 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGM: Safety Glasses for Multimodal Large Language Models via Neuron-Level Detoxification
Dec 17, 2025Disclaimer: Samples in this paper may be harmful and cause discomfort. Multimodal large language models (MLLMs) enable multimodal generation but inherit toxic, biased, and NSFW signals from weakly curated pretraining corpora, causing safety risks, especially under adversarial triggers that late, opaque training-free detoxification methods struggle to handle. We propose SGM, a white-box neuron-level multimodal intervention that acts like safety glasses for toxic neurons: it selectively recalibrates a small set of toxic expert neurons via expertise-weighted soft suppression, neutralizing harmful cross-modal activations without any parameter updates. We establish MM-TOXIC-QA, a multimodal toxicity evaluation framework, and compare SGM with existing detoxification techniques. Experiments on open-source MLLMs show that SGM mitigates toxicity in standard and adversarial conditions, cutting harmful rates from 48.2\% to 2.5\% while preserving fluency and multimodal reasoning. SGM is extensible, and its combined defenses, denoted as SGM*, integrate with existing detoxification methods for stronger safety performance, providing an interpretable, low-cost solution for toxicity-controlled multimodal generation.
Access Control Using Spatially Invariant Permutation of Feature Maps for Semantic Segmentation Models
Sep 03, 2021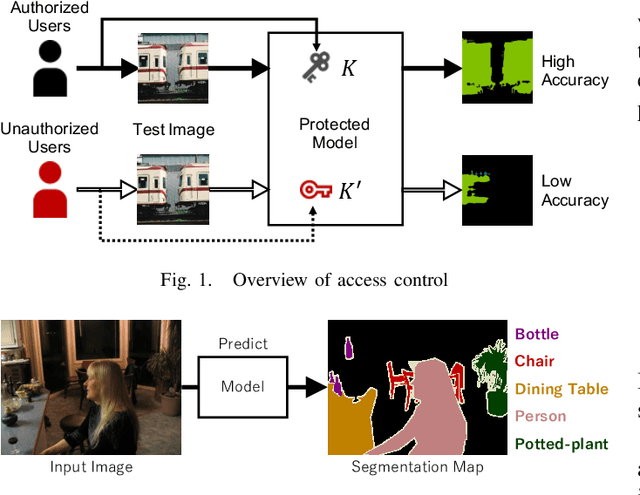
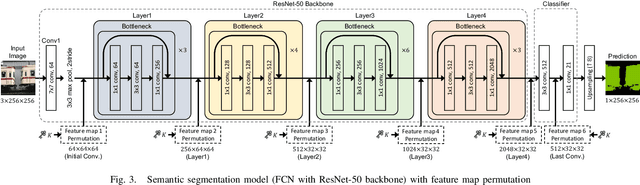
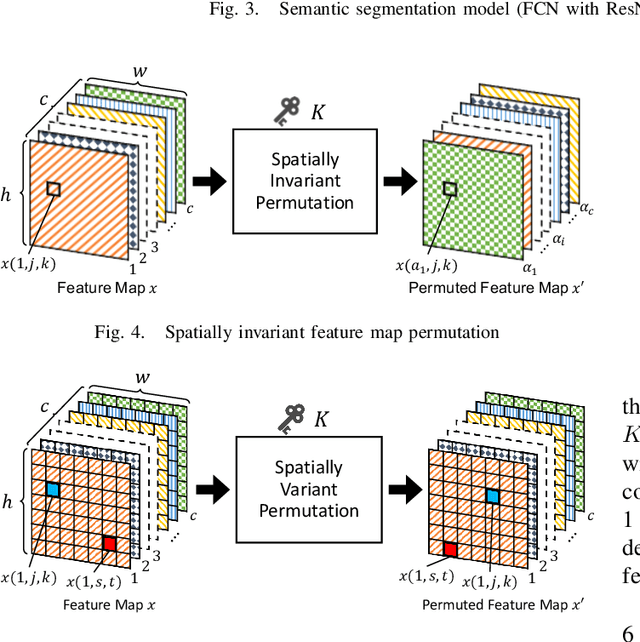
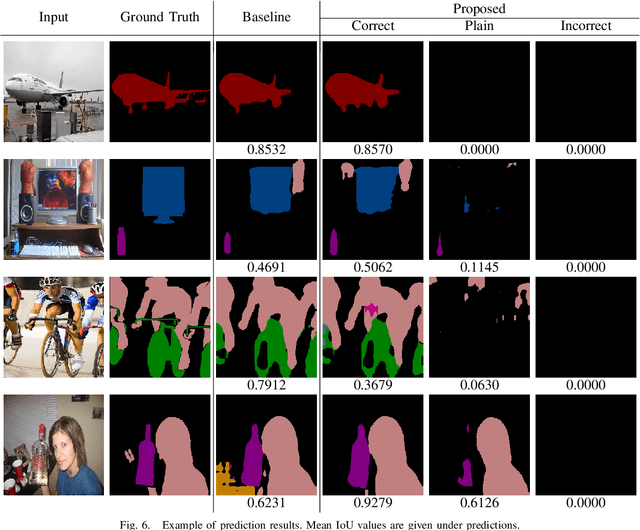
In this paper, we propose an access control method that uses the spatially invariant permutation of feature maps with a secret key for protecting semantic segmentation models. Segmentation models are trained and tested by permuting selected feature maps with a secret key. The proposed method allows rightful users with the correct key not only to access a model to full capacity but also to degrade the performance for unauthorized users. Conventional access control methods have focused only on image classification tasks, and these methods have never been applied to semantic segmentation tasks. In an experiment, the protected models were demonstrated to allow rightful users to obtain almost the same performance as that of non-protected models but also to be robust against access by unauthorized users without a key. In addition, a conventional method with block-wise transformations was also verified to have degraded performance under semantic segmentation models.
A Protection Method of Trained CNN Model Using Feature Maps Transformed With Secret Key From Unauthorized Access
Sep 01, 2021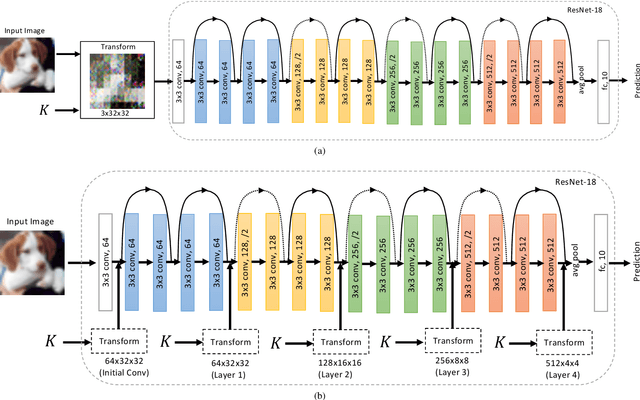
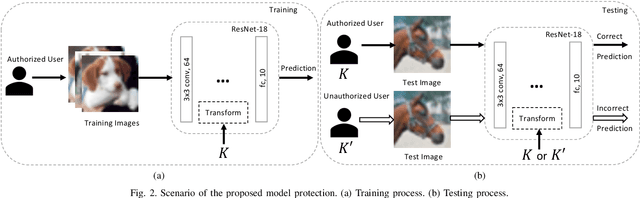
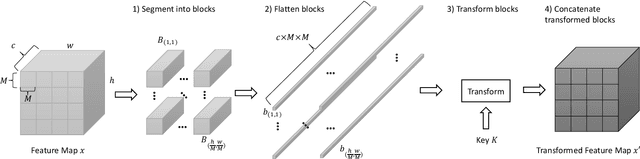
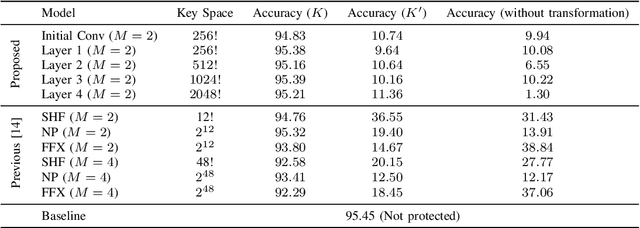
In this paper, we propose a model protection method for convolutional neural networks (CNNs) with a secret key so that authorized users get a high classification accuracy, and unauthorized users get a low classification accuracy. The proposed method applies a block-wise transformation with a secret key to feature maps in the network. Conventional key-based model protection methods cannot maintain a high accuracy when a large key space is selected. In contrast, the proposed method not only maintains almost the same accuracy as non-protected accuracy, but also has a larger key space. Experiments were carried out on the CIFAR-10 dataset, and results show that the proposed model protection method outperformed the previous key-based model protection methods in terms of classification accuracy, key space, and robustness against key estimation attacks and fine-tuning attacks.
Protecting Semantic Segmentation Models by Using Block-wise Image Encryption with Secret Key from Unauthorized Access
Jul 20, 2021


Since production-level trained deep neural networks (DNNs) are of a great business value, protecting such DNN models against copyright infringement and unauthorized access is in a rising demand. However, conventional model protection methods focused only the image classification task, and these protection methods were never applied to semantic segmentation although it has an increasing number of applications. In this paper, we propose to protect semantic segmentation models from unauthorized access by utilizing block-wise transformation with a secret key for the first time. Protected models are trained by using transformed images. Experiment results show that the proposed protection method allows rightful users with the correct key to access the model to full capacity and deteriorate the performance for unauthorized users. However, protected models slightly drop the segmentation performance compared to non-protected models.
Piracy-Resistant DNN Watermarking by Block-Wise Image Transformation with Secret Key
Apr 09, 2021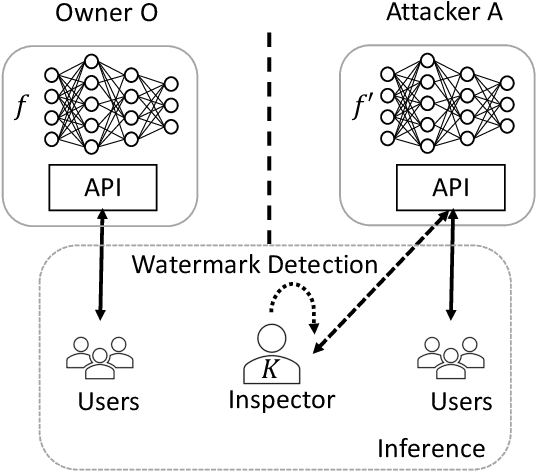
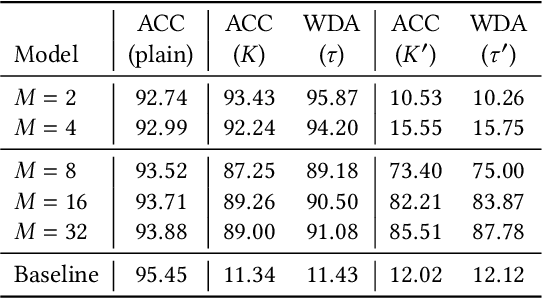
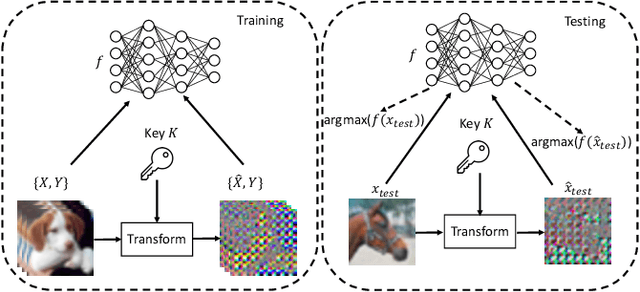

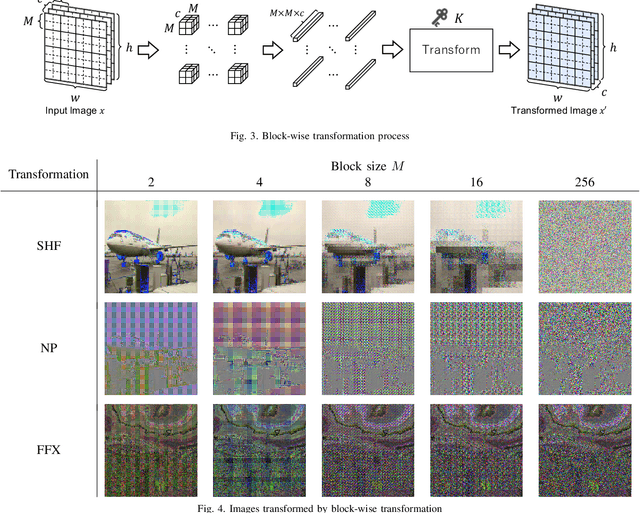
In this paper, we propose a novel DNN watermarking method that utilizes a learnable image transformation method with a secret key. The proposed method embeds a watermark pattern in a model by using learnable transformed images and allows us to remotely verify the ownership of the model. As a result, it is piracy-resistant, so the original watermark cannot be overwritten by a pirated watermark, and adding a new watermark decreases the model accuracy unlike most of the existing DNN watermarking methods. In addition, it does not require a special pre-defined training set or trigger set. We empirically evaluated the proposed method on the CIFAR-10 dataset. The results show that it was resilient against fine-tuning and pruning attacks while maintaining a high watermark-detection accuracy.
Transfer Learning-Based Model Protection With Secret Key
Mar 05, 2021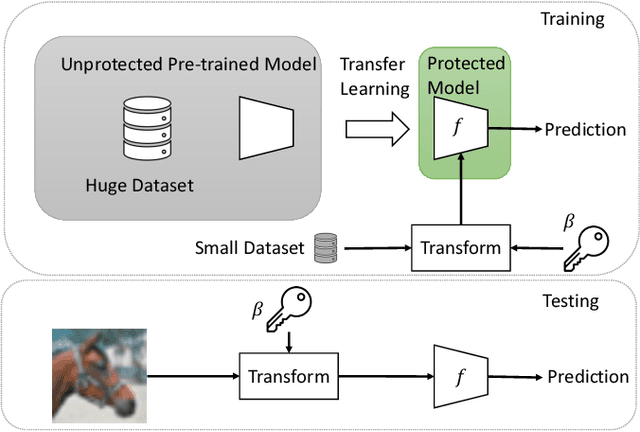
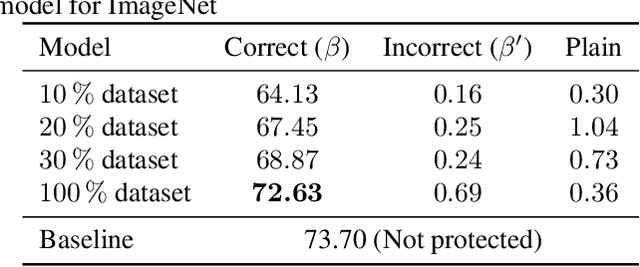

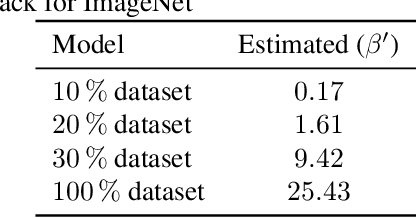
We propose a novel method for protecting trained models with a secret key so that unauthorized users without the correct key cannot get the correct inference. By taking advantage of transfer learning, the proposed method enables us to train a large protected model like a model trained with ImageNet by using a small subset of a training dataset. It utilizes a learnable encryption step with a secret key to generate learnable transformed images. Models with pre-trained weights are fine-tuned by using such transformed images. In experiments with the ImageNet dataset, it is shown that the performance of a protected model was close to that of a non-protected model when the correct key was given, while the accuracy tremendously dropped when an incorrect key was used. The protected model was also demonstrated to be robust against key estimation attacks.
Ensemble of Models Trained by Key-based Transformed Images for Adversarially Robust Defense Against Black-box Attacks
Nov 16, 2020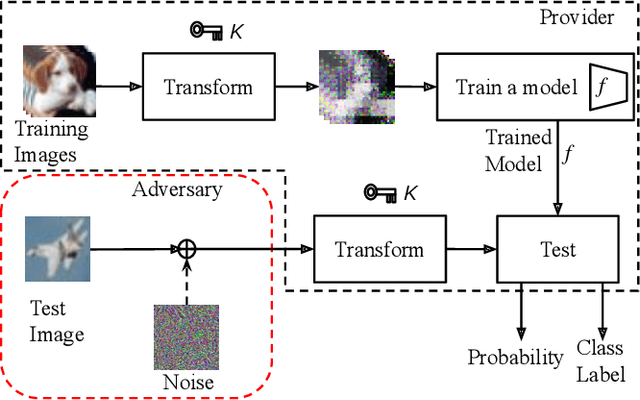
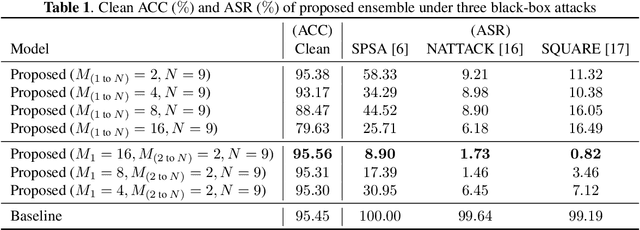
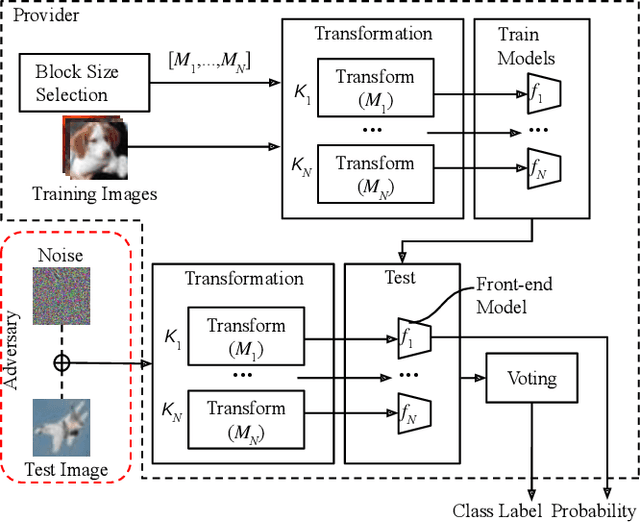
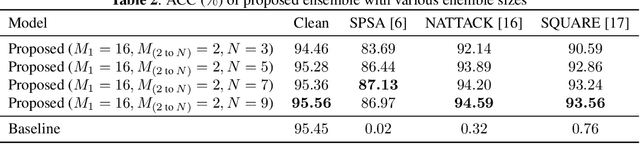
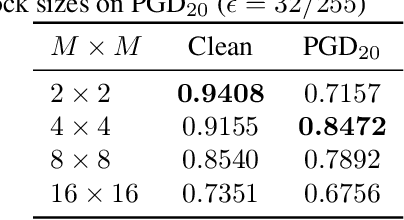
We propose a voting ensemble of models trained by using block-wise transformed images with secret keys for an adversarially robust defense. Key-based adversarial defenses were demonstrated to outperform state-of-the-art defenses against gradient-based (white-box) attacks. However, the key-based defenses are not effective enough against gradient-free (black-box) attacks without requiring any secret keys. Accordingly, we aim to enhance robustness against black-box attacks by using a voting ensemble of models. In the proposed ensemble, a number of models are trained by using images transformed with different keys and block sizes, and then a voting ensemble is applied to the models. In image classification experiments, the proposed defense is demonstrated to defend state-of-the-art attacks. The proposed defense achieves a clean accuracy of 95.56 % and an attack success rate of less than 9 % under attacks with a noise distance of 8/255 on the CIFAR-10 dataset.
Block-wise Image Transformation with Secret Key for Adversarially Robust Defense
Oct 02, 2020
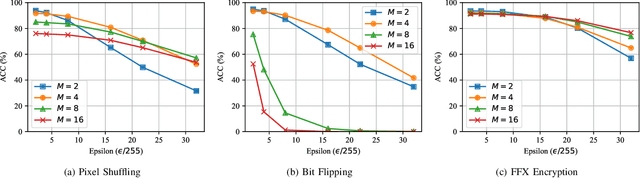
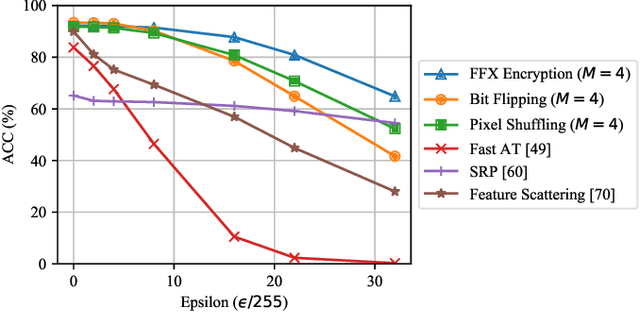
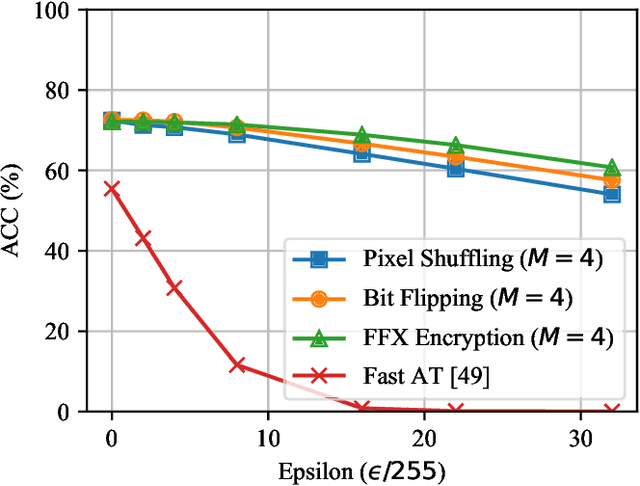
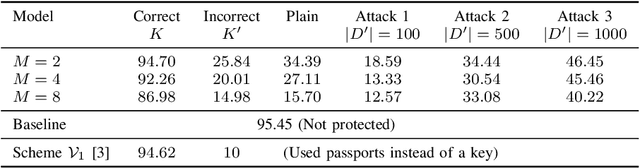
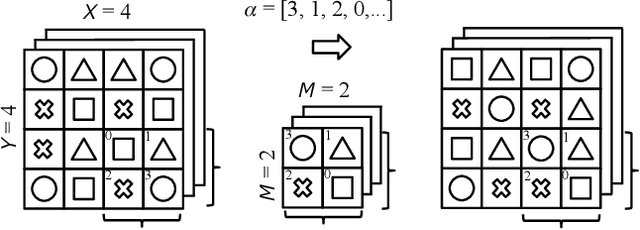
In this paper, we propose a novel defensive transformation that enables us to maintain a high classification accuracy under the use of both clean images and adversarial examples for adversarially robust defense. The proposed transformation is a block-wise preprocessing technique with a secret key to input images. We developed three algorithms to realize the proposed transformation: Pixel Shuffling, Bit Flipping, and FFX Encryption. Experiments were carried out on the CIFAR-10 and ImageNet datasets by using both black-box and white-box attacks with various metrics including adaptive ones. The results show that the proposed defense achieves high accuracy close to that of using clean images even under adaptive attacks for the first time. In the best-case scenario, a model trained by using images transformed by FFX Encryption (block size of 4) yielded an accuracy of 92.30% on clean images and 91.48% under PGD attack with a noise distance of 8/255, which is close to the non-robust accuracy (95.45%) for the CIFAR-10 dataset, and it yielded an accuracy of 72.18% on clean images and 71.43% under the same attack, which is also close to the standard accuracy (73.70%) for the ImageNet dataset. Overall, all three proposed algorithms are demonstrated to outperform state-of-the-art defenses including adversarial training whether or not a model is under attack.
Training DNN Model with Secret Key for Model Protection
Aug 06, 2020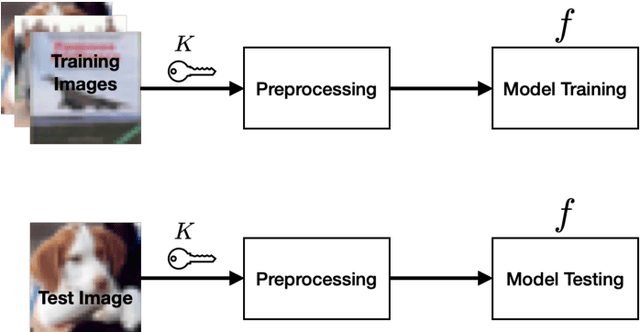
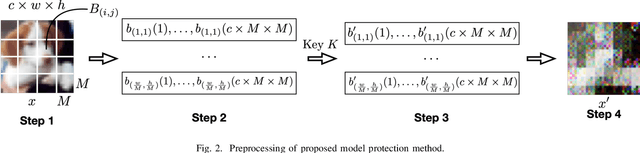

In this paper, we propose a model protection method by using block-wise pixel shuffling with a secret key as a preprocessing technique to input images for the first time. The protected model is built by training with such preprocessed images. Experiment results show that the performance of the protected model is close to that of non-protected models when the key is correct, while the accuracy is severely dropped when an incorrect key is given, and the proposed model protection is robust against not only brute-force attacks but also fine-tuning attacks, while maintaining almost the same performance accuracy as that of using a non-protected model.
Encryption Inspired Adversarial Defense for Visual Classification
May 16, 2020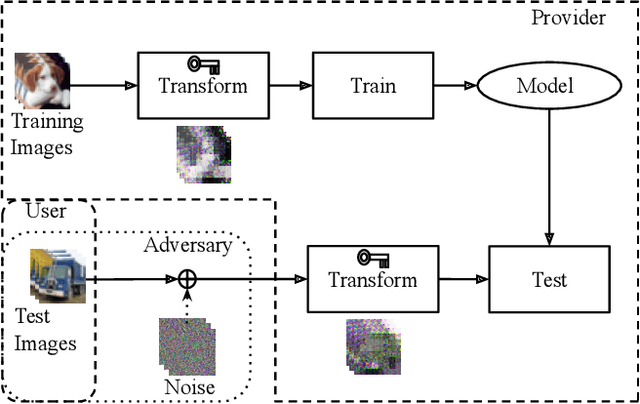

Conventional adversarial defenses reduce classification accuracy whether or not a model is under attacks. Moreover, most of image processing based defenses are defeated due to the problem of obfuscated gradients. In this paper, we propose a new adversarial defense which is a defensive transform for both training and test images inspired by perceptual image encryption methods. The proposed method utilizes a block-wise pixel shuffling method with a secret key. The experiments are carried out on both adaptive and non-adaptive maximum-norm bounded white-box attacks while considering obfuscated gradients. The results show that the proposed defense achieves high accuracy (91.55 %) on clean images and (89.66 %) on adversarial examples with noise distance of 8/255 on CIFAR-10 dataset. Thus, the proposed defense outperforms state-of-the-art adversarial defenses including latent adversarial training, adversarial training and thermometer encoding.