 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Agent Harnesses via Effective Feedback Compute
May 28, 2026Agent harnesses increasingly determine the performance of language-model systems by deciding how models call tools, receive feedback, verify intermediate states, store memory, and revise solutions. Yet current test-time scaling analyses often parameterize this process by raw expenditure -- tokens, tool calls, operations, wall time, or cost -- which does not distinguish useful feedback from redundant or unstable interaction. We introduce \emph{Effective Feedback Compute} (EFC), a trace-level scaling coordinate that credits feedback only when it is informative, valid, non-redundant, and retained for subsequent decisions, and we normalize it by task demand when comparing tasks with different feedback requirements. Across synthetic controllable tasks, executable code tasks, real benchmark traces, held-out splits, and a prospective validation batch, EFC-based coordinates consistently predict failure rates better than raw-compute baselines and a strong multivariate SAS baseline. In controlled scaling, raw tokens and tool calls explain limited variation ($R^2=0.33$ and $0.42$), SAS reaches $0.88$, while Oracle-EFC and Estimated-EFC reach $0.94$ and Oracle-EFC/$D_{\mathrm{task}}$ reaches $0.99$. Matched-budget interventions show that improving feedback quality raises success from $0.27$ to $0.90$ while raw cost and tool calls are fixed. On mixed real traces, NRS-EFC/$D_{\mathrm{task}}$ reaches $R^2=0.92$ while raw compute has near-zero or negative fit, and it remains the best predictor in a prospective holdout ($R^2=0.85$). These results suggest that harness scaling is governed less by how much computation is spent than by how efficiently raw budget is converted into durable, task-sufficient feedback.
When Does Context Help? Error Dynamics of Contextual Information in Large Language Models
Feb 09, 2026Contextual information at inference time, such as demonstrations, retrieved knowledge, or interaction history, can substantially improve large language models (LLMs) without parameter updates, yet its theoretical role remains poorly understood beyond specific settings such as in-context learning (ICL). We present a unified theoretical framework for analyzing the effect of arbitrary contextual information in Transformer-based LLMs. Our analysis characterizes contextual influence through output error dynamics. In a single-layer Transformer, we prove that the context-conditioned error vector decomposes additively into the baseline error vector and a contextual correction vector. This yields necessary geometric conditions for error reduction: the contextual correction must align with the negative baseline error and satisfy a norm constraint. We further show that the contextual correction norm admits an explicit upper bound determined by context-query relevance and complementarity. These results extend to multi-context and multi-layer Transformers. Experiments across ICL, retrieval-augmented generation, and memory evolution validate our theory and motivate a principled context selection strategy that improves performance by $0.6\%$.
How Do Language Models Understand Tables? A Mechanistic Analysis of Cell Location
Feb 09, 2026While Large Language Models (LLMs) are increasingly deployed for table-related tasks, the internal mechanisms enabling them to process linearized two-dimensional structured tables remain opaque. In this work, we investigate the process of table understanding by dissecting the atomic task of cell location. Through activation patching and complementary interpretability techniques, we delineate the table understanding mechanism into a sequential three-stage pipeline: Semantic Binding, Coordinate Localization, and Information Extraction. We demonstrate that models locate the target cell via an ordinal mechanism that counts discrete delimiters to resolve coordinates. Furthermore, column indices are encoded within a linear subspace that allows for precise steering of model focus through vector arithmetic. Finally, we reveal that models generalize to multi-cell location tasks by multiplexing the identical attention heads identified during atomic location. Our findings provide a comprehensive explanation of table understanding within Transformer architectures.
DiscoX: Benchmarking Discourse-Level Translation task in Expert Domains
Nov 14, 2025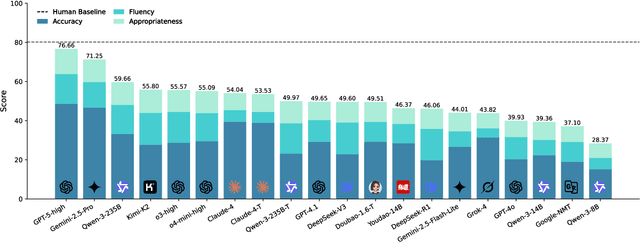

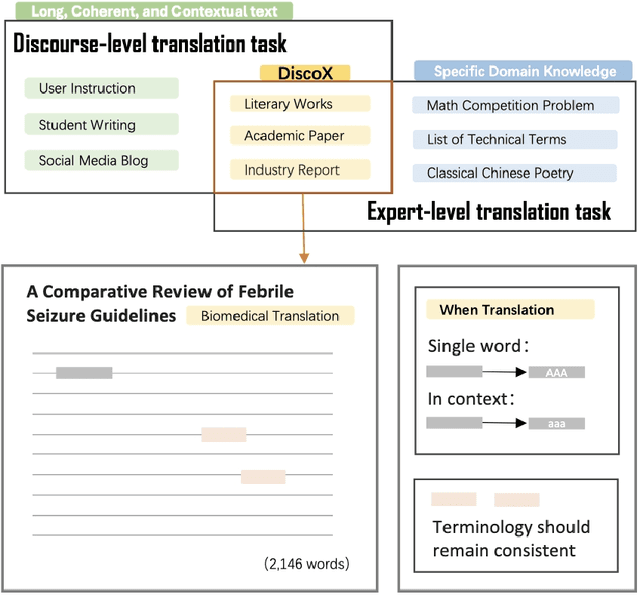

The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
RoT: Enhancing Table Reasoning with Iterative Row-Wise Traversals
May 21, 2025The table reasoning task, crucial for efficient data acquisition, aims to answer questions based on the given table. Recently, reasoning large language models (RLLMs) with Long Chain-of-Thought (Long CoT) significantly enhance reasoning capabilities, leading to brilliant performance on table reasoning. However, Long CoT suffers from high cost for training and exhibits low reliability due to table content hallucinations. Therefore, we propose Row-of-Thought (RoT), which performs iteratively row-wise table traversal, allowing for reasoning extension and reflection-based refinement at each traversal. Scaling reasoning length by row-wise traversal and leveraging reflection capabilities of LLMs, RoT is training-free. The sequential traversal encourages greater attention to the table, thus reducing hallucinations. Experiments show that RoT, using non-reasoning models, outperforms RLLMs by an average of 4.3%, and achieves state-of-the-art results on WikiTableQuestions and TableBench with comparable models, proving its effectiveness. Also, RoT outperforms Long CoT with fewer reasoning tokens, indicating higher efficiency.
Abacus-SQL: A Text-to-SQL System Empowering Cross-Domain and Open-Domain Database Retrieval
Apr 14, 2025The existing text-to-SQL systems have made significant progress in SQL query generation, but they still face numerous challenges. Existing systems often lack retrieval capabilities for open-domain databases, requiring users to manually filter relevant databases. Additionally, their cross-domain transferability is limited, making it challenging to accommodate diverse query requirements. To address these issues, we propose Abacus-SQL. Abacus-SQL utilizes database retrieval technology to accurately locate the required databases in an open-domain database environment. It also enhances the system cross-domain transfer ability through data augmentation methods. Moreover, Abacus-SQL employs Pre-SQL and Self-debug methods, thereby enhancing the accuracy of SQL queries. Experimental results demonstrate that Abacus-SQL performs excellently in multi-turn text-to-SQL tasks, effectively validating the approach's effectiveness. Abacus-SQL is publicly accessible at https://huozi.8wss.com/abacus-sql/.
MULTITAT: Benchmarking Multilingual Table-and-Text Question Answering
Feb 24, 2025Question answering on the hybrid context of tables and text (TATQA) is a critical task, with broad applications in data-intensive domains. However, existing TATQA datasets are limited to English, leading to several drawbacks: (i) They overlook the challenges of multilingual TAT-QA and cannot assess model performance in the multilingual setting. (ii) They do not reflect real-world scenarios where tables and texts frequently appear in non-English languages. To address the limitations, we propose the first multilingual TATQA dataset (MULTITAT). Specifically, we sample data from 3 mainstream TATQA datasets and translate it into 10 diverse languages. To align the model TATQA capabilities in English with other languages, we develop a baseline, Ours. Experimental results reveal that the performance on non-English data in MULTITAT drops by an average of 19.4% compared to English, proving the necessity of MULTITAT. We further analyze the reasons for this performance gap. Furthermore, Ours outperforms other baselines by an average of 3.3, demonstrating its effectiveness.
SCITAT: A Question Answering Benchmark for Scientific Tables and Text Covering Diverse Reasoning Types
Dec 16, 2024



Scientific question answering (SQA) is an important task aimed at answering questions based on papers. However, current SQA datasets have limited reasoning types and neglect the relevance between tables and text, creating a significant gap with real scenarios. To address these challenges, we propose a QA benchmark for scientific tables and text with diverse reasoning types (SciTaT). To cover more reasoning types, we summarize various reasoning types from real-world questions. To involve both tables and text, we require the questions to incorporate tables and text as much as possible. Based on SciTaT, we propose a strong baseline (CaR), which combines various reasoning methods to address different reasoning types and process tables and text at the same time. CaR brings average improvements of 12.9% over other baselines on SciTaT, validating its effectiveness. Error analysis reveals the challenges of SciTaT, such as complex numerical calculations and domain knowledge.