 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random Ensemble of Encrypted Vision Transformers for Adversarially Robust Defense
Feb 11, 2024Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In previous studies, the use of models encrypted with a secret key was demonstrated to be robust against white-box attacks, but not against black-box ones. In this paper, we propose a novel method using the vision transformer (ViT) that is a random ensemble of encrypted models for enhancing robustness against both white-box and black-box attacks. In addition, a benchmark attack method, called AutoAttack, is applied to models to test adversarial robustness objectively. In experiments, the method was demonstrated to be robust against not only white-box attacks but also black-box ones in an image classification task on the CIFAR-10 and ImageNet datasets. The method was also compared with the state-of-the-art in a standardized benchmark for adversarial robustness, RobustBench, and it was verified to outperform conventional defenses in terms of clean accuracy and robust accuracy.
A Random Ensemble of Encrypted models for Enhancing Robustness against Adversarial Examples
Jan 05, 2024Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In addition, AEs have adversarial transferability, which means AEs generated for a source model can fool another black-box model (target model) with a non-trivial probability. In previous studies, it was confirmed that the vision transformer (ViT) is more robust against the property of adversarial transferability than convolutional neural network (CNN) models such as ConvMixer, and moreover encrypted ViT is more robust than ViT without any encryption. In this article, we propose a random ensemble of encrypted ViT models to achieve much more robust models. In experiments, the proposed scheme is verified to be more robust against not only black-box attacks but also white-box ones than convention methods.
Enhanced Security against Adversarial Examples Using a Random Ensemble of Encrypted Vision Transformer Models
Jul 26, 2023Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In addition, AEs have adversarial transferability, which means AEs generated for a source model can fool another black-box model (target model) with a non-trivial probability. In previous studies, it was confirmed that the vision transformer (ViT) is more robust against the property of adversarial transferability than convolutional neural network (CNN) models such as ConvMixer, and moreover encrypted ViT is more robust than ViT without any encryption. In this article, we propose a random ensemble of encrypted ViT models to achieve much more robust models. In experiments, the proposed scheme is verified to be more robust against not only black-box attacks but also white-box ones than convention methods.
On the Adversarial Transferability of ConvMixer Models
Sep 19, 2022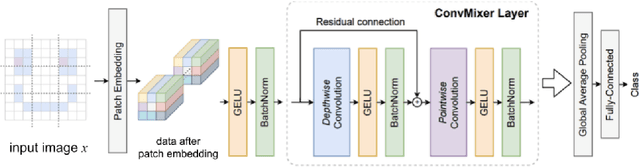
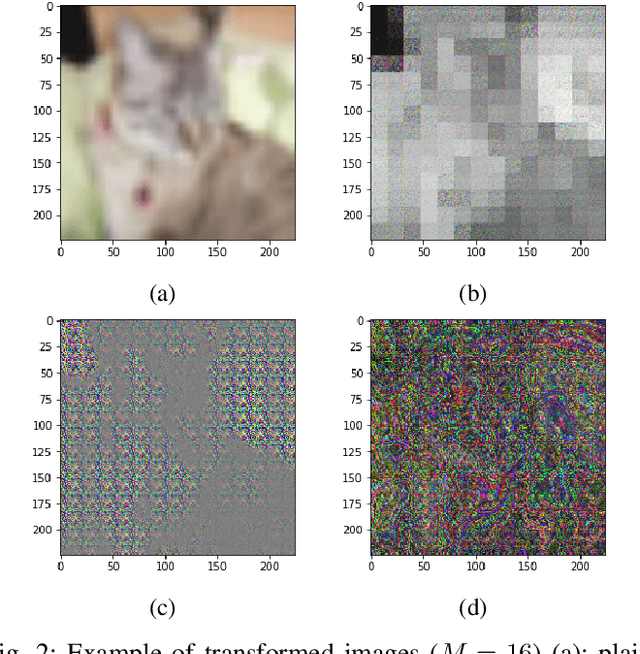
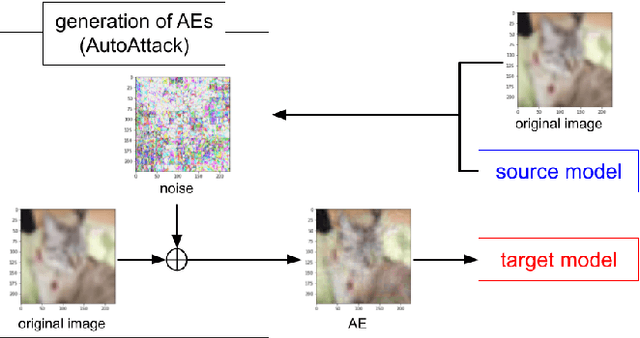
Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In addition, AEs have adversarial transferability, which means AEs generated for a source model can fool another black-box model (target model) with a non-trivial probability. In this paper, we investigate the property of adversarial transferability between models including ConvMixer, which is an isotropic network, for the first time. To objectively verify the property of transferability, the robustness of models is evaluated by using a benchmark attack method called AutoAttack. In an image classification experiment, ConvMixer is confirmed to be weak to adversarial transferability.
An Access Control Method with Secret Key for Semantic Segmentation Models
Aug 28, 2022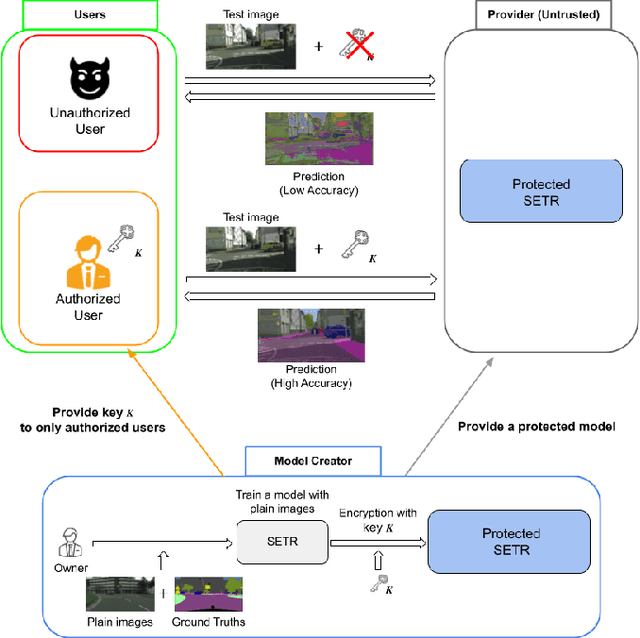


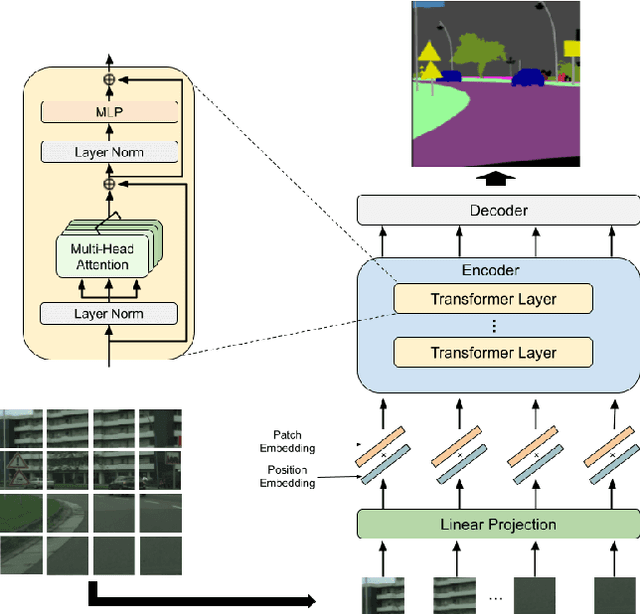
A novel method for access control with a secret key is proposed to protect models from unauthorized access in this paper. We focus on semantic segmentation models with the vision transformer (ViT), called segmentation transformer (SETR). Most existing access control methods focus on image classification tasks, or they are limited to CNNs. By using a patch embedding structure that ViT has, trained models and test images can be efficiently encrypted with a secret key, and then semantic segmentation tasks are carried out in the encrypted domain. In an experiment, the method is confirmed to provide the same accuracy as that of using plain images without any encryption to authorized users with a correct key and also to provide an extremely degraded accuracy to unauthorized users.
An Encryption Method of ConvMixer Models without Performance Degradation
Jul 25, 2022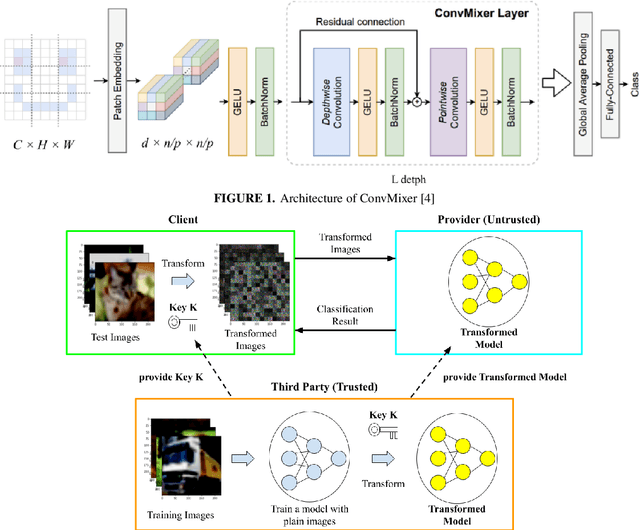


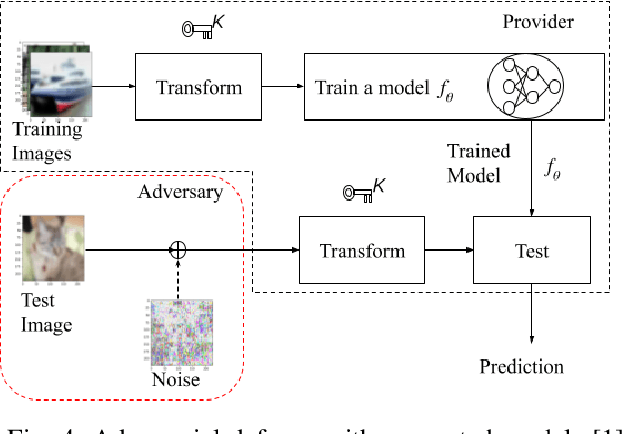
In this paper, we propose an encryption method for ConvMixer models with a secret key. Encryption methods for DNN models have been studied to achieve adversarial defense, model protection and privacy-preserving image classification. However, the use of conventional encryption methods degrades the performance of models compared with that of plain models. Accordingly, we propose a novel method for encrypting ConvMixer models. The method is carried out on the basis of an embedding architecture that ConvMixer has, and models encrypted with the method can have the same performance as models trained with plain images only when using test images encrypted with a secret key. In addition, the proposed method does not require any specially prepared data for model training or network modification. In an experiment, the effectiveness of the proposed method is evaluated in terms of classification accuracy and model protection in an image classification task on the CIFAR10 dataset.
Image and Model Transformation with Secret Key for Vision Transformer
Jul 12, 2022
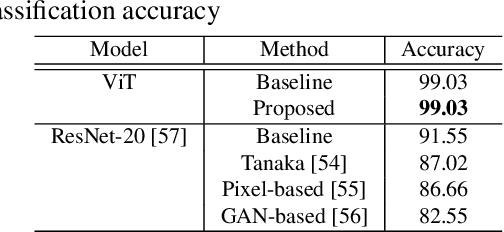
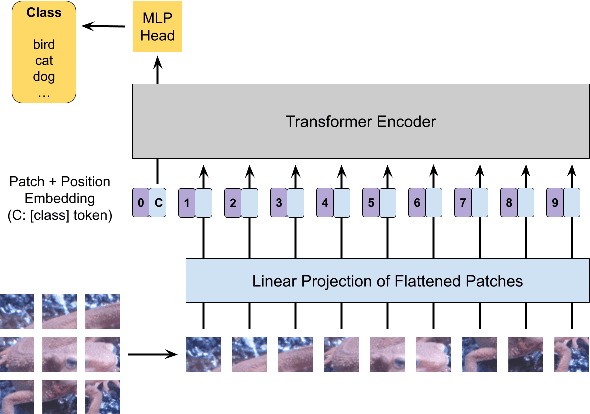
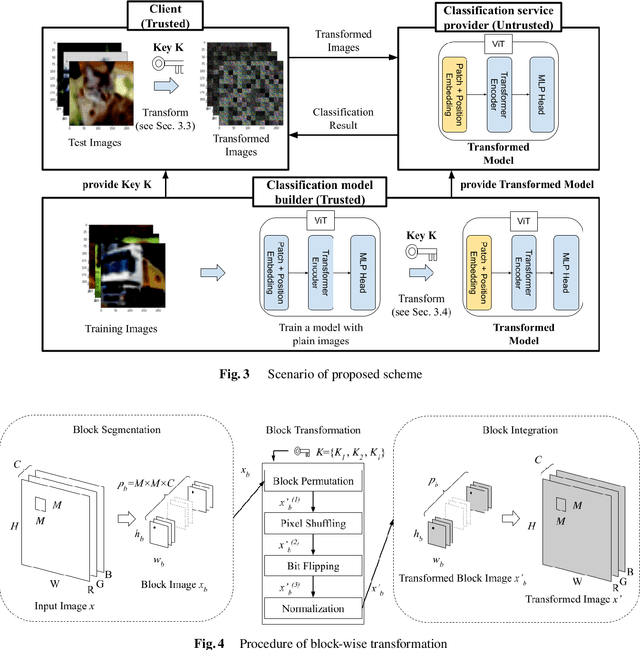
In this paper, we propose a combined use of transformed images and vision transformer (ViT) models transformed with a secret key. We show for the first time that models trained with plain images can be directly transformed to models trained with encrypted images on the basis of the ViT architecture, and the performance of the transformed models is the same as models trained with plain images when using test images encrypted with the key. In addition, the proposed scheme does not require any specially prepared data for training models or network modification, so it also allows us to easily update the secret key. In an experiment, the effectiveness of the proposed scheme is evaluated in terms of performance degradation and model protection performance in an image classification task on the CIFAR-10 dataset.
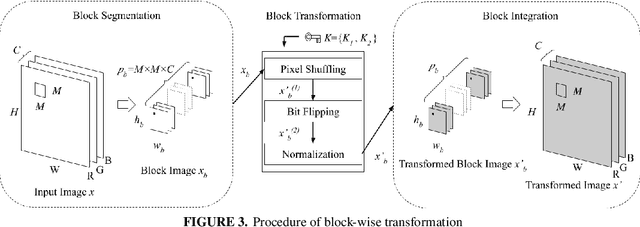
Protection of SVM Model with Secret Key from Unauthorized Access
Nov 17, 2021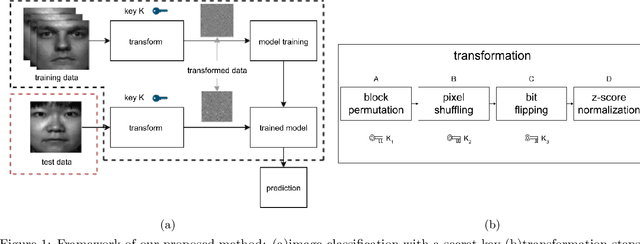


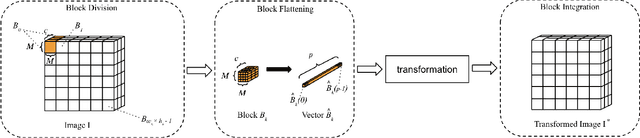
In this paper, we propose a block-wise image transformation method with a secret key for support vector machine (SVM) models. Models trained by using transformed images offer a poor performance to unauthorized users without a key, while they can offer a high performance to authorized users with a key. The proposed method is demonstrated to be robust enough against unauthorized access even under the use of kernel functions in a facial recognition experiment.