 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyphoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition
Jan 19, 2026Large encoder-decoder models like Whisper achieve strong offline transcription but remain impractical for streaming applications due to high latency. However, due to the accessibility of pre-trained checkpoints, the open Thai ASR landscape remains dominated by these offline architectures, leaving a critical gap in efficient streaming solutions. We present Typhoon ASR Real-time, a 115M-parameter FastConformer-Transducer model for low-latency Thai speech recognition. We demonstrate that rigorous text normalization can match the impact of model scaling: our compact model achieves a 45x reduction in computational cost compared to Whisper Large-v3 while delivering comparable accuracy. Our normalization pipeline resolves systemic ambiguities in Thai transcription --including context-dependent number verbalization and repetition markers (mai yamok) --creating consistent training targets. We further introduce a two-stage curriculum learning approach for Isan (north-eastern) dialect adaptation that preserves Central Thai performance. To address reproducibility challenges in Thai ASR, we release the Typhoon ASR Benchmark, a gold-standard human-labeled datasets with transcriptions following established Thai linguistic conventions, providing standardized evaluation protocols for the research community.
ThaiOCRBench: A Task-Diverse Benchmark for Vision-Language Understanding in Thai
Nov 06, 2025We present ThaiOCRBench, the first comprehensive benchmark for evaluating vision-language models (VLMs) on Thai text-rich visual understanding tasks. Despite recent progress in multimodal modeling, existing benchmarks predominantly focus on high-resource languages, leaving Thai underrepresented, especially in tasks requiring document structure understanding. ThaiOCRBench addresses this gap by offering a diverse, human-annotated dataset comprising 2,808 samples across 13 task categories. We evaluate a wide range of state-of-the-art VLMs in a zero-shot setting, spanning both proprietary and open-source systems. Results show a significant performance gap, with proprietary models (e.g., Gemini 2.5 Pro) outperforming open-source counterparts. Notably, fine-grained text recognition and handwritten content extraction exhibit the steepest performance drops among open-source models. Through detailed error analysis, we identify key challenges such as language bias, structural mismatch, and hallucinated content. ThaiOCRBench provides a standardized framework for assessing VLMs in low-resource, script-complex settings, and provides actionable insights for improving Thai-language document understanding.
Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models
Dec 19, 2024



This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ post-training techniques to enhance Thai language performance while preserving the base models' original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. To guardrail text generation, we release Typhoon2-Safety, a classifier enhanced for Thai cultures and language. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs.
Enhancing Low-Resource Language and Instruction Following Capabilities of Audio Language Models
Sep 17, 2024



Audio language models can understand audio inputs and perform a range of audio-related tasks based on instructions, such as speech recognition and audio captioning, where the instructions are usually textual prompts. Audio language models are mostly initialized from pre-trained audio encoders and large language models (LLMs). Although these pre-trained components were developed to support multiple languages, audio-language models are trained predominantly on English data, which may limit their usability to only English instructions or English speech inputs. First, this paper examines the performance of existing audio language models in an underserved language using Thai as an example. This paper demonstrates that, despite being built on multilingual backbones, audio language models do not exhibit cross-lingual emergent abilities to low-resource languages. Second, this paper studies data mixture for developing audio language models that are optimized for a target language as well as English. In addition. this paper integrates audio comprehension and speech instruction-following capabilities into a single unified model. Our experiments provide insights into data mixture for enhancing instruction-following capabilities in both a low-resource language and English. Our model, Typhoon-Audio, outperforms existing open-source audio language models by a considerable margin, and it is comparable to state-of-the-art Gemini-1.5-Pro in both English and Thai languages.
Adversarial Test on Learnable Image Encryption
Jul 31, 2019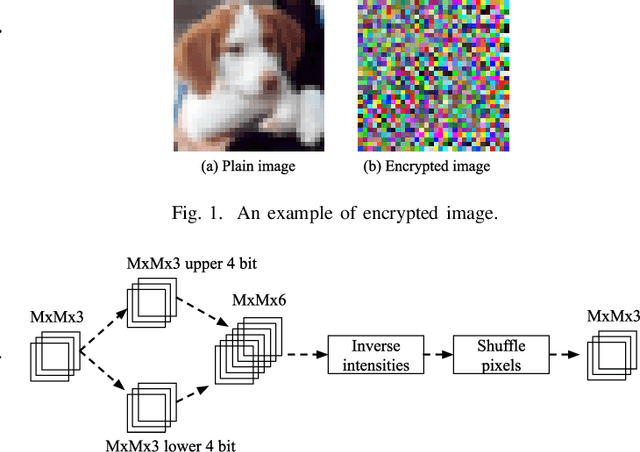
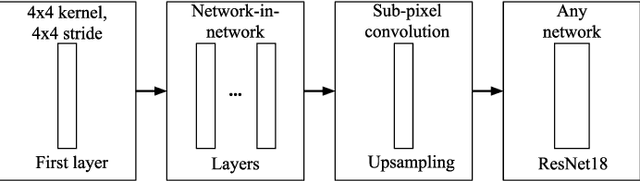
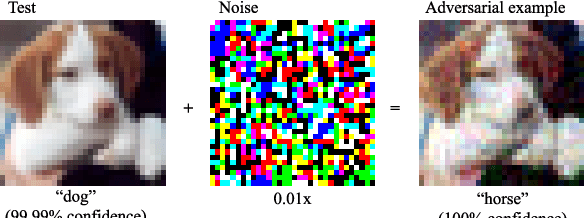

Data for deep learning should be protected for privacy preserving. Researchers have come up with the notion of learnable image encryption to satisfy the requirement. However, existing privacy preserving approaches have never considered the threat of adversarial attacks. In this paper, we ran an adversarial test on learnable image encryption in five different scenarios. The results show different behaviors of the network in the variable key scenarios and suggest learnable image encryption provides certain level of adversarial robustness.