 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyphoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition
Jan 19, 2026Large encoder-decoder models like Whisper achieve strong offline transcription but remain impractical for streaming applications due to high latency. However, due to the accessibility of pre-trained checkpoints, the open Thai ASR landscape remains dominated by these offline architectures, leaving a critical gap in efficient streaming solutions. We present Typhoon ASR Real-time, a 115M-parameter FastConformer-Transducer model for low-latency Thai speech recognition. We demonstrate that rigorous text normalization can match the impact of model scaling: our compact model achieves a 45x reduction in computational cost compared to Whisper Large-v3 while delivering comparable accuracy. Our normalization pipeline resolves systemic ambiguities in Thai transcription --including context-dependent number verbalization and repetition markers (mai yamok) --creating consistent training targets. We further introduce a two-stage curriculum learning approach for Isan (north-eastern) dialect adaptation that preserves Central Thai performance. To address reproducibility challenges in Thai ASR, we release the Typhoon ASR Benchmark, a gold-standard human-labeled datasets with transcriptions following established Thai linguistic conventions, providing standardized evaluation protocols for the research community.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025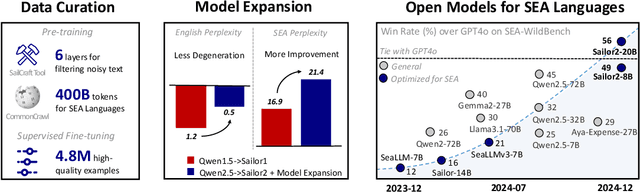

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models
Dec 19, 2024



This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ post-training techniques to enhance Thai language performance while preserving the base models' original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. To guardrail text generation, we release Typhoon2-Safety, a classifier enhanced for Thai cultures and language. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs.
Typhoon: Thai Large Language Models
Dec 21, 2023Typhoon is a series of Thai large language models (LLMs) developed specifically for the Thai language. This technical report presents challenges and insights in developing Thai LLMs, including data preparation, pretraining, instruction-tuning, and evaluation. As one of the challenges of low-resource languages is the amount of pretraining data, we apply continual training to transfer existing world knowledge from a strong LLM. To evaluate the Thai knowledge encapsulated in each model from the pretraining stage, we develop ThaiExam, a benchmark based on examinations for high-school students and investment professionals in Thailand. In addition, we fine-tune Typhoon to follow Thai instructions, and we evaluate instruction-tuned models on Thai instruction datasets as well as translation, summarization, and question-answering tasks. Experimental results on a suite of Thai benchmarks show that Typhoon outperforms all open-source Thai language models, and its performance is on par with GPT-3.5 in Thai while having only 7 billion parameters and being 2.62 times more efficient in tokenizing Thai text.