 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyphoon 2: A Family of Open Text and Multimodal Thai Large Language Models
Dec 19, 2024



This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ post-training techniques to enhance Thai language performance while preserving the base models' original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. To guardrail text generation, we release Typhoon2-Safety, a classifier enhanced for Thai cultures and language. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs.
Seed-Free Synthetic Data Generation Framework for Instruction-Tuning LLMs: A Case Study in Thai
Nov 23, 2024We present a synthetic data approach for instruction-tuning large language models (LLMs) for low-resource languages in a data-efficient manner, specifically focusing on Thai. We identify three key properties that contribute to the effectiveness of instruction-tuning datasets: fluency, diversity, and cultural context. We propose a seed-data-free framework for generating synthetic instruction-tuning data that incorporates these essential properties. Our framework employs an LLM to generate diverse topics, retrieve relevant contexts from Wikipedia, and create instructions for various tasks, such as question answering, summarization, and conversation. The experimental results show that our best-performing synthetic dataset, which incorporates all three key properties, achieves competitive performance using only 5,000 instructions when compared to state-of-the-art Thai LLMs trained on hundreds of thousands of instructions. Our code and dataset are publicly available at https://github.com/parinzee/seed-free-synthetic-instruct.
Can General-Purpose Large Language Models Generalize to English-Thai Machine Translation ?
Oct 22, 2024


Large language models (LLMs) perform well on common tasks but struggle with generalization in low-resource and low-computation settings. We examine this limitation by testing various LLMs and specialized translation models on English-Thai machine translation and code-switching datasets. Our findings reveal that under more strict computational constraints, such as 4-bit quantization, LLMs fail to translate effectively. In contrast, specialized models, with comparable or lower computational requirements, consistently outperform LLMs. This underscores the importance of specialized models for maintaining performance under resource constraints.
On Creating an English-Thai Code-switched Machine Translation in Medical Domain
Oct 21, 2024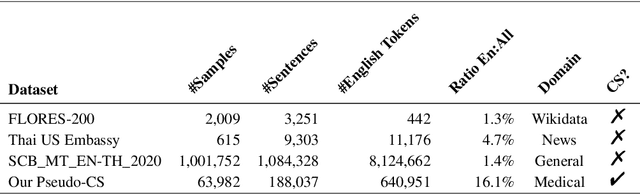

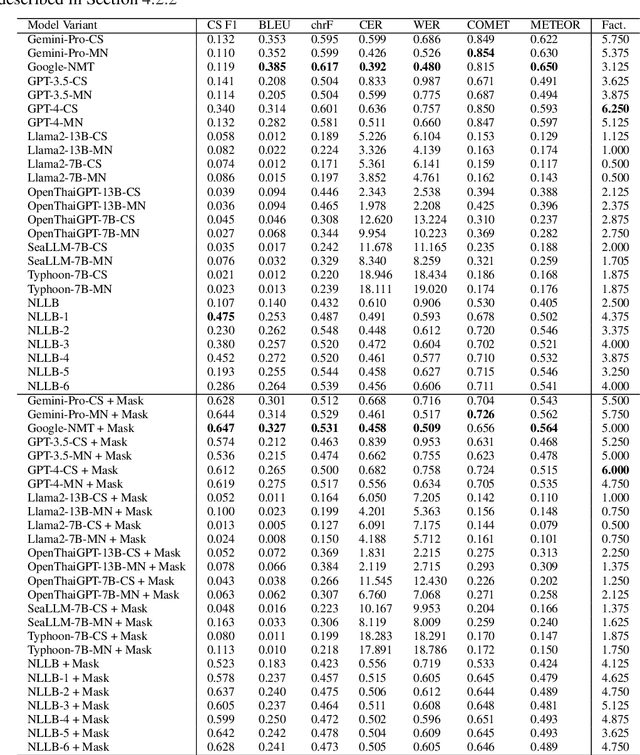
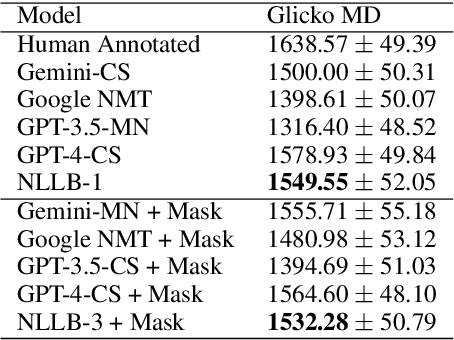
Machine translation (MT) in the medical domain plays a pivotal role in enhancing healthcare quality and disseminating medical knowledge. Despite advancements in English-Thai MT technology, common MT approaches often underperform in the medical field due to their inability to precisely translate medical terminologies. Our research prioritizes not merely improving translation accuracy but also maintaining medical terminology in English within the translated text through code-switched (CS) translation. We developed a method to produce CS medical translation data, fine-tuned a CS translation model with this data, and evaluated its performance against strong baselines, such as Google Neural Machine Translation (NMT) and GPT-3.5/GPT-4. Our model demonstrated competitive performance in automatic metrics and was highly favored in human preference evaluations. Our evaluation result also shows that medical professionals significantly prefer CS translations that maintain critical English terms accurately, even if it slightly compromises fluency. Our code and test set are publicly available https://github.com/preceptorai-org/NLLB_CS_EM_NLP2024.