 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan General-Purpose Large Language Models Generalize to English-Thai Machine Translation ?
Oct 22, 2024


Large language models (LLMs) perform well on common tasks but struggle with generalization in low-resource and low-computation settings. We examine this limitation by testing various LLMs and specialized translation models on English-Thai machine translation and code-switching datasets. Our findings reveal that under more strict computational constraints, such as 4-bit quantization, LLMs fail to translate effectively. In contrast, specialized models, with comparable or lower computational requirements, consistently outperform LLMs. This underscores the importance of specialized models for maintaining performance under resource constraints.
On Creating an English-Thai Code-switched Machine Translation in Medical Domain
Oct 21, 2024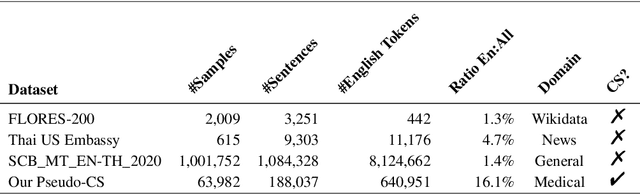

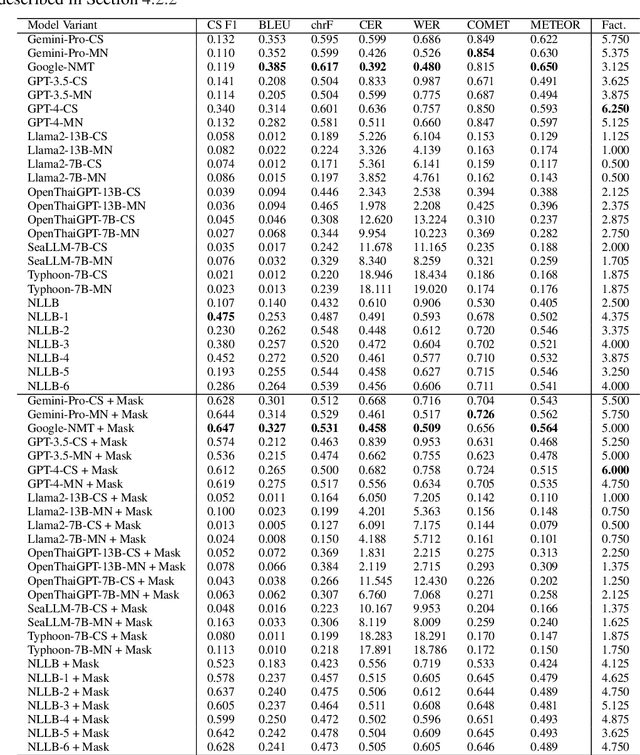
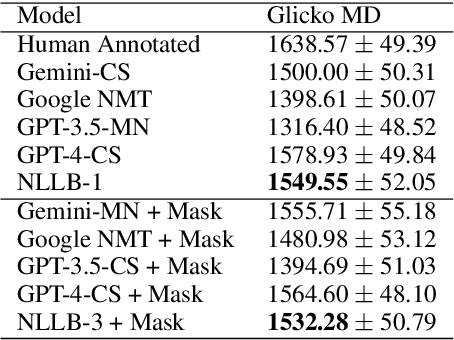
Machine translation (MT) in the medical domain plays a pivotal role in enhancing healthcare quality and disseminating medical knowledge. Despite advancements in English-Thai MT technology, common MT approaches often underperform in the medical field due to their inability to precisely translate medical terminologies. Our research prioritizes not merely improving translation accuracy but also maintaining medical terminology in English within the translated text through code-switched (CS) translation. We developed a method to produce CS medical translation data, fine-tuned a CS translation model with this data, and evaluated its performance against strong baselines, such as Google Neural Machine Translation (NMT) and GPT-3.5/GPT-4. Our model demonstrated competitive performance in automatic metrics and was highly favored in human preference evaluations. Our evaluation result also shows that medical professionals significantly prefer CS translations that maintain critical English terms accurately, even if it slightly compromises fluency. Our code and test set are publicly available https://github.com/preceptorai-org/NLLB_CS_EM_NLP2024.