 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFE-PPAR: Compression-friendly encryption for privacy-preserving action recognition leveraging video transformers
May 07, 2026Privacy-preserving action recognition (PPAR) enables machines to understand human activities in videos without revealing sensitive visual content. Among the various strategies for PPAR, encryption-based methods achieve strong privacy protection while maintaining high recognition performance. However, these methods lead to a catastrophic decrease in recognition performance and visual quality when the encrypted videos are compressed. That is, the previous methods are not compression-friendly. To address these issues, in this paper, we propose the first compression-friendly encryption method for PPAR, called CFE-PPAR. In CFE-PPAR, videos encrypted with secret keys can be directly recognized by a video transformer, which uses parameters transformed by the same keys as those used for video encryption. In experiments, it is verified that CFE-PPAR outperforms previous methods on the UCF101 and HMDB51 datasets under Motion-JPEG and H.264 compression.
Effective Fine-Tuning of Vision Transformers with Low-Rank Adaptation for Privacy-Preserving Image Classification
Jul 16, 2025We propose a low-rank adaptation method for training privacy-preserving vision transformer (ViT) models that efficiently freezes pre-trained ViT model weights. In the proposed method, trainable rank decomposition matrices are injected into each layer of the ViT architecture, and moreover, the patch embedding layer is not frozen, unlike in the case of the conventional low-rank adaptation methods. The proposed method allows us not only to reduce the number of trainable parameters but to also maintain almost the same accuracy as that of full-time tuning.
Privacy-Preserving Vision Transformer Using Images Encrypted with Restricted Random Permutation Matrices
Aug 16, 2024



We propose a novel method for privacy-preserving fine-tuning vision transformers (ViTs) with encrypted images. Conventional methods using encrypted images degrade model performance compared with that of using plain images due to the influence of image encryption. In contrast, the proposed encryption method using restricted random permutation matrices can provide a higher performance than the conventional ones.
Speech privacy-preserving methods using secret key for convolutional neural network models and their robustness evaluation
Aug 07, 2024In this paper, we propose privacy-preserving methods with a secret key for convolutional neural network (CNN)-based models in speech processing tasks. In environments where untrusted third parties, like cloud servers, provide CNN-based systems, ensuring the privacy of speech queries becomes essential. This paper proposes encryption methods for speech queries using secret keys and a model structure that allows for encrypted queries to be accepted without decryption. Our approach introduces three types of secret keys: Shuffling, Flipping, and random orthogonal matrix (ROM). In experiments, we demonstrate that when the proposed methods are used with the correct key, identification performance did not degrade. Conversely, when an incorrect key is used, the performance significantly decreased. Particularly, with the use of ROM, we show that even with a relatively small key space, high privacy-preserving performance can be maintained many speech processing tasks. Furthermore, we also demonstrate the difficulty of recovering original speech from encrypted queries in various robustness evaluations.
Fine-Tuning Text-To-Image Diffusion Models for Class-Wise Spurious Feature Generation
Feb 13, 2024We propose a method for generating spurious features by leveraging large-scale text-to-image diffusion models. Although the previous work detects spurious features in a large-scale dataset like ImageNet and introduces Spurious ImageNet, we found that not all spurious images are spurious across different classifiers. Although spurious images help measure the reliance of a classifier, filtering many images from the Internet to find more spurious features is time-consuming. To this end, we utilize an existing approach of personalizing large-scale text-to-image diffusion models with available discovered spurious images and propose a new spurious feature similarity loss based on neural features of an adversarially robust model. Precisely, we fine-tune Stable Diffusion with several reference images from Spurious ImageNet with a modified objective incorporating the proposed spurious-feature similarity loss. Experiment results show that our method can generate spurious images that are consistently spurious across different classifiers. Moreover, the generated spurious images are visually similar to reference images from Spurious ImageNet.
A Random Ensemble of Encrypted Vision Transformers for Adversarially Robust Defense
Feb 11, 2024Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In previous studies, the use of models encrypted with a secret key was demonstrated to be robust against white-box attacks, but not against black-box ones. In this paper, we propose a novel method using the vision transformer (ViT) that is a random ensemble of encrypted models for enhancing robustness against both white-box and black-box attacks. In addition, a benchmark attack method, called AutoAttack, is applied to models to test adversarial robustness objectively. In experiments, the method was demonstrated to be robust against not only white-box attacks but also black-box ones in an image classification task on the CIFAR-10 and ImageNet datasets. The method was also compared with the state-of-the-art in a standardized benchmark for adversarial robustness, RobustBench, and it was verified to outperform conventional defenses in terms of clean accuracy and robust accuracy.
Efficient Fine-Tuning with Domain Adaptation for Privacy-Preserving Vision Transformer
Jan 10, 2024



We propose a novel method for privacy-preserving deep neural networks (DNNs) with the Vision Transformer (ViT). The method allows us not only to train models and test with visually protected images but to also avoid the performance degradation caused from the use of encrypted images, whereas conventional methods cannot avoid the influence of image encryption. A domain adaptation method is used to efficiently fine-tune ViT with encrypted images. In experiments, the method is demonstrated to outperform conventional methods in an image classification task on the CIFAR-10 and ImageNet datasets in terms of classification accuracy.
A Random Ensemble of Encrypted models for Enhancing Robustness against Adversarial Examples
Jan 05, 2024Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In addition, AEs have adversarial transferability, which means AEs generated for a source model can fool another black-box model (target model) with a non-trivial probability. In previous studies, it was confirmed that the vision transformer (ViT) is more robust against the property of adversarial transferability than convolutional neural network (CNN) models such as ConvMixer, and moreover encrypted ViT is more robust than ViT without any encryption. In this article, we propose a random ensemble of encrypted ViT models to achieve much more robust models. In experiments, the proposed scheme is verified to be more robust against not only black-box attacks but also white-box ones than convention methods.
Efficient Key-Based Adversarial Defense for ImageNet by Using Pre-trained Model
Nov 28, 2023
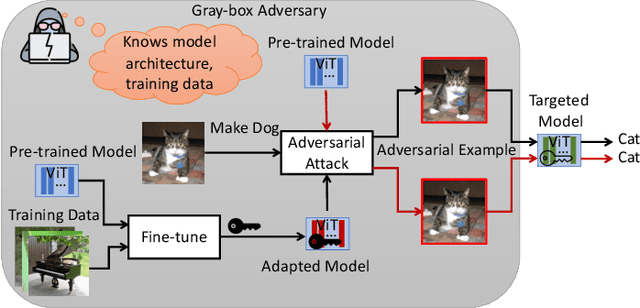


In this paper, we propose key-based defense model proliferation by leveraging pre-trained models and utilizing recent efficient fine-tuning techniques on ImageNet-1k classification. First, we stress that deploying key-based models on edge devices is feasible with the latest model deployment advancements, such as Apple CoreML, although the mainstream enterprise edge artificial intelligence (Edge AI) has been focused on the Cloud. Then, we point out that the previous key-based defense on on-device image classification is impractical for two reasons: (1) training many classifiers from scratch is not feasible, and (2) key-based defenses still need to be thoroughly tested on large datasets like ImageNet. To this end, we propose to leverage pre-trained models and utilize efficient fine-tuning techniques to proliferate key-based models even on limited computing resources. Experiments were carried out on the ImageNet-1k dataset using adaptive and non-adaptive attacks. The results show that our proposed fine-tuned key-based models achieve a superior classification accuracy (more than 10% increase) compared to the previous key-based models on classifying clean and adversarial examples.
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.