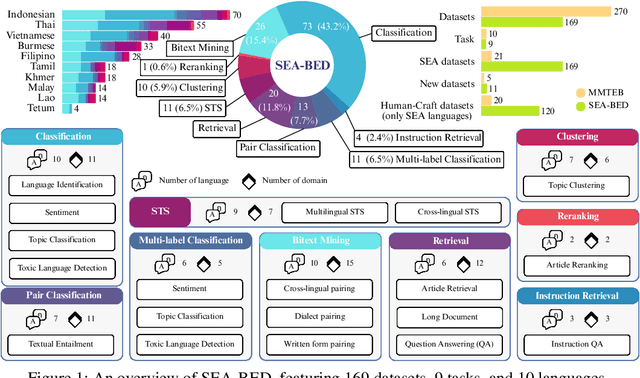


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.
SEADialogues: A Multilingual Culturally Grounded Multi-turn Dialogue Dataset on Southeast Asian Languages
Aug 09, 2025Although numerous datasets have been developed to support dialogue systems, most existing chit-chat datasets overlook the cultural nuances inherent in natural human conversations. To address this gap, we introduce SEADialogues, a culturally grounded dialogue dataset centered on Southeast Asia, a region with over 700 million people and immense cultural diversity. Our dataset features dialogues in eight languages from six Southeast Asian countries, many of which are low-resource despite having sizable speaker populations. To enhance cultural relevance and personalization, each dialogue includes persona attributes and two culturally grounded topics that reflect everyday life in the respective communities. Furthermore, we release a multi-turn dialogue dataset to advance research on culturally aware and human-centric large language models, including conversational dialogue agents.
Language Surgery in Multilingual Large Language Models
Jun 14, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across tasks and languages, revolutionizing natural language processing. This paper investigates the naturally emerging representation alignment in LLMs, particularly in the middle layers, and its implications for disentangling language-specific and language-agnostic information. We empirically confirm the existence of this alignment, analyze its behavior in comparison to explicitly designed alignment models, and demonstrate its potential for language-specific manipulation without semantic degradation. Building on these findings, we propose Inference-Time Language Control (ITLC), a novel method that leverages latent injection to enable precise cross-lingual language control and mitigate language confusion in LLMs. Our experiments highlight ITLC's strong cross-lingual control capabilities while preserving semantic integrity in target languages. Furthermore, we demonstrate its effectiveness in alleviating the cross-lingual language confusion problem, which persists even in current large-scale LLMs, leading to inconsistent language generation. This work advances our understanding of representation alignment in LLMs and introduces a practical solution for enhancing their cross-lingual performance.
Decom-Renorm-Merge: Model Merging on the Right Space Improves Multitasking
May 29, 2025In the era of large-scale training, model merging has evolved into a tool for creating multitasking models efficiently. It enables the knowledge of models to be fused, without the need for heavy computation as required in traditional multitask learning. Existing merging methods often assume that entries at identical positions in weight matrices serve the same function, enabling straightforward entry-wise comparison and merging. However, this assumption overlooks the complexity of finetuned neural networks, where neurons may develop distinct feature compositions, making direct entry-wise merging problematic. We present Decom-Renorm-Merge (DRM), a simple yet effective approach that leverages Singular Value Decomposition to decompose and coordinate weight matrices into an aligned joint space, where entry-wise merging becomes possible. We showcase the effectiveness of DRM across various settings ranging from smaller encoder-based such as ViT and DeBERTa, encoder-decoder-based such as T5, and larger decoder-based such as Llama3.1-8B. Our experimental results show that DRM outperforms several state-of-the-art merging techniques across full finetuning and low-rank adaptation settings. Moreover, our analysis reveals renormalization as the crucial component for creating a robust and even joint space for merging, significantly contributing to the method's performance.
Assessing Thai Dialect Performance in LLMs with Automatic Benchmarks and Human Evaluation
Apr 08, 2025



Large language models show promising results in various NLP tasks. Despite these successes, the robustness and consistency of LLMs in underrepresented languages remain largely unexplored, especially concerning local dialects. Existing benchmarks also focus on main dialects, neglecting LLMs' ability on local dialect texts. In this paper, we introduce a Thai local dialect benchmark covering Northern (Lanna), Northeastern (Isan), and Southern (Dambro) Thai, evaluating LLMs on five NLP tasks: summarization, question answering, translation, conversation, and food-related tasks. Furthermore, we propose a human evaluation guideline and metric for Thai local dialects to assess generation fluency and dialect-specific accuracy. Results show that LLM performance declines significantly in local Thai dialects compared to standard Thai, with only proprietary models like GPT-4o and Gemini2 demonstrating some fluency
SEA-LION: Southeast Asian Languages in One Network
Apr 08, 2025Recently, Large Language Models (LLMs) have dominated much of the artificial intelligence scene with their ability to process and generate natural languages. However, the majority of LLM research and development remains English-centric, leaving low-resource languages such as those in the Southeast Asian (SEA) region under-represented. To address this representation gap, we introduce Llama-SEA-LION-v3-8B-IT and Gemma-SEA-LION-v3-9B-IT, two cutting-edge multilingual LLMs designed for SEA languages. The SEA-LION family of LLMs supports 11 SEA languages, namely English, Chinese, Indonesian, Vietnamese, Malay, Thai, Burmese, Lao, Filipino, Tamil, and Khmer. Our work leverages large-scale multilingual continued pre-training with a comprehensive post-training regime involving multiple stages of instruction fine-tuning, alignment, and model merging. Evaluation results on multilingual benchmarks indicate that our models achieve state-of-the-art performance across LLMs supporting SEA languages. We open-source the models to benefit the wider SEA community.