 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Rewarding Sequential Monte Carlo for Masked Diffusion Language Models
Feb 02, 2026This work presents self-rewarding sequential Monte Carlo (SMC), an inference-time scaling algorithm enabling effective sampling of masked diffusion language models (MDLMs). Our algorithm stems from the observation that most existing MDLMs rely on a confidence-based sampling strategy, where only tokens with the highest prediction confidence are preserved at each step. This restricts the generation to a noise-sensitive, greedy decoding paradigm, resulting in an inevitable collapse in the diversity of possible paths. We address this problem by launching multiple interacting diffusion processes in parallel, referred to as particles, for trajectory exploration. Importantly, we introduce the trajectory-level confidence as a self-rewarding signal for assigning particle importance weights. During sampling, particles are iteratively weighted and resampled to systematically steer generation towards globally confident, high-quality samples. Our self-rewarding SMC is verified on various masked diffusion language models and benchmarks, achieving significant improvement without extra training or reward guidance, while effectively converting parallel inference capacity into improved sampling quality. Our code is available at https://github.com/Algolzw/self-rewarding-smc.
On the Role of Discreteness in Diffusion LLMs
Dec 27, 2025Diffusion models offer appealing properties for language generation, such as parallel decoding and iterative refinement, but the discrete and highly structured nature of text challenges the direct application of diffusion principles. In this paper, we revisit diffusion language modeling from the view of diffusion process and language modeling, and outline five properties that separate diffusion mechanics from language-specific requirements. We first categorize existing approaches into continuous diffusion in embedding space and discrete diffusion over tokens. We then show that each satisfies only part of the five essential properties and therefore reflects a structural trade-off. Through analyses of recent large diffusion language models, we identify two central issues: (i) uniform corruption does not respect how information is distributed across positions, and (ii) token-wise marginal training cannot capture multi-token dependencies during parallel decoding. These observations motivate diffusion processes that align more closely with the structure of text, and encourage future work toward more coherent diffusion language models.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025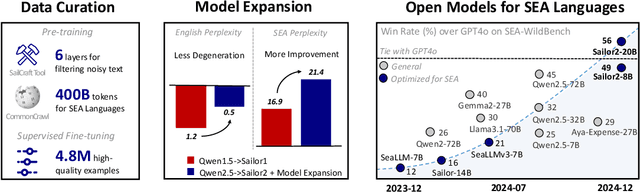
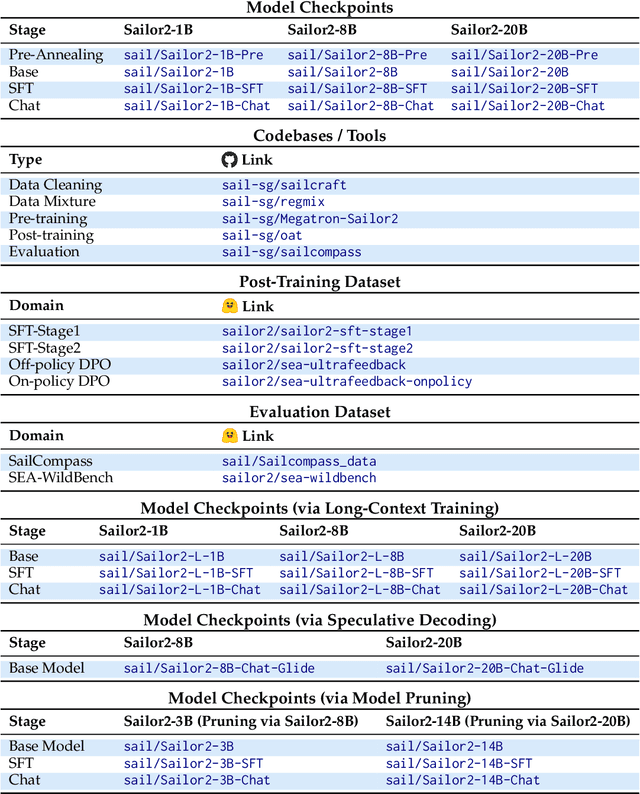

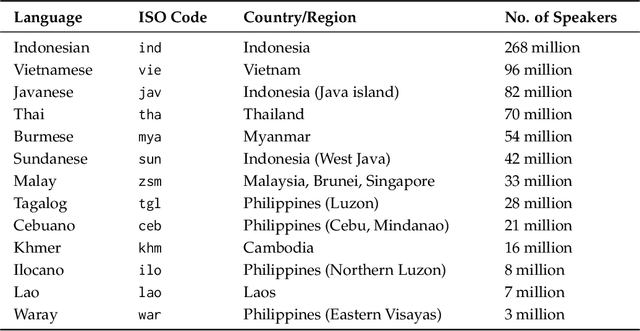
Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Self-Harmonized Chain of Thought
Sep 06, 2024



Chain-of-Thought (CoT) prompting reveals that large language models are capable of performing complex reasoning via intermediate steps. CoT prompting is primarily categorized into three approaches. The first approach utilizes straightforward prompts like ``Let's think step by step'' to generate a sequential thought process before yielding an answer. The second approach makes use of human-crafted, step-by-step demonstrations to guide the model's reasoning process. The third automates the generation of reasoned demonstrations with the 'Let's think step by step'.This approach sometimes leads to reasoning errors, highlighting the need to diversify demonstrations to mitigate its misleading effects. However, diverse demonstrations pose challenges for effective representations. In this work, we propose ECHO, a self-harmonized chain-of-thought prompting method. It consolidates diverse solution paths into a uniform and effective solution pattern.ECHO demonstrates the best overall performance across three reasoning domains.
Tab-CoT: Zero-shot Tabular Chain of Thought
May 28, 2023The chain-of-though (CoT) prompting methods were successful in various natural language processing (NLP) tasks thanks to their ability to unveil the underlying complex reasoning processes. Such reasoning processes typically exhibit implicitly structured steps. Recent efforts also started investigating methods to encourage more explicitly structured reasoning procedures to be captured. In this work, we propose Tab-CoT, a novel tabular-format CoT prompting method, which allows the complex reasoning process to be explicitly modelled in a highly structured manner. Despite its simplicity, we show that our approach is capable of performing reasoning across multiple dimensions (i.e., both rows and columns). We demonstrate our approach's strong zero-shot and few-shot capabilities through extensive experiments on a range of reasoning tasks.
Online Refinement of Low-level Feature Based Activation Map for Weakly Supervised Object Localization
Oct 12, 2021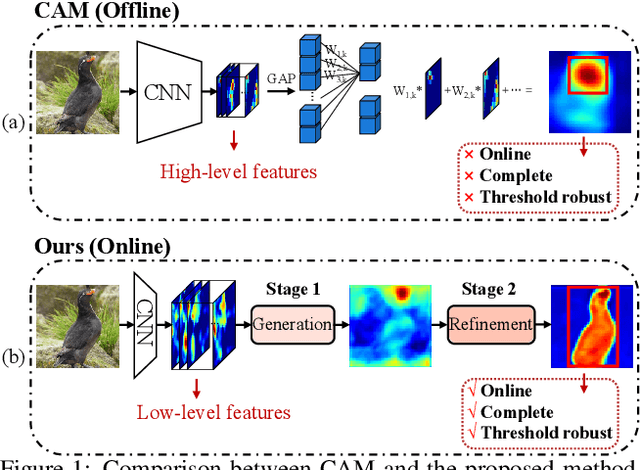
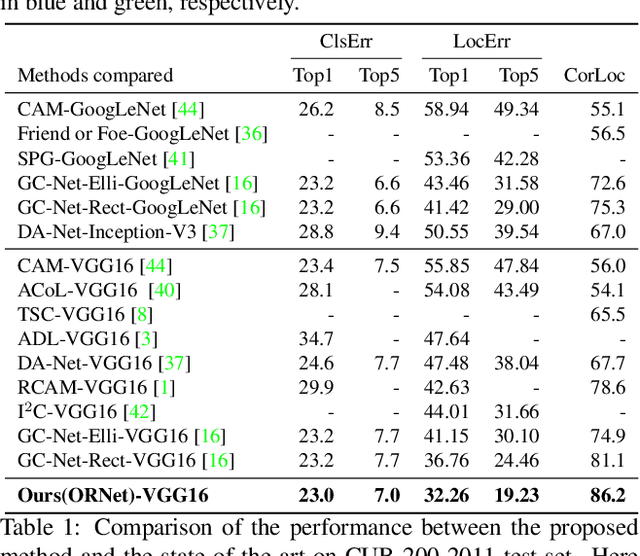

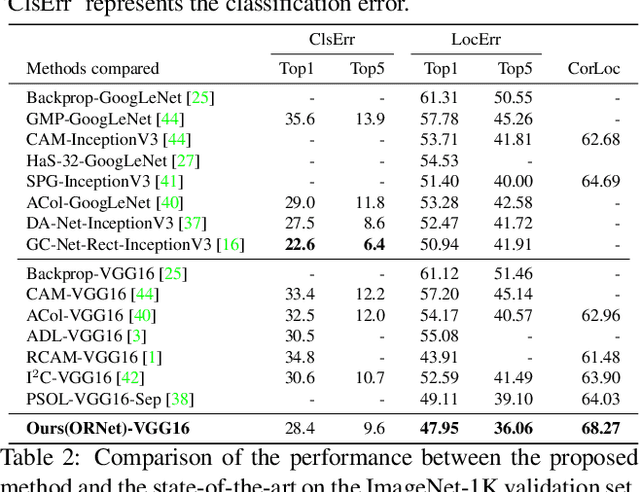
We present a two-stage learning framework for weakly supervised object localization (WSOL). While most previous efforts rely on high-level feature based CAMs (Class Activation Maps), this paper proposes to localize objects using the low-level feature based activation maps. In the first stage, an activation map generator produces activation maps based on the low-level feature maps in the classifier, such that rich contextual object information is included in an online manner. In the second stage, we employ an evaluator to evaluate the activation maps predicted by the activation map generator. Based on this, we further propose a weighted entropy loss, an attentive erasing, and an area loss to drive the activation map generator to substantially reduce the uncertainty of activations between object and background, and explore less discriminative regions. Based on the low-level object information preserved in the first stage, the second stage model gradually generates a well-separated, complete, and compact activation map of object in the image, which can be easily thresholded for accurate localization. Extensive experiments on CUB-200-2011 and ImageNet-1K datasets show that our framework surpasses previous methods by a large margin, which sets a new state-of-the-art for WSOL.