 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormula-One Prompting: Adaptive Reasoning Through Equations For Applied Mathematics
Jan 27, 2026Prompting techniques such as Chain-of-Thought (CoT) and Program-of-Thought (PoT) improve LLM mathematical reasoning by structuring intermediate steps in natural language or code. However, applied mathematics problems in domains like finance, physics, and cryptography often require recalling or deriving governing equations, a step that current approaches do not explicitly leverage. We propose Formula-One Prompting (F-1), a two-phase approach that uses mathematical equations as an intermediate representation before adaptive solving. F-1 first formulates governing equations from problem descriptions, then selects a solving strategy among CoT, PoT, or direct computation based on the generated equations, all within a single LLM call. Results across five models and four benchmarks show F-1 outperforms CoT by +5.76% and PoT by +8.42% on average. Crucially, gains are largest in applied domains: +13.30% on FinanceMath over CoT, and within OlympiadBench, larger gains on physics (+2.55%) than pure math (+0.44%). This demonstrates that F-1 is more effective than CoT in applied mathematics problems.
Typhoon-S: Minimal Open Post-Training for Sovereign Large Language Models
Jan 26, 2026Large language models (LLMs) have progressed rapidly; however, most state-of-the-art models are trained and evaluated primarily in high-resource languages such as English and Chinese, and are often developed by a small number of organizations with access to large-scale compute and data. This gatekeeping creates a practical barrier for sovereign settings in which a regional- or national-scale institution or domain owner must retain control and understanding of model weights, training data, and deployment while operating under limited resources and strict transparency constraints. To this end, we identify two core requirements: (1) adoptability, the ability to transform a base model into a general-purpose assistant, and (2) sovereign capability, the ability to perform high-stakes, region-specific tasks (e.g., legal reasoning in local languages and cultural knowledge). We investigate whether these requirements can be achieved without scaling massive instruction corpora or relying on complex preference tuning pipelines and large-scale reinforcement fine-tuning (RFT). We present Typhoon S, a minimal and open post-training recipe that combines supervised fine-tuning, on-policy distillation, and small-scale RFT. Using Thai as a representative case study, we demonstrate that our approach transforms both sovereign-adapted and general-purpose base models into instruction-tuned models with strong general performance. We further show that small-scale RFT with InK-GRPO -- an extension of GRPO that augments the GRPO loss with a next-word prediction loss -- improves Thai legal reasoning and Thai-specific knowledge while preserving general capabilities. Our results suggest that a carefully designed post-training strategy can reduce the required scale of instruction data and computation, providing a practical path toward high-quality sovereign LLMs under academic-scale resources.
Typhoon OCR: Open Vision-Language Model For Thai Document Extraction
Jan 21, 2026Document extraction is a core component of digital workflows, yet existing vision-language models (VLMs) predominantly favor high-resource languages. Thai presents additional challenges due to script complexity from non-latin letters, the absence of explicit word boundaries, and the prevalence of highly unstructured real-world documents, limiting the effectiveness of current open-source models. This paper presents Typhoon OCR, an open VLM for document extraction tailored for Thai and English. The model is fine-tuned from vision-language backbones using a Thai-focused training dataset. The dataset is developed using a multi-stage data construction pipeline that combines traditional OCR, VLM-based restructuring, and curated synthetic data. Typhoon OCR is a unified framework capable of text transcription, layout reconstruction, and document-level structural consistency. The latest iteration of our model, Typhoon OCR V1.5, is a compact and inference-efficient model designed to reduce reliance on metadata and simplify deployment. Comprehensive evaluations across diverse Thai document categories, including financial reports, government forms, books, infographics, and handwritten documents, show that Typhoon OCR achieves performance comparable to or exceeding larger frontier proprietary models, despite substantially lower computational cost. The results demonstrate that open vision-language OCR models can achieve accurate text extraction and layout reconstruction for Thai documents, reaching performance comparable to proprietary systems while remaining lightweight and deployable.
Typhoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition
Jan 19, 2026Large encoder-decoder models like Whisper achieve strong offline transcription but remain impractical for streaming applications due to high latency. However, due to the accessibility of pre-trained checkpoints, the open Thai ASR landscape remains dominated by these offline architectures, leaving a critical gap in efficient streaming solutions. We present Typhoon ASR Real-time, a 115M-parameter FastConformer-Transducer model for low-latency Thai speech recognition. We demonstrate that rigorous text normalization can match the impact of model scaling: our compact model achieves a 45x reduction in computational cost compared to Whisper Large-v3 while delivering comparable accuracy. Our normalization pipeline resolves systemic ambiguities in Thai transcription --including context-dependent number verbalization and repetition markers (mai yamok) --creating consistent training targets. We further introduce a two-stage curriculum learning approach for Isan (north-eastern) dialect adaptation that preserves Central Thai performance. To address reproducibility challenges in Thai ASR, we release the Typhoon ASR Benchmark, a gold-standard human-labeled datasets with transcriptions following established Thai linguistic conventions, providing standardized evaluation protocols for the research community.
ThaiOCRBench: A Task-Diverse Benchmark for Vision-Language Understanding in Thai
Nov 06, 2025We present ThaiOCRBench, the first comprehensive benchmark for evaluating vision-language models (VLMs) on Thai text-rich visual understanding tasks. Despite recent progress in multimodal modeling, existing benchmarks predominantly focus on high-resource languages, leaving Thai underrepresented, especially in tasks requiring document structure understanding. ThaiOCRBench addresses this gap by offering a diverse, human-annotated dataset comprising 2,808 samples across 13 task categories. We evaluate a wide range of state-of-the-art VLMs in a zero-shot setting, spanning both proprietary and open-source systems. Results show a significant performance gap, with proprietary models (e.g., Gemini 2.5 Pro) outperforming open-source counterparts. Notably, fine-grained text recognition and handwritten content extraction exhibit the steepest performance drops among open-source models. Through detailed error analysis, we identify key challenges such as language bias, structural mismatch, and hallucinated content. ThaiOCRBench provides a standardized framework for assessing VLMs in low-resource, script-complex settings, and provides actionable insights for improving Thai-language document understanding.
Prior Prompt Engineering for Reinforcement Fine-Tuning
May 20, 2025This paper investigates prior prompt engineering (pPE) in the context of reinforcement fine-tuning (RFT), where language models (LMs) are incentivized to exhibit behaviors that maximize performance through reward signals. While existing RFT research has primarily focused on algorithms, reward shaping, and data curation, the design of the prior prompt--the instructions prepended to queries during training to elicit behaviors such as step-by-step reasoning--remains underexplored. We investigate whether different pPE approaches can guide LMs to internalize distinct behaviors after RFT. Inspired by inference-time prompt engineering (iPE), we translate five representative iPE strategies--reasoning, planning, code-based reasoning, knowledge recall, and null-example utilization--into corresponding pPE approaches. We experiment with Qwen2.5-7B using each of the pPE approaches, then evaluate performance on in-domain and out-of-domain benchmarks (e.g., AIME2024, HumanEval+, and GPQA-Diamond). Our results show that all pPE-trained models surpass their iPE-prompted counterparts, with the null-example pPE approach achieving the largest average performance gain and the highest improvement on AIME2024 and GPQA-Diamond, surpassing the commonly used reasoning approach. Furthermore, by adapting a behavior-classification framework, we demonstrate that different pPE strategies instill distinct behavioral styles in the resulting models. These findings position pPE as a powerful yet understudied axis for RFT.
Mind the Gap! Static and Interactive Evaluations of Large Audio Models
Feb 21, 2025As AI chatbots become ubiquitous, voice interaction presents a compelling way to enable rapid, high-bandwidth communication for both semantic and social signals. This has driven research into Large Audio Models (LAMs) to power voice-native experiences. However, aligning LAM development with user goals requires a clear understanding of user needs and preferences to establish reliable progress metrics. This study addresses these challenges by introducing an interactive approach to evaluate LAMs and collecting 7,500 LAM interactions from 484 participants. Through topic modeling of user queries, we identify primary use cases for audio interfaces. We then analyze user preference rankings and qualitative feedback to determine which models best align with user needs. Finally, we evaluate how static benchmarks predict interactive performance - our analysis reveals no individual benchmark strongly correlates with interactive results ($\tau \leq 0.33$ for all benchmarks). While combining multiple coarse-grained features yields modest predictive power ($R^2$=$0.30$), only two out of twenty datasets on spoken question answering and age prediction show significantly positive correlations. This suggests a clear need to develop LAM evaluations that better correlate with user preferences.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025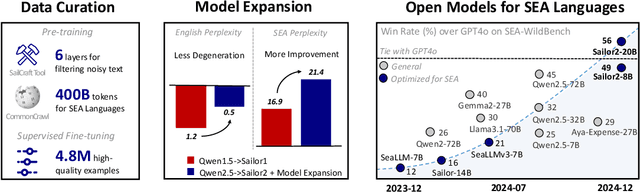

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
An Open Recipe: Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging
Feb 13, 2025This paper investigates data selection and model merging methodologies aimed at incorporating advanced reasoning capabilities such as those of DeepSeek R1 into language-specific large language models (LLMs), with a particular focus on the Thai LLM. Our goal is to enhance the reasoning capabilities of language-specific LLMs while maintaining their target language abilities. DeepSeek R1 excels in reasoning but primarily benefits high-resource languages such as English and Chinese. However, low-resource languages remain underserved due to the dominance of English-centric training data and model optimizations, which limit performance in these languages. This limitation results in unreliable code-switching and diminished effectiveness on tasks in low-resource languages. Meanwhile, local and regional LLM initiatives have attempted to bridge this gap by developing language-specific LLMs that focus on improving local linguistic fidelity. We demonstrate that, with only publicly available datasets and a computational budget of $120, it is possible to enhance the reasoning capabilities of language-specific LLMs to match the level of DeepSeek R1, without compromising their performance on target language tasks.
Typhoon T1: An Open Thai Reasoning Model
Feb 13, 2025This paper introduces Typhoon T1, an open effort to develop an open Thai reasoning model. A reasoning model is a relatively new type of generative model built on top of large language models (LLMs). A reasoning model generates a long chain of thought before arriving at a final answer, an approach found to improve performance on complex tasks. However, details on developing such a model are limited, especially for reasoning models that can generate traces in a low-resource language. Typhoon T1 presents an open effort that dives into the details of developing a reasoning model in a more cost-effective way by leveraging supervised fine-tuning using open datasets, instead of reinforcement learning. This paper shares the details about synthetic data generation and training, as well as our dataset and model weights. Additionally, we provide insights gained from developing a reasoning model that generalizes across domains and is capable of generating reasoning traces in a low-resource language, using Thai as an example. We hope this open effort provides a foundation for further research in this field.