 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage and Model Transformation with Secret Key for Vision Transformer
Jul 12, 2022
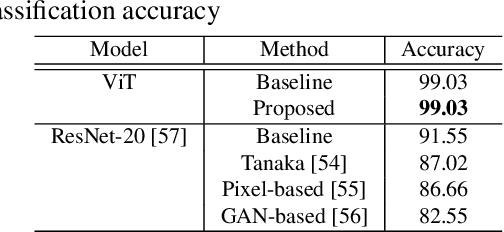
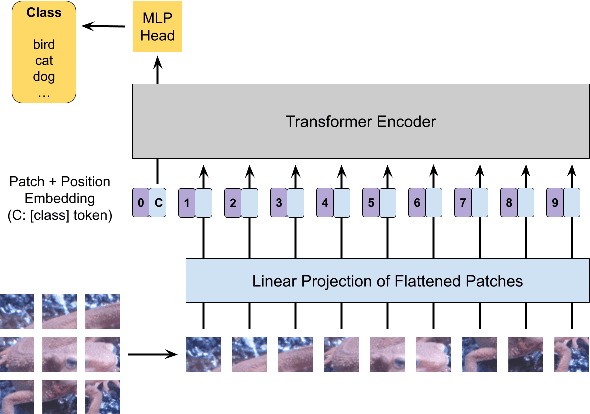
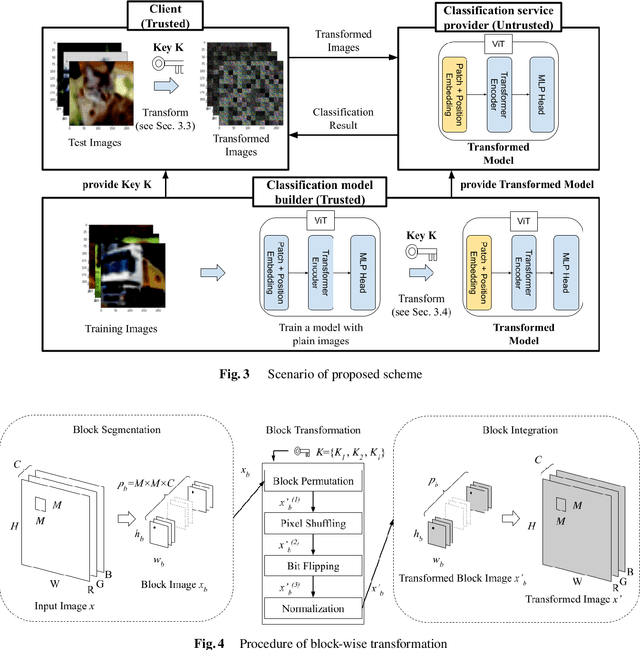
In this paper, we propose a combined use of transformed images and vision transformer (ViT) models transformed with a secret key. We show for the first time that models trained with plain images can be directly transformed to models trained with encrypted images on the basis of the ViT architecture, and the performance of the transformed models is the same as models trained with plain images when using test images encrypted with the key. In addition, the proposed scheme does not require any specially prepared data for training models or network modification, so it also allows us to easily update the secret key. In an experiment, the effectiveness of the proposed scheme is evaluated in terms of performance degradation and model protection performance in an image classification task on the CIFAR-10 dataset.