 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowReasoner: Reinforcing Query-Level Meta-Agents
Apr 21, 2025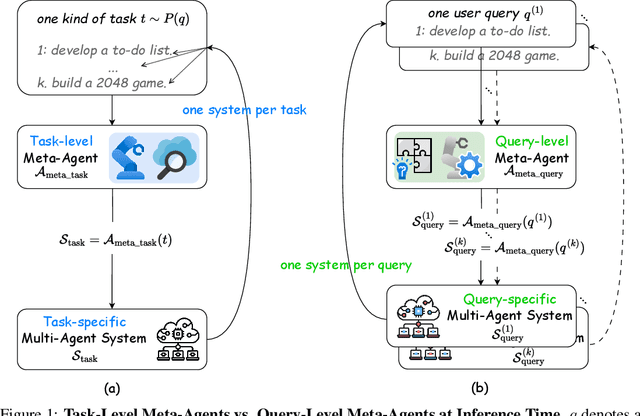
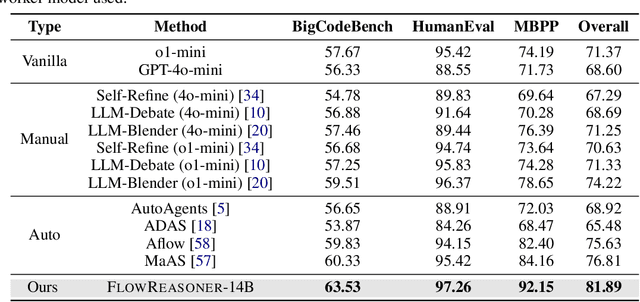
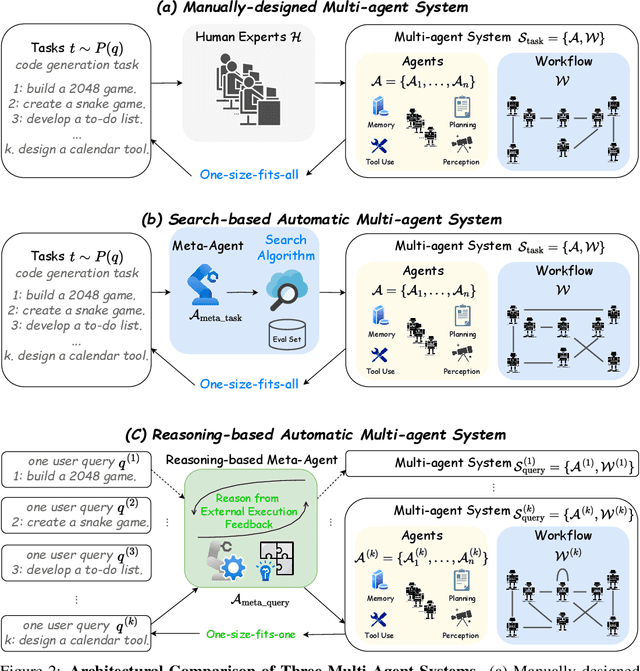
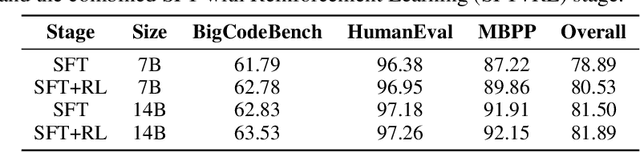
This paper proposes a query-level meta-agent named FlowReasoner to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-based meta-agent via external execution feedback. Concretely, by distilling DeepSeek R1, we first endow the basic reasoning ability regarding the generation of multi-agent systems to FlowReasoner. Then, we further enhance it via reinforcement learning (RL) with external execution feedback. A multi-purpose reward is designed to guide the RL training from aspects of performance, complexity, and efficiency. In this manner, FlowReasoner is enabled to generate a personalized multi-agent system for each user query via deliberative reasoning. Experiments on both engineering and competition code benchmarks demonstrate the superiority of FlowReasoner. Remarkably, it surpasses o1-mini by 10.52% accuracy across three benchmarks. The code is available at https://github.com/sail-sg/FlowReasoner.
NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
Apr 17, 2025Recent advances in reinforcement learning (RL) have strengthened the reasoning capabilities of vision-language models (VLMs). However, enhancing policy exploration to more effectively scale test-time compute remains underexplored in VLMs. In addition, VLMs continue to struggle with imperfect visual perception, which in turn affects the subsequent reasoning process. To this end, we propose NoisyRollout, a simple yet effective RL approach that mixes trajectories from both clean and moderately distorted images to introduce targeted diversity in visual perception and the resulting reasoning patterns. Without additional training cost, NoisyRollout enhances the exploration capabilities of VLMs by incorporating a vision-oriented inductive bias. Furthermore, NoisyRollout employs a noise annealing schedule that gradually reduces distortion strength over training, ensuring benefit from noisy signals early while maintaining training stability and scalability in later stages. With just 2.1K training samples, NoisyRollout achieves state-of-the-art performance among open-source RL-tuned models on 5 out-of-domain benchmarks spanning both reasoning and perception tasks, while preserving comparable or even better in-domain performance.
Efficient Process Reward Model Training via Active Learning
Apr 14, 2025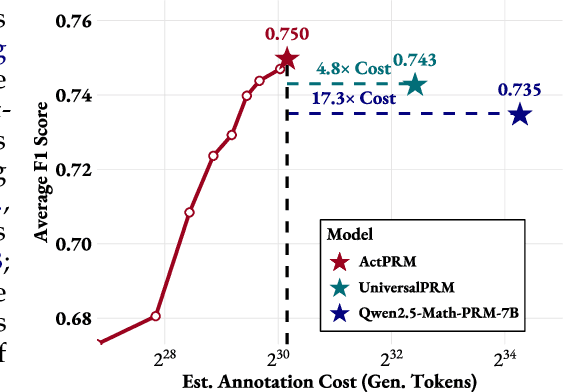
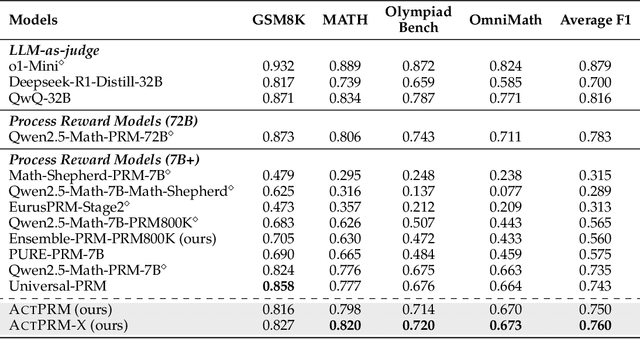
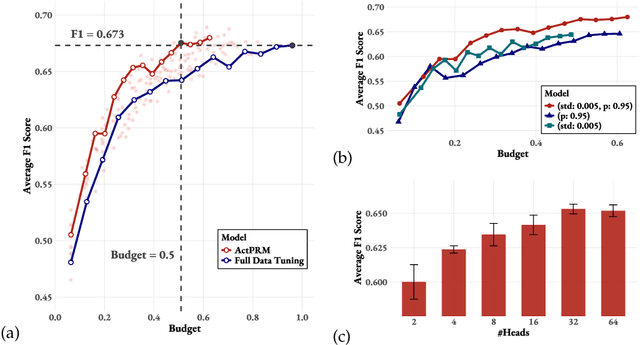
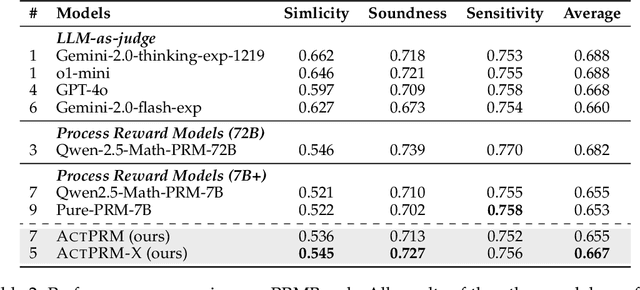
Process Reward Models (PRMs) provide step-level supervision to large language models (LLMs), but scaling up training data annotation remains challenging for both humans and LLMs. To address this limitation, we propose an active learning approach, ActPRM, which proactively selects the most uncertain samples for training, substantially reducing labeling costs. During training, we use the PRM to estimate uncertainty after the forward pass, retaining only highly uncertain data. A capable yet costly reasoning model then labels this data. Then we compute the loss with respect to the labels and update the PRM's weights. We compare ActPRM vs. vanilla fine-tuning, on a pool-based active learning setting, demonstrating that ActPRM reduces 50% annotation, but achieving the comparable or even better performance. Beyond annotation efficiency, we further advance the actively trained PRM by filtering over 1M+ math reasoning trajectories with ActPRM, retaining 60% of the data. A subsequent training on this selected dataset yields a new state-of-the-art (SOTA) PRM on ProcessBench (75.0%) and PRMBench (65.5%) compared with same sized models.
Reasoning Does Not Necessarily Improve Role-Playing Ability
Feb 24, 2025The application of role-playing large language models (LLMs) is rapidly expanding in both academic and commercial domains, driving an increasing demand for high-precision role-playing models. Simultaneously, the rapid advancement of reasoning techniques has continuously pushed the performance boundaries of LLMs. This intersection of practical role-playing demands and evolving reasoning capabilities raises an important research question: "Can reasoning techniques enhance the role-playing capabilities of LLMs?" To address this, we conduct a comprehensive study using 6 role-playing benchmarks, 24 LLMs, and 3 distinct role-playing strategies, comparing the effectiveness of direct zero-shot role-playing, role-playing with Chain-of-Thought (CoT), and role-playing using reasoning-optimized LLMs. Our findings reveal that CoT may reduce role-playing performance, reasoning-optimized LLMs are unsuitable for role-playing, reasoning ability disrupts the role-playing scaling law, large models still lack proficiency in advanced role-playing, and Chinese role-playing performance surpasses English role-playing performance. Furthermore, based on extensive experimental results, we propose two promising future research directions: Role-aware CoT for improving role-playing LLMs and Reinforcement Learning for role-playing LLMs, aiming to enhance the adaptability, consistency, and effectiveness of role-playing LLMs for both research and real-world applications.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025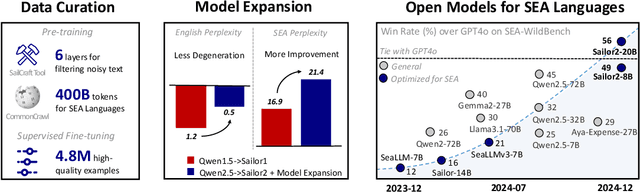
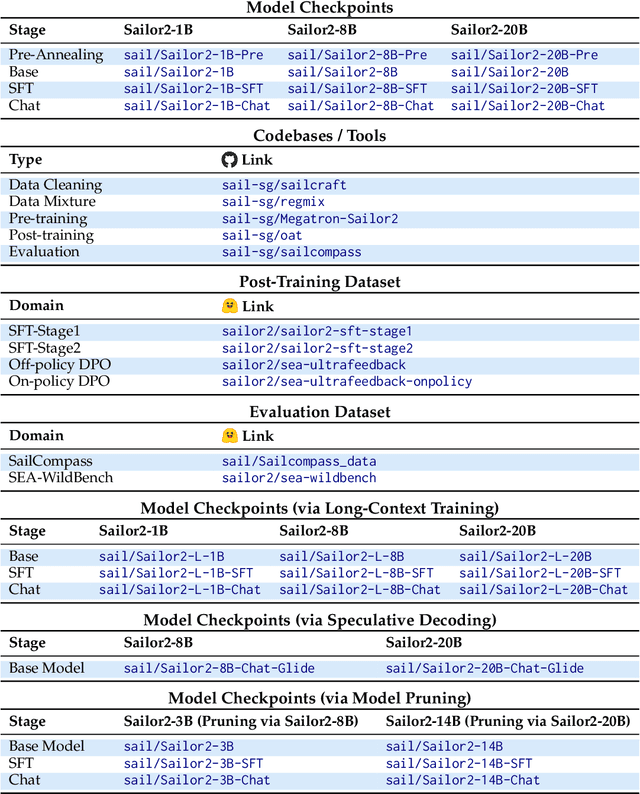

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Can Large Language Models Understand You Better? An MBTI Personality Detection Dataset Aligned with Population Traits
Dec 17, 2024
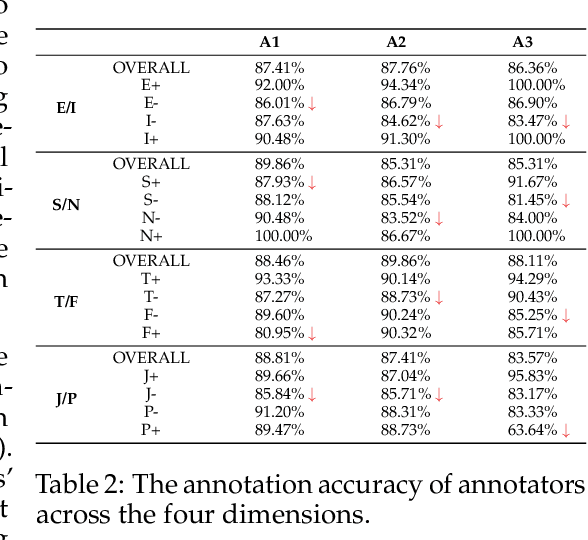
The Myers-Briggs Type Indicator (MBTI) is one of the most influential personality theories reflecting individual differences in thinking, feeling, and behaving. MBTI personality detection has garnered considerable research interest and has evolved significantly over the years. However, this task tends to be overly optimistic, as it currently does not align well with the natural distribution of population personality traits. Specifically, (1) the self-reported labels in existing datasets result in incorrect labeling issues, and (2) the hard labels fail to capture the full range of population personality distributions. In this paper, we optimize the task by constructing MBTIBench, the first manually annotated high-quality MBTI personality detection dataset with soft labels, under the guidance of psychologists. As for the first challenge, MBTIBench effectively solves the incorrect labeling issues, which account for 29.58% of the data. As for the second challenge, we estimate soft labels by deriving the polarity tendency of samples. The obtained soft labels confirm that there are more people with non-extreme personality traits. Experimental results not only highlight the polarized predictions and biases in LLMs as key directions for future research, but also confirm that soft labels can provide more benefits to other psychological tasks than hard labels. The code and data are available at https://github.com/Personality-NLP/MbtiBench.
SCITAT: A Question Answering Benchmark for Scientific Tables and Text Covering Diverse Reasoning Types
Dec 16, 2024



Scientific question answering (SQA) is an important task aimed at answering questions based on papers. However, current SQA datasets have limited reasoning types and neglect the relevance between tables and text, creating a significant gap with real scenarios. To address these challenges, we propose a QA benchmark for scientific tables and text with diverse reasoning types (SciTaT). To cover more reasoning types, we summarize various reasoning types from real-world questions. To involve both tables and text, we require the questions to incorporate tables and text as much as possible. Based on SciTaT, we propose a strong baseline (CaR), which combines various reasoning methods to address different reasoning types and process tables and text at the same time. CaR brings average improvements of 12.9% over other baselines on SciTaT, validating its effectiveness. Error analysis reveals the challenges of SciTaT, such as complex numerical calculations and domain knowledge.
A Survey on Large Language Model-Based Social Agents in Game-Theoretic Scenarios
Dec 05, 2024



Game-theoretic scenarios have become pivotal in evaluating the social intelligence of Large Language Model (LLM)-based social agents. While numerous studies have explored these agents in such settings, there is a lack of a comprehensive survey summarizing the current progress. To address this gap, we systematically review existing research on LLM-based social agents within game-theoretic scenarios. Our survey organizes the findings into three core components: Game Framework, Social Agent, and Evaluation Protocol. The game framework encompasses diverse game scenarios, ranging from choice-focusing to communication-focusing games. The social agent part explores agents' preferences, beliefs, and reasoning abilities. The evaluation protocol covers both game-agnostic and game-specific metrics for assessing agent performance. By reflecting on the current research and identifying future research directions, this survey provides insights to advance the development and evaluation of social agents in game-theoretic scenarios.
SailCompass: Towards Reproducible and Robust Evaluation for Southeast Asian Languages
Dec 02, 2024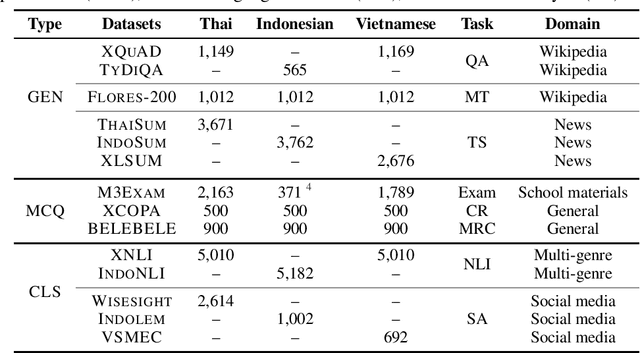
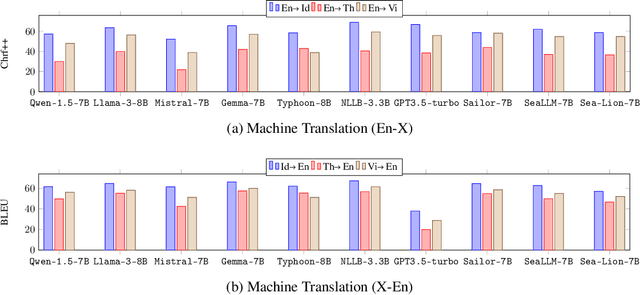
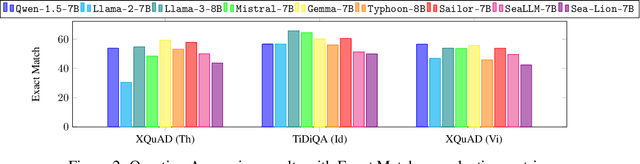
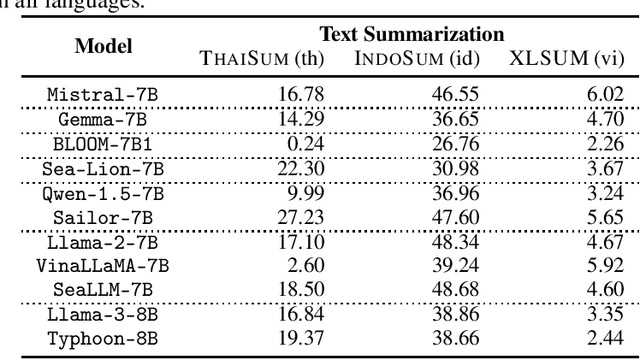
In this paper, we introduce SailCompass, a reproducible and robust evaluation benchmark for assessing Large Language Models (LLMs) on Southeast Asian Languages (SEA). SailCompass encompasses three main SEA languages, eight primary tasks including 14 datasets covering three task types (generation, multiple-choice questions, and classification). To improve the robustness of the evaluation approach, we explore different prompt configurations for multiple-choice questions and leverage calibrations to improve the faithfulness of classification tasks. With SailCompass, we derive the following findings: (1) SEA-specialized LLMs still outperform general LLMs, although the gap has narrowed; (2) A balanced language distribution is important for developing better SEA-specialized LLMs; (3) Advanced prompting techniques (e.g., calibration, perplexity-based ranking) are necessary to better utilize LLMs. All datasets and evaluation scripts are public.
In-Context Transfer Learning: Demonstration Synthesis by Transferring Similar Tasks
Oct 02, 2024

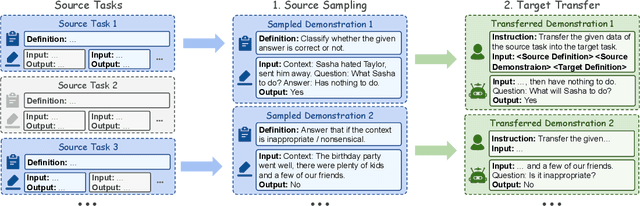

In-context learning (ICL) is an effective approach to help large language models (LLMs) adapt to various tasks by providing demonstrations of the target task. Considering the high cost of labeling demonstrations, many methods propose synthesizing demonstrations from scratch using LLMs. However, the quality of the demonstrations synthesized from scratch is limited by the capabilities and knowledge of LLMs. To address this, inspired by transfer learning, we propose In-Context Transfer Learning (ICTL), which synthesizes target task demonstrations by transferring labeled demonstrations from similar source tasks. ICTL consists of two steps: source sampling and target transfer. First, we define an optimization objective, which minimizes transfer error to sample source demonstrations similar to the target task. Then, we employ LLMs to transfer the sampled source demonstrations to the target task, matching the definition and format of the target task. Experiments on Super-NI show that ICTL outperforms synthesis from scratch by 2.0% on average, demonstrating the effectiveness of our method.