 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Access Control Method with Secret Key for Semantic Segmentation Models
Paper and Code
Aug 28, 2022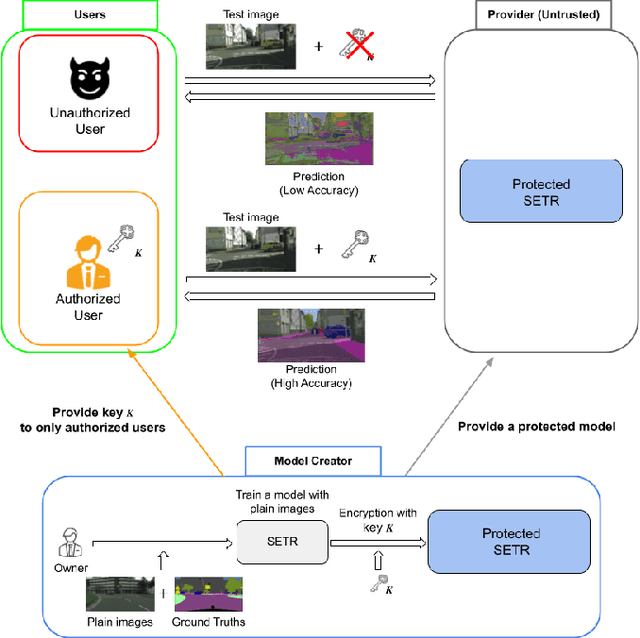


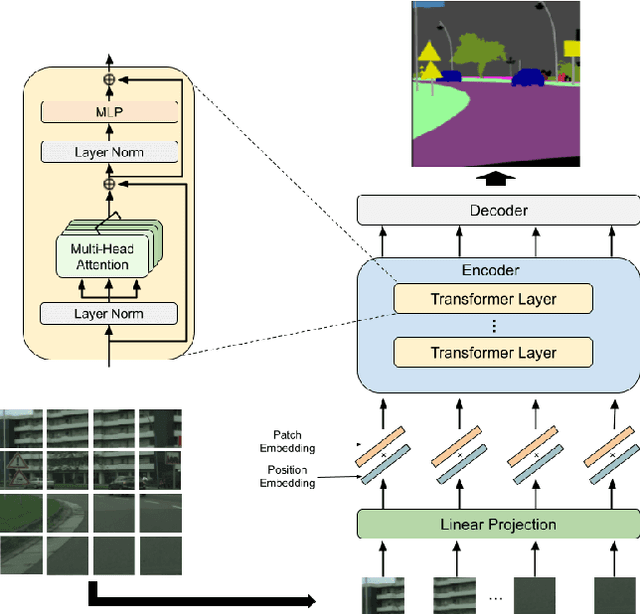
A novel method for access control with a secret key is proposed to protect models from unauthorized access in this paper. We focus on semantic segmentation models with the vision transformer (ViT), called segmentation transformer (SETR). Most existing access control methods focus on image classification tasks, or they are limited to CNNs. By using a patch embedding structure that ViT has, trained models and test images can be efficiently encrypted with a secret key, and then semantic segmentation tasks are carried out in the encrypted domain. In an experiment, the method is confirmed to provide the same accuracy as that of using plain images without any encryption to authorized users with a correct key and also to provide an extremely degraded accuracy to unauthorized users.