 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoT: Enhancing Table Reasoning with Iterative Row-Wise Traversals
May 21, 2025The table reasoning task, crucial for efficient data acquisition, aims to answer questions based on the given table. Recently, reasoning large language models (RLLMs) with Long Chain-of-Thought (Long CoT) significantly enhance reasoning capabilities, leading to brilliant performance on table reasoning. However, Long CoT suffers from high cost for training and exhibits low reliability due to table content hallucinations. Therefore, we propose Row-of-Thought (RoT), which performs iteratively row-wise table traversal, allowing for reasoning extension and reflection-based refinement at each traversal. Scaling reasoning length by row-wise traversal and leveraging reflection capabilities of LLMs, RoT is training-free. The sequential traversal encourages greater attention to the table, thus reducing hallucinations. Experiments show that RoT, using non-reasoning models, outperforms RLLMs by an average of 4.3%, and achieves state-of-the-art results on WikiTableQuestions and TableBench with comparable models, proving its effectiveness. Also, RoT outperforms Long CoT with fewer reasoning tokens, indicating higher efficiency.
Abacus-SQL: A Text-to-SQL System Empowering Cross-Domain and Open-Domain Database Retrieval
Apr 14, 2025The existing text-to-SQL systems have made significant progress in SQL query generation, but they still face numerous challenges. Existing systems often lack retrieval capabilities for open-domain databases, requiring users to manually filter relevant databases. Additionally, their cross-domain transferability is limited, making it challenging to accommodate diverse query requirements. To address these issues, we propose Abacus-SQL. Abacus-SQL utilizes database retrieval technology to accurately locate the required databases in an open-domain database environment. It also enhances the system cross-domain transfer ability through data augmentation methods. Moreover, Abacus-SQL employs Pre-SQL and Self-debug methods, thereby enhancing the accuracy of SQL queries. Experimental results demonstrate that Abacus-SQL performs excellently in multi-turn text-to-SQL tasks, effectively validating the approach's effectiveness. Abacus-SQL is publicly accessible at https://huozi.8wss.com/abacus-sql/.
MULTITAT: Benchmarking Multilingual Table-and-Text Question Answering
Feb 24, 2025Question answering on the hybrid context of tables and text (TATQA) is a critical task, with broad applications in data-intensive domains. However, existing TATQA datasets are limited to English, leading to several drawbacks: (i) They overlook the challenges of multilingual TAT-QA and cannot assess model performance in the multilingual setting. (ii) They do not reflect real-world scenarios where tables and texts frequently appear in non-English languages. To address the limitations, we propose the first multilingual TATQA dataset (MULTITAT). Specifically, we sample data from 3 mainstream TATQA datasets and translate it into 10 diverse languages. To align the model TATQA capabilities in English with other languages, we develop a baseline, Ours. Experimental results reveal that the performance on non-English data in MULTITAT drops by an average of 19.4% compared to English, proving the necessity of MULTITAT. We further analyze the reasons for this performance gap. Furthermore, Ours outperforms other baselines by an average of 3.3, demonstrating its effectiveness.
Can Large Language Models Understand You Better? An MBTI Personality Detection Dataset Aligned with Population Traits
Dec 17, 2024
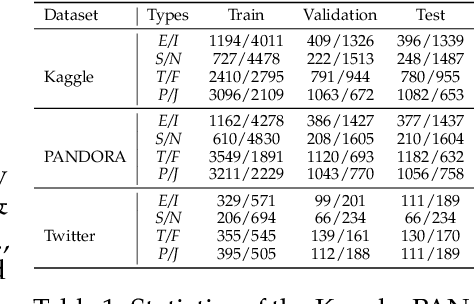
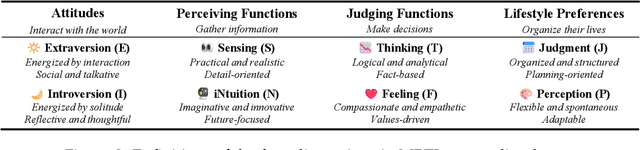
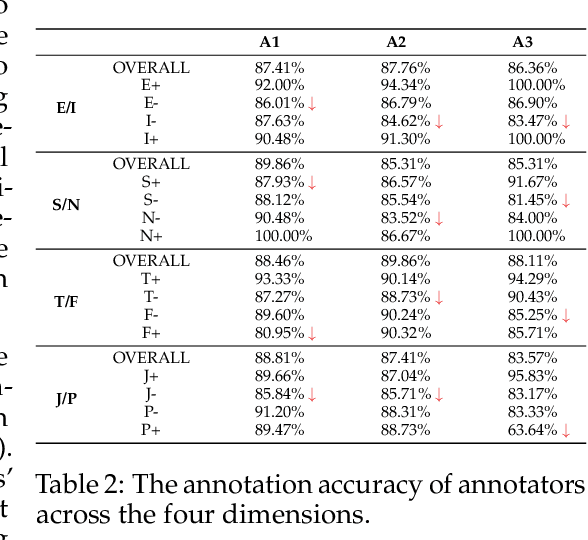
The Myers-Briggs Type Indicator (MBTI) is one of the most influential personality theories reflecting individual differences in thinking, feeling, and behaving. MBTI personality detection has garnered considerable research interest and has evolved significantly over the years. However, this task tends to be overly optimistic, as it currently does not align well with the natural distribution of population personality traits. Specifically, (1) the self-reported labels in existing datasets result in incorrect labeling issues, and (2) the hard labels fail to capture the full range of population personality distributions. In this paper, we optimize the task by constructing MBTIBench, the first manually annotated high-quality MBTI personality detection dataset with soft labels, under the guidance of psychologists. As for the first challenge, MBTIBench effectively solves the incorrect labeling issues, which account for 29.58% of the data. As for the second challenge, we estimate soft labels by deriving the polarity tendency of samples. The obtained soft labels confirm that there are more people with non-extreme personality traits. Experimental results not only highlight the polarized predictions and biases in LLMs as key directions for future research, but also confirm that soft labels can provide more benefits to other psychological tasks than hard labels. The code and data are available at https://github.com/Personality-NLP/MbtiBench.
SCITAT: A Question Answering Benchmark for Scientific Tables and Text Covering Diverse Reasoning Types
Dec 16, 2024



Scientific question answering (SQA) is an important task aimed at answering questions based on papers. However, current SQA datasets have limited reasoning types and neglect the relevance between tables and text, creating a significant gap with real scenarios. To address these challenges, we propose a QA benchmark for scientific tables and text with diverse reasoning types (SciTaT). To cover more reasoning types, we summarize various reasoning types from real-world questions. To involve both tables and text, we require the questions to incorporate tables and text as much as possible. Based on SciTaT, we propose a strong baseline (CaR), which combines various reasoning methods to address different reasoning types and process tables and text at the same time. CaR brings average improvements of 12.9% over other baselines on SciTaT, validating its effectiveness. Error analysis reveals the challenges of SciTaT, such as complex numerical calculations and domain knowledge.
In-Context Transfer Learning: Demonstration Synthesis by Transferring Similar Tasks
Oct 02, 2024

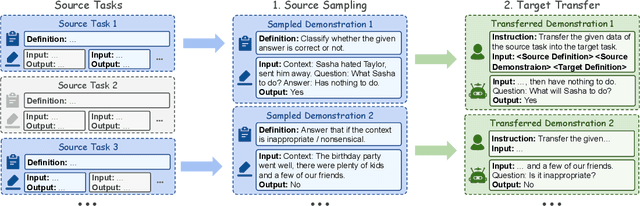

In-context learning (ICL) is an effective approach to help large language models (LLMs) adapt to various tasks by providing demonstrations of the target task. Considering the high cost of labeling demonstrations, many methods propose synthesizing demonstrations from scratch using LLMs. However, the quality of the demonstrations synthesized from scratch is limited by the capabilities and knowledge of LLMs. To address this, inspired by transfer learning, we propose In-Context Transfer Learning (ICTL), which synthesizes target task demonstrations by transferring labeled demonstrations from similar source tasks. ICTL consists of two steps: source sampling and target transfer. First, we define an optimization objective, which minimizes transfer error to sample source demonstrations similar to the target task. Then, we employ LLMs to transfer the sampled source demonstrations to the target task, matching the definition and format of the target task. Experiments on Super-NI show that ICTL outperforms synthesis from scratch by 2.0% on average, demonstrating the effectiveness of our method.
FLEXTAF: Enhancing Table Reasoning with Flexible Tabular Formats
Aug 16, 2024
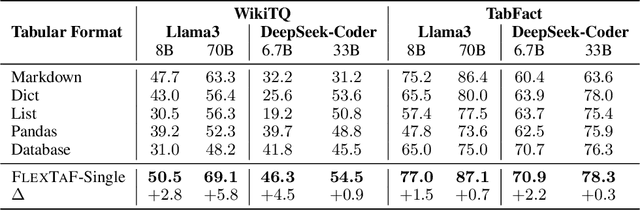
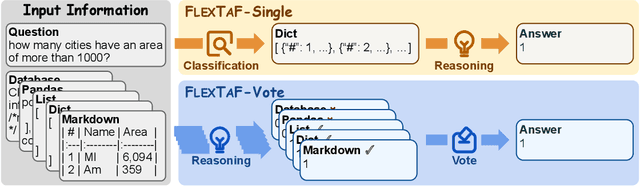
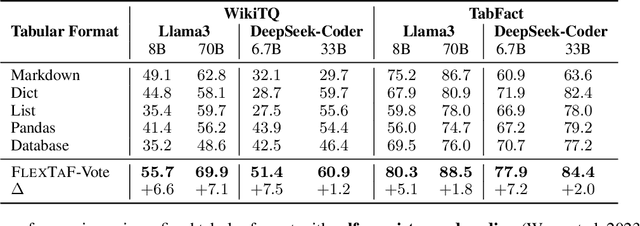
The table reasoning task aims to answer the question according to the given table. Currently, using Large Language Models (LLMs) is the predominant method for table reasoning. Most existing methods employ a fixed tabular format to represent the table, which could limit the performance. Given that each instance requires different capabilities and models possess varying abilities, we assert that different instances and models suit different tabular formats. We prove the aforementioned claim through quantitative analysis of experimental results, where different instances and models achieve different performances using various tabular formats. Building on this discussion, we propose FLEXTAF-Single and FLEXTAF-Vote to enhance table reasoning performance by employing flexible tabular formats. Specifically, (i) FLEXTAF-Single trains a classifier to predict the most suitable tabular format based on the instance and the LLM. (ii) FLEXTAF-Vote integrates the results across different formats. Our experiments on WikiTableQuestions and TabFact reveal significant improvements, with average gains of 2.3% and 4.8% compared to the best performance achieved using a fixed tabular format with greedy decoding and self-consistency decoding, thereby validating the effectiveness of our methods.
DAC: Decomposed Automation Correction for Text-to-SQL
Aug 16, 2024



Text-to-SQL is an important task that helps people obtain information from databases by automatically generating SQL queries. Considering the brilliant performance, approaches based on Large Language Models (LLMs) become the mainstream for text-to-SQL. Among these approaches, automated correction is an effective approach that further enhances performance by correcting the mistakes in the generated results. The existing correction methods require LLMs to directly correct with generated SQL, while previous research shows that LLMs do not know how to detect mistakes, leading to poor performance. Therefore, in this paper, we propose to employ the decomposed correction to enhance text-to-SQL performance. We first demonstrate that decomposed correction outperforms direct correction since detecting and fixing mistakes with the results of the decomposed sub-tasks is easier than with SQL. Based on this analysis, we introduce Decomposed Automation Correction (DAC), which corrects SQL by decomposing text-to-SQL into entity linking and skeleton parsing. DAC first generates the entity and skeleton corresponding to the question and then compares the differences between the initial SQL and the generated entities and skeleton as feedback for correction. Experimental results show that our method improves performance by $3.7\%$ on average of Spider, Bird, and KaggleDBQA compared with the baseline method, demonstrating the effectiveness of DAC.
Enhancing Numerical Reasoning with the Guidance of Reliable Reasoning Processes
Feb 16, 2024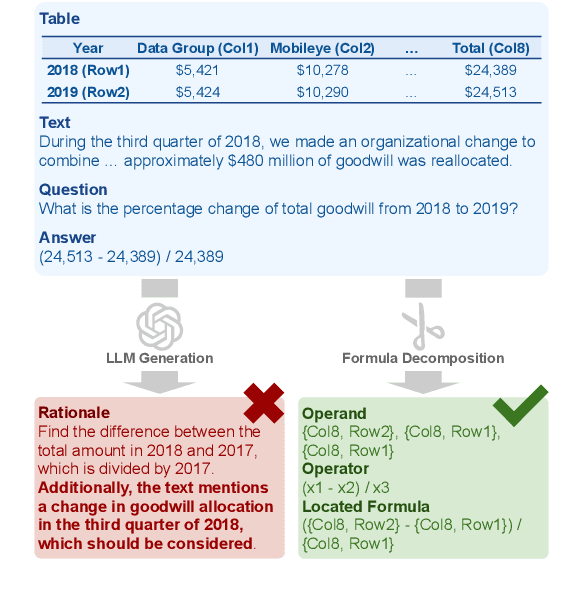



Numerical reasoning is an essential ability for NLP systems to handle numeric information. Recent research indicates that fine-tuning a small-scale model to learn generating reasoning processes alongside answers can significantly enhance performance. However, current methods have the limitation that most methods generate reasoning processes with large language models (LLMs), which are "unreliable" since such processes could contain information unrelated to the answer. To address this limitation, we introduce Enhancing NumeriCal reasOning with Reliable procEsses (Encore), which derives the reliable reasoning process by decomposing the answer formula, ensuring which fully supports the answer. Nevertheless, models could lack enough data to learn the reasoning process generation adequately, since our method generates only one single reasoning process for one formula. To overcome this difficulty, we present a series of pre-training tasks to help models learn the reasoning process generation with synthesized data. The experiments show that Encore yields improvement on all five experimental datasets with an average of 1.8%, proving the effectiveness of our method.
Improving Demonstration Diversity by Human-Free Fusing for Text-to-SQL
Feb 16, 2024Currently, the in-context learning method based on large language models (LLMs) has become the mainstream of text-to-SQL research. Previous works have discussed how to select demonstrations related to the user question from a human-labeled demonstration pool. However, human labeling suffers from the limitations of insufficient diversity and high labeling overhead. Therefore, in this paper, we discuss how to measure and improve the diversity of the demonstrations for text-to-SQL. We present a metric to measure the diversity of the demonstrations and analyze the insufficient of the existing labeled data by experiments. Based on the above discovery, we propose fusing iteratively for demonstrations (Fused) to build a high-diversity demonstration pool through human-free multiple-iteration synthesis, improving diversity and lowering label cost. Our method achieves an average improvement of 3.2% and 5.0% with and without human labeling on several mainstream datasets, which proves the effectiveness of Fused.