 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Fine-Tuning with Domain Adaptation for Privacy-Preserving Vision Transformer
Jan 10, 2024



We propose a novel method for privacy-preserving deep neural networks (DNNs) with the Vision Transformer (ViT). The method allows us not only to train models and test with visually protected images but to also avoid the performance degradation caused from the use of encrypted images, whereas conventional methods cannot avoid the influence of image encryption. A domain adaptation method is used to efficiently fine-tune ViT with encrypted images. In experiments, the method is demonstrated to outperform conventional methods in an image classification task on the CIFAR-10 and ImageNet datasets in terms of classification accuracy.
Domain Adaptation for Efficiently Fine-tuning Vision Transformer with Encrypted Images
Sep 07, 2023In recent years, deep neural networks (DNNs) trained with transformed data have been applied to various applications such as privacy-preserving learning, access control, and adversarial defenses. However, the use of transformed data decreases the performance of models. Accordingly, in this paper, we propose a novel method for fine-tuning models with transformed images under the use of the vision transformer (ViT). The proposed domain adaptation method does not cause the accuracy degradation of models, and it is carried out on the basis of the embedding structure of ViT. In experiments, we confirmed that the proposed method prevents accuracy degradation even when using encrypted images with the CIFAR-10 and CIFAR-100 datasets.
Combined Use of Federated Learning and Image Encryption for Privacy-Preserving Image Classification with Vision Transformer
Jan 23, 2023In recent years, privacy-preserving methods for deep learning have become an urgent problem. Accordingly, we propose the combined use of federated learning (FL) and encrypted images for privacy-preserving image classification under the use of the vision transformer (ViT). The proposed method allows us not only to train models over multiple participants without directly sharing their raw data but to also protect the privacy of test (query) images for the first time. In addition, it can also maintain the same accuracy as normally trained models. In an experiment, the proposed method was demonstrated to well work without any performance degradation on the CIFAR-10 and CIFAR-100 datasets.
Access Control with Encrypted Feature Maps for Object Detection Models
Sep 29, 2022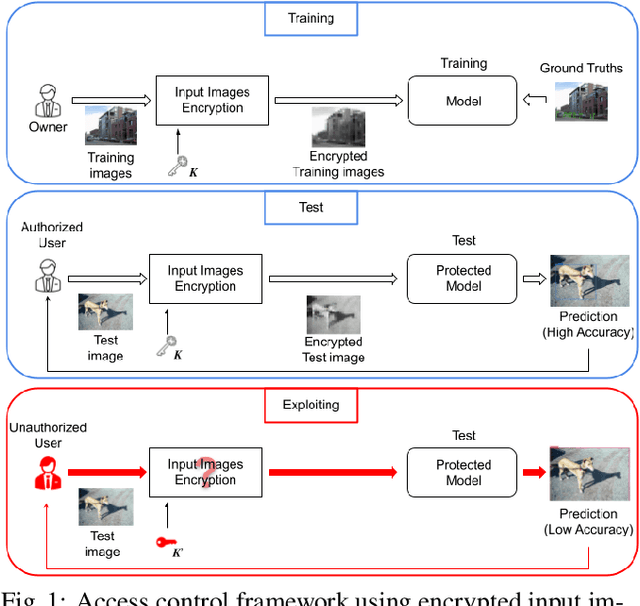

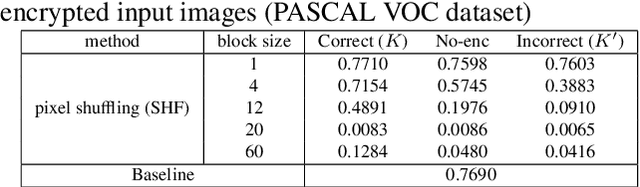

In this paper, we propose an access control method with a secret key for object detection models for the first time so that unauthorized users without a secret key cannot benefit from the performance of trained models. The method enables us not only to provide a high detection performance to authorized users but to also degrade the performance for unauthorized users. The use of transformed images was proposed for the access control of image classification models, but these images cannot be used for object detection models due to performance degradation. Accordingly, in this paper, selected feature maps are encrypted with a secret key for training and testing models, instead of input images. In an experiment, the protected models allowed authorized users to obtain almost the same performance as that of non-protected models but also with robustness against unauthorized access without a key.
An Access Control Method with Secret Key for Semantic Segmentation Models
Aug 28, 2022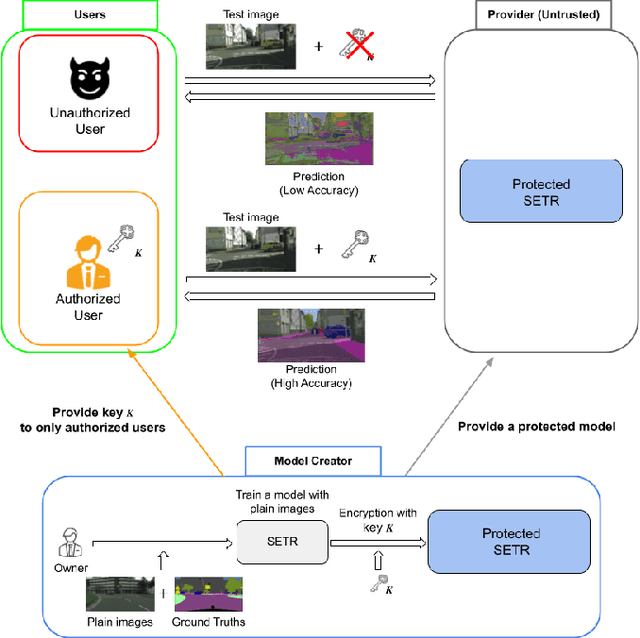


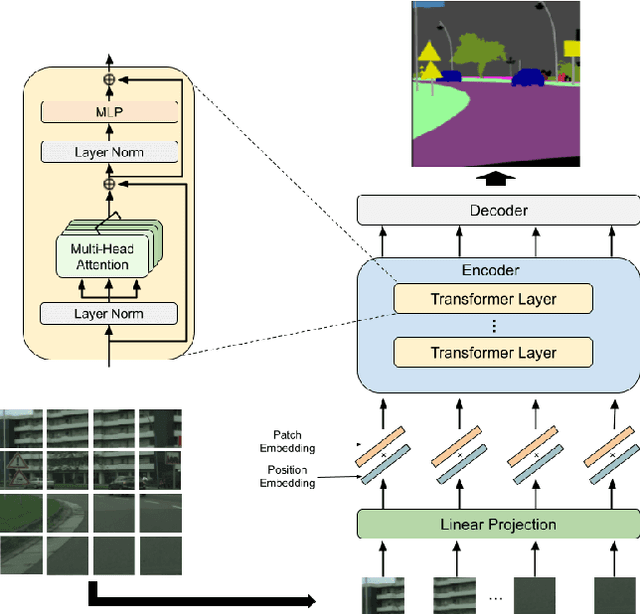
A novel method for access control with a secret key is proposed to protect models from unauthorized access in this paper. We focus on semantic segmentation models with the vision transformer (ViT), called segmentation transformer (SETR). Most existing access control methods focus on image classification tasks, or they are limited to CNNs. By using a patch embedding structure that ViT has, trained models and test images can be efficiently encrypted with a secret key, and then semantic segmentation tasks are carried out in the encrypted domain. In an experiment, the method is confirmed to provide the same accuracy as that of using plain images without any encryption to authorized users with a correct key and also to provide an extremely degraded accuracy to unauthorized users.
Access Control of Object Detection Models Using Encrypted Feature Maps
Feb 01, 2022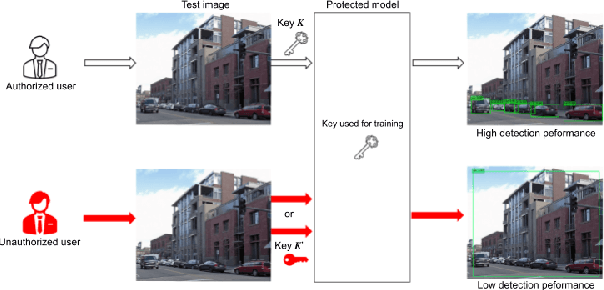
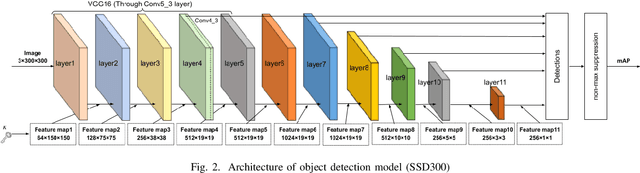
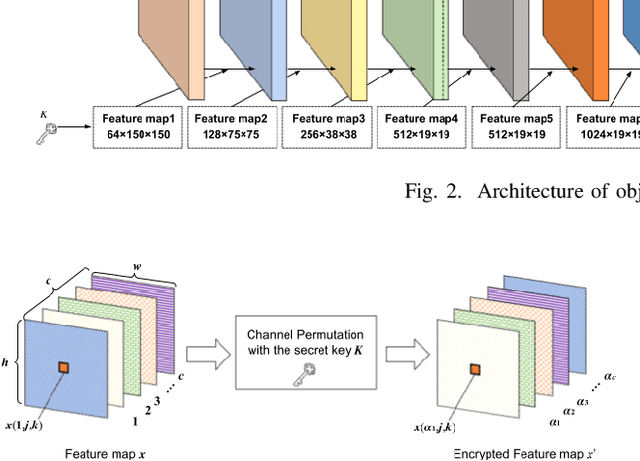

In this paper, we propose an access control method for object detection models. The use of encrypted images or encrypted feature maps has been demonstrated to be effective in access control of models from unauthorized access. However, the effectiveness of the approach has been confirmed in only image classification models and semantic segmentation models, but not in object detection models. In this paper, the use of encrypted feature maps is shown to be effective in access control of object detection models for the first time.