 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Coding Agents via Atomic Skills
Apr 06, 2026Current LLM coding agents are predominantly trained on composite benchmarks (e.g., bug fixing), which often leads to task-specific overfitting and limited generalization. To address this, we propose a novel scaling paradigm that shifts the focus from task-level optimization to atomic skill mastery. We first formalize five fundamental atomic skills, code localization, code editing, unit-test generation, issue reproduction, and code review, that serve as the basis vectors for complex software engineering tasks. Compared with composite coding tasks, these atomic skills are more generalizable and composable. Then, we scale coding agents by performing joint RL over atomic skills. In this manner, atomic skills are consistently improved without negative interference or trade-offs between them. Notably, we observe that improvements in these atomic skills generalize well to other unseen composite coding tasks, such as bug-fixing, code refactoring, machine learning engineering, and code security. The observation motivates a new scaling paradigm for coding agents by training with atomic skills. Extensive experiments demonstrate the effectiveness of our proposed paradigm. Notably, our joint RL improves average performance by 18.7% on 5 atomic skills and 5 composite tasks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
DockSmith: Scaling Reliable Coding Environments via an Agentic Docker Builder
Jan 31, 2026Reliable Docker-based environment construction is a dominant bottleneck for scaling execution-grounded training and evaluation of software engineering agents. We introduce DockSmith, a specialized agentic Docker builder designed to address this challenge. DockSmith treats environment construction not only as a preprocessing step, but as a core agentic capability that exercises long-horizon tool use, dependency reasoning, and failure recovery, yielding supervision that transfers beyond Docker building itself. DockSmith is trained on large-scale, execution-grounded Docker-building trajectories produced by a SWE-Factory-style pipeline augmented with a loop-detection controller and a cross-task success memory. Training a 30B-A3B model on these trajectories achieves open-source state-of-the-art performance on Multi-Docker-Eval, with 39.72% Fail-to-Pass and 58.28% Commit Rate. Moreover, DockSmith improves out-of-distribution performance on SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0, demonstrating broader agentic benefits of environment construction.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Efficient Reasoning via Chain of Unconscious Thought
May 26, 2025Large Reasoning Models (LRMs) achieve promising performance but compromise token efficiency due to verbose reasoning processes. Unconscious Thought Theory (UTT) posits that complex problems can be solved more efficiently through internalized cognitive processes. Inspired by UTT, we propose a new reasoning paradigm, termed Chain of Unconscious Thought (CoUT), to improve the token efficiency of LRMs by guiding them to mimic human unconscious thought and internalize reasoning processes. Concretely, we first prompt the model to internalize the reasoning by thinking in the hidden layer. Then, we design a bag of token-efficient strategies to further help models reduce unnecessary tokens yet preserve the performance. Our work reveals that models may possess beneficial unconscious thought, enabling improved efficiency without sacrificing performance. Extensive experiments demonstrate the effectiveness of CoUT. Remarkably, it surpasses CoT by reducing token usage by 47.62% while maintaining comparable accuracy, as shown in Figure 1. The code of CoUT is available at this link: https://github.com/Rohan-GRH/CoUT
Thinking Longer, Not Larger: Enhancing Software Engineering Agents via Scaling Test-Time Compute
Mar 31, 2025Recent advancements in software engineering agents have demonstrated promising capabilities in automating program improvements. However, their reliance on closed-source or resource-intensive models introduces significant deployment challenges in private environments, prompting a critical question: \textit{How can personally deployable open-source LLMs achieve comparable code reasoning performance?} To this end, we propose a unified Test-Time Compute scaling framework that leverages increased inference-time computation instead of larger models. Our framework incorporates two complementary strategies: internal TTC and external TTC. Internally, we introduce a \textit{development-contextualized trajectory synthesis} method leveraging real-world software repositories to bootstrap multi-stage reasoning processes, such as fault localization and patch generation. We further enhance trajectory quality through rejection sampling, rigorously evaluating trajectories along accuracy and complexity. Externally, we propose a novel \textit{development-process-based search} strategy guided by reward models and execution verification. This approach enables targeted computational allocation at critical development decision points, overcoming limitations of existing "end-point only" verification methods. Evaluations on SWE-bench Verified demonstrate our \textbf{32B model achieves a 46\% issue resolution rate}, surpassing significantly larger models such as DeepSeek R1 671B and OpenAI o1. Additionally, we provide the empirical validation of the test-time scaling phenomenon within SWE agents, revealing that \textbf{models dynamically allocate more tokens to increasingly challenging problems}, effectively enhancing reasoning capabilities. We publicly release all training data, models, and code to facilitate future research. https://github.com/yingweima2022/SWE-Reasoner
LLMs as Continuous Learners: Improving the Reproduction of Defective Code in Software Issues
Nov 21, 2024



Reproducing buggy code is the first and crucially important step in issue resolving, as it aids in identifying the underlying problems and validating that generated patches resolve the problem. While numerous approaches have been proposed for this task, they primarily address common, widespread errors and struggle to adapt to unique, evolving errors specific to individual code repositories. To fill this gap, we propose EvoCoder, a multi-agent continuous learning framework for issue code reproduction. EvoCoder adopts a reflection mechanism that allows the LLM to continuously learn from previously resolved problems and dynamically refine its strategies to new emerging challenges. To prevent experience bloating, EvoCoder introduces a novel hierarchical experience pool that enables the model to adaptively update common and repo-specific experiences. Our experimental results show a 20\% improvement in issue reproduction rates over existing SOTA methods. Furthermore, integrating our reproduction mechanism significantly boosts the overall accuracy of the existing issue-resolving pipeline.
Lingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement
Nov 01, 2024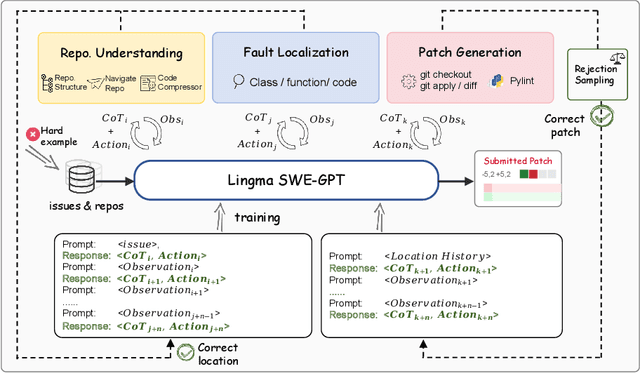


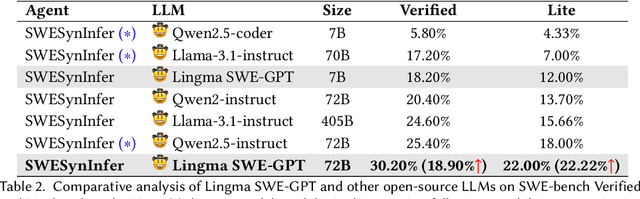
Recent advancements in LLM-based agents have led to significant progress in automatic software engineering, particularly in software maintenance and evolution. Despite these encouraging advances, current research faces two major challenges. First, SOTA performance primarily depends on closed-source models, which significantly limits the technology's accessibility, and potential for customization in diverse SE tasks. Second, these models are predominantly trained on static code data, lacking a deep understanding of the dynamic interactions, iterative problem-solving processes, and evolutionary characteristics inherent in software development. To address these challenges, our study adopts a software engineering perspective. We recognize that real-world software maintenance and evolution processes encompass not only static code data but also developers' thought processes, utilization of external tools, and the interaction between different functional personnel. Consequently, we introduce the Lingma SWE-GPT series, comprising Lingma SWE-GPT 7B and 72B. By learning from and simulating real-world code submission activities, Lingma SWE-GPT systematically incorporates the dynamic interactions and iterative problem-solving inherent in software development process, thereby achieving a more comprehensive understanding of software improvement processes. We conducted experimental evaluations using SWE-bench Verified benchmark. The results demonstrate that Lingma SWE-GPT 72B successfully resolves 30.20% of the GitHub issues, marking a significant improvement in automatic issue resolution (22.76% relative improvement compared to Llama 3.1 405B), approaching the performance of closed-source models (31.80\% issues of GPT-4o resolved). Notably, Lingma SWE-GPT 7B resolves 18.20% of the issues, highlighting the potential for applying smaller models to ASE tasks.
Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion?
Oct 02, 2024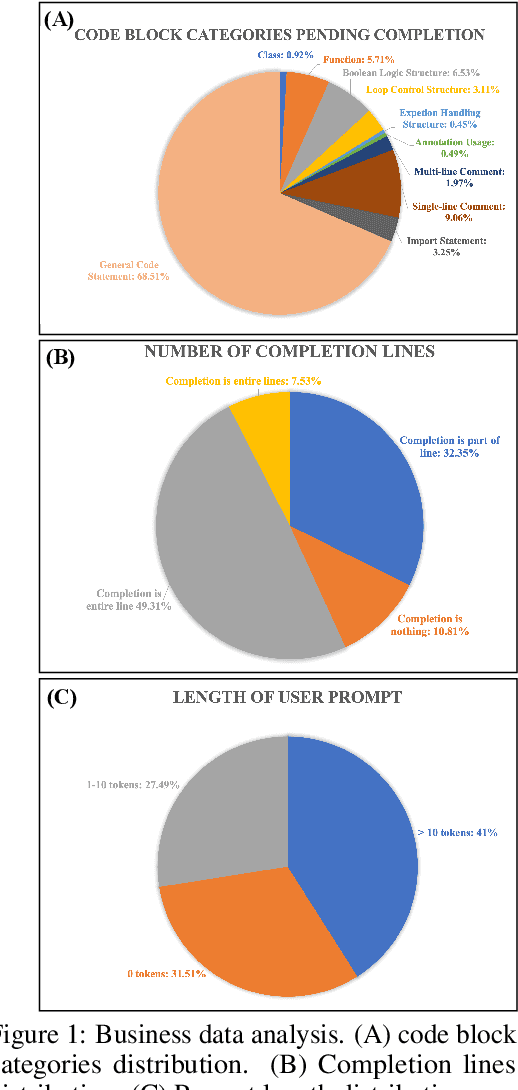

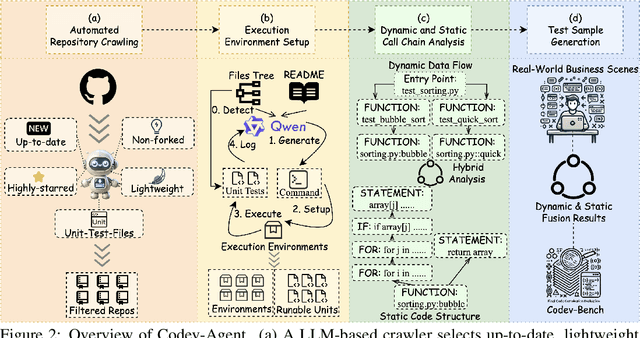
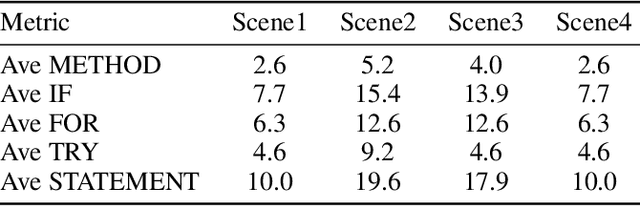
Code completion, a key downstream task in code generation, is one of the most frequent and impactful methods for enhancing developer productivity in software development. As intelligent completion tools evolve, we need a robust evaluation benchmark that enables meaningful comparisons between products and guides future advancements. However, existing benchmarks focus more on coarse-grained tasks without industrial analysis resembling general code generation rather than the real-world scenarios developers encounter. Moreover, these benchmarks often rely on costly and time-consuming human annotation, and the standalone test cases fail to leverage minimal tests for maximum repository-level understanding and code coverage. To address these limitations, we first analyze business data from an industrial code completion tool and redefine the evaluation criteria to better align with the developer's intent and desired completion behavior throughout the coding process. Based on these insights, we introduce Codev-Agent, an agent-based system that automates repository crawling, constructs execution environments, extracts dynamic calling chains from existing unit tests, and generates new test samples to avoid data leakage, ensuring fair and effective comparisons. Using Codev-Agent, we present the Code-Development Benchmark (Codev-Bench), a fine-grained, real-world, repository-level, and developer-centric evaluation framework. Codev-Bench assesses whether a code completion tool can capture a developer's immediate intent and suggest appropriate code across diverse contexts, providing a more realistic benchmark for code completion in modern software development.