 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Refinement of Low-level Feature Based Activation Map for Weakly Supervised Object Localization
Oct 12, 2021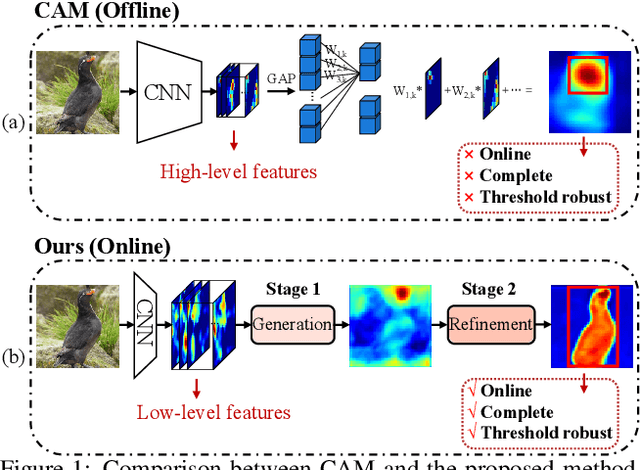
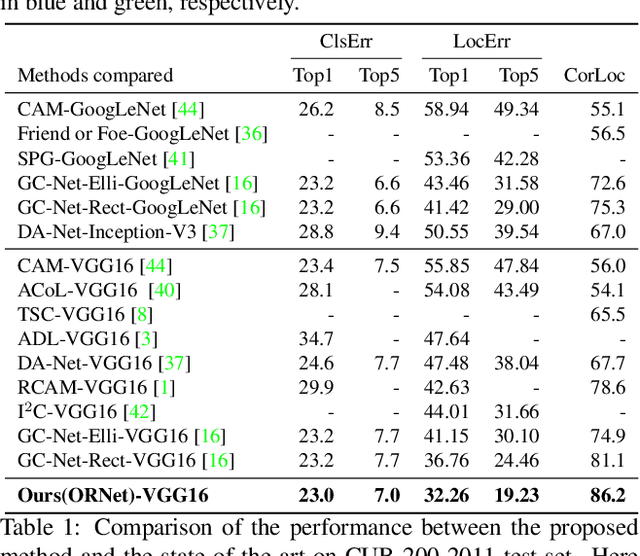

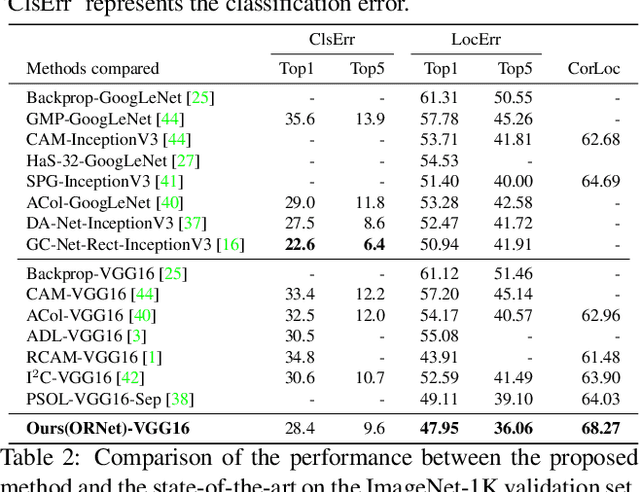
We present a two-stage learning framework for weakly supervised object localization (WSOL). While most previous efforts rely on high-level feature based CAMs (Class Activation Maps), this paper proposes to localize objects using the low-level feature based activation maps. In the first stage, an activation map generator produces activation maps based on the low-level feature maps in the classifier, such that rich contextual object information is included in an online manner. In the second stage, we employ an evaluator to evaluate the activation maps predicted by the activation map generator. Based on this, we further propose a weighted entropy loss, an attentive erasing, and an area loss to drive the activation map generator to substantially reduce the uncertainty of activations between object and background, and explore less discriminative regions. Based on the low-level object information preserved in the first stage, the second stage model gradually generates a well-separated, complete, and compact activation map of object in the image, which can be easily thresholded for accurate localization. Extensive experiments on CUB-200-2011 and ImageNet-1K datasets show that our framework surpasses previous methods by a large margin, which sets a new state-of-the-art for WSOL.
Intra-Camera Supervised Person Re-Identification
Feb 12, 2020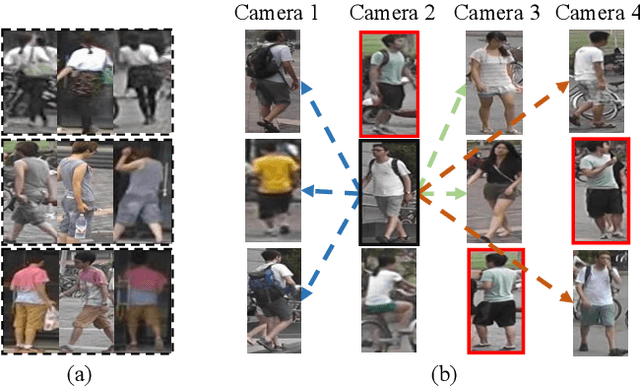
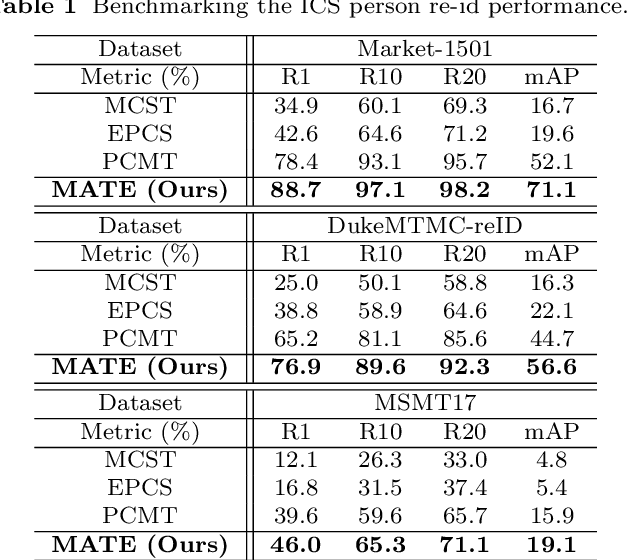
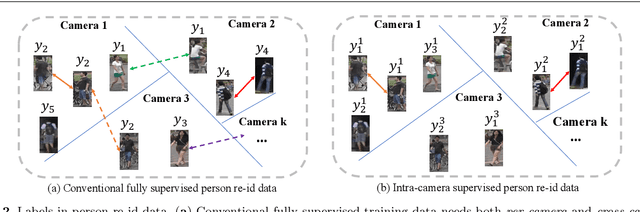
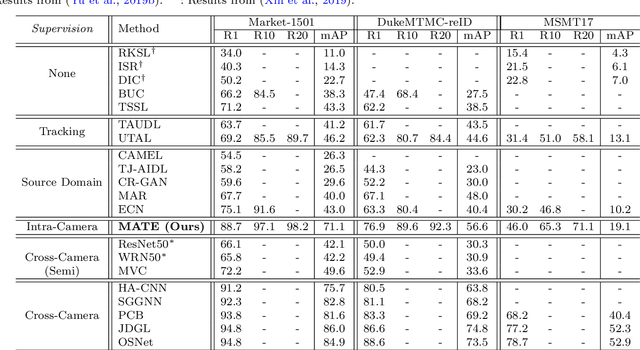
Existing person re-identification (re-id) methods mostly exploit a large set of cross-camera identity labelled training data. This requires a tedious data collection and annotation process, leading to poor scalability in practical re-id applications. On the other hand unsupervised re-id methods do not need identity label information, but they usually suffer from much inferior and insufficient model performance. To overcome these fundamental limitations, we propose a novel person re-identification paradigm based on an idea of independent per-camera identity annotation. This eliminates the most time-consuming and tedious inter-camera identity labelling process, significantly reducing the amount of human annotation efforts. Consequently, it gives rise to a more scalable and more feasible setting, which we call Intra-Camera Supervised (ICS) person re-id, for which we formulate a Multi-tAsk mulTi-labEl (MATE) deep learning method. Specifically, MATE is designed for self-discovering the cross-camera identity correspondence in a per-camera multi-task inference framework. Extensive experiments demonstrate the cost-effectiveness superiority of our method over the alternative approaches on three large person re-id datasets. For example, MATE yields 88.7% rank-1 score on Market-1501 in the proposed ICS person re-id setting, significantly outperforming unsupervised learning models and closely approaching conventional fully supervised learning competitors.
Unsupervised Domain-Adaptive Person Re-identification Based on Attributes
Aug 27, 2019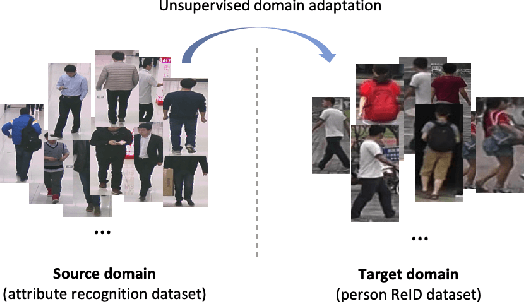
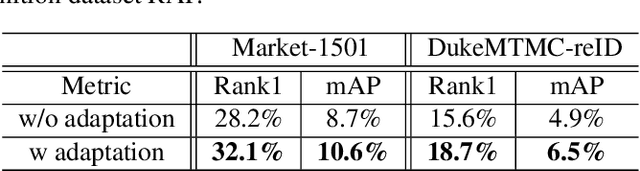

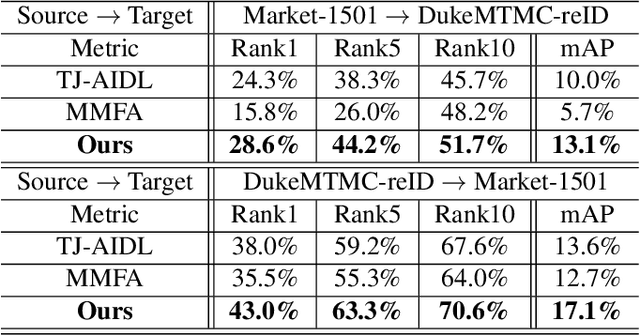
Pedestrian attributes, e.g., hair length, clothes type and color, locally describe the semantic appearance of a person. Training person re-identification (ReID) algorithms under the supervision of such attributes have proven to be effective in extracting local features which are important for ReID. Unlike person identity, attributes are consistent across different domains (or datasets). However, most of ReID datasets lack attribute annotations. On the other hand, there are several datasets labeled with sufficient attributes for the case of pedestrian attribute recognition. Exploiting such data for ReID purpose can be a way to alleviate the shortage of attribute annotations in ReID case. In this work, an unsupervised domain adaptive ReID feature learning framework is proposed to make full use of attribute annotations. We propose to transfer attribute-related features from their original domain to the ReID one: to this end, we introduce an adversarial discriminative domain adaptation method in order to learn domain invariant features for encoding semantic attributes. Experiments on three large-scale datasets validate the effectiveness of the proposed ReID framework.
Intra-Camera Supervised Person Re-Identification: A New Benchmark
Aug 27, 2019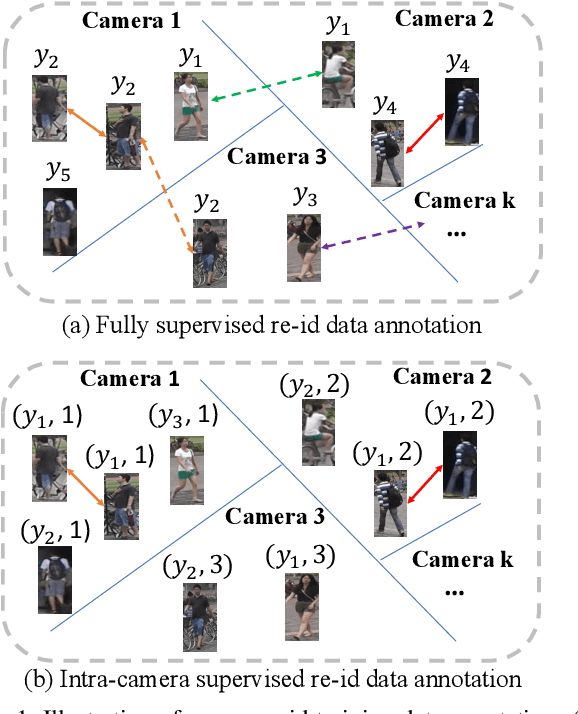
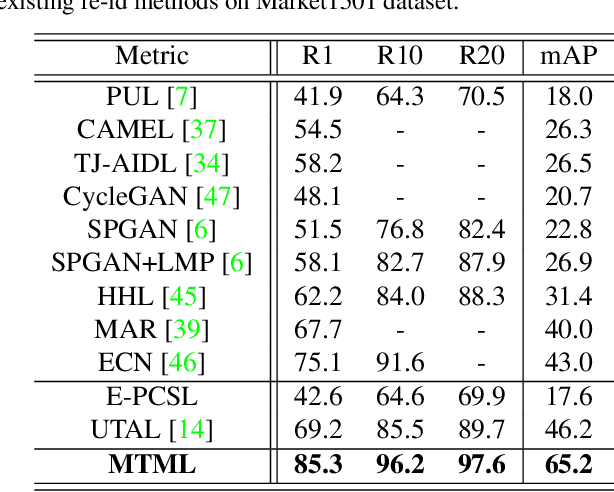
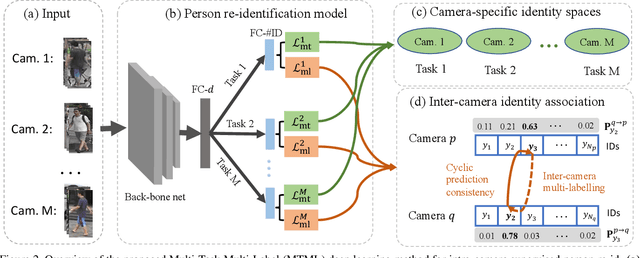
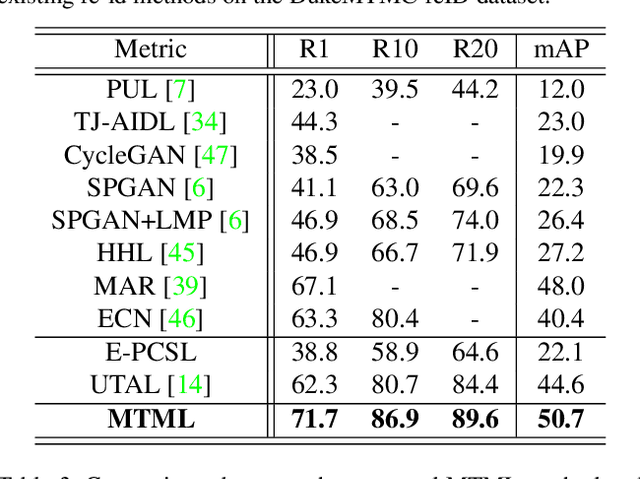
Existing person re-identification (re-id) methods rely mostly on a large set of inter-camera identity labelled training data, requiring a tedious data collection and annotation process therefore leading to poor scalability in practical re-id applications. To overcome this fundamental limitation, we consider person re-identification without inter-camera identity association but only with identity labels independently annotated within each individual camera-view. This eliminates the most time-consuming and tedious inter-camera identity labelling process in order to significantly reduce the amount of human efforts required during annotation. It hence gives rise to a more scalable and more feasible learning scenario, which we call Intra-Camera Supervised (ICS) person re-id. Under this ICS setting with weaker label supervision, we formulate a Multi-Task Multi-Label (MTML) deep learning method. Given no inter-camera association, MTML is specially designed for self-discovering the inter-camera identity correspondence. This is achieved by inter-camera multi-label learning under a joint multi-task inference framework. In addition, MTML can also efficiently learn the discriminative re-id feature representations by fully using the available identity labels within each camera-view. Extensive experiments demonstrate the performance superiority of our MTML model over the state-of-the-art alternative methods on three large-scale person re-id datasets in the proposed intra-camera supervised learning setting.