 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement
Nov 01, 2024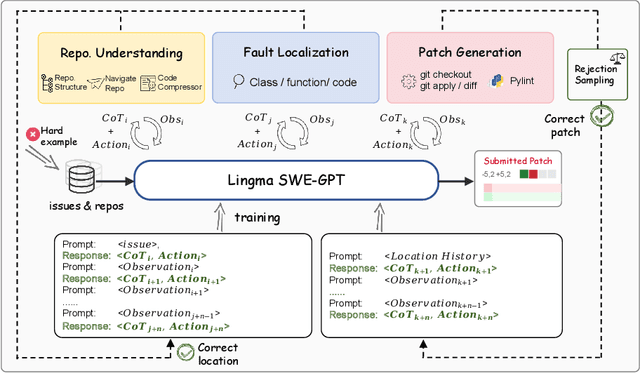


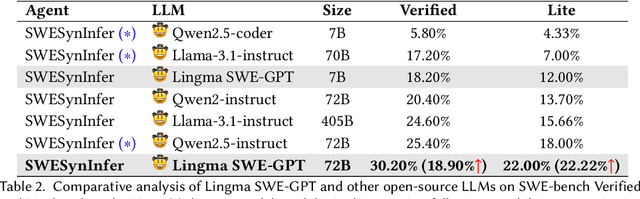
Recent advancements in LLM-based agents have led to significant progress in automatic software engineering, particularly in software maintenance and evolution. Despite these encouraging advances, current research faces two major challenges. First, SOTA performance primarily depends on closed-source models, which significantly limits the technology's accessibility, and potential for customization in diverse SE tasks. Second, these models are predominantly trained on static code data, lacking a deep understanding of the dynamic interactions, iterative problem-solving processes, and evolutionary characteristics inherent in software development. To address these challenges, our study adopts a software engineering perspective. We recognize that real-world software maintenance and evolution processes encompass not only static code data but also developers' thought processes, utilization of external tools, and the interaction between different functional personnel. Consequently, we introduce the Lingma SWE-GPT series, comprising Lingma SWE-GPT 7B and 72B. By learning from and simulating real-world code submission activities, Lingma SWE-GPT systematically incorporates the dynamic interactions and iterative problem-solving inherent in software development process, thereby achieving a more comprehensive understanding of software improvement processes. We conducted experimental evaluations using SWE-bench Verified benchmark. The results demonstrate that Lingma SWE-GPT 72B successfully resolves 30.20% of the GitHub issues, marking a significant improvement in automatic issue resolution (22.76% relative improvement compared to Llama 3.1 405B), approaching the performance of closed-source models (31.80\% issues of GPT-4o resolved). Notably, Lingma SWE-GPT 7B resolves 18.20% of the issues, highlighting the potential for applying smaller models to ASE tasks.
Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion?
Oct 02, 2024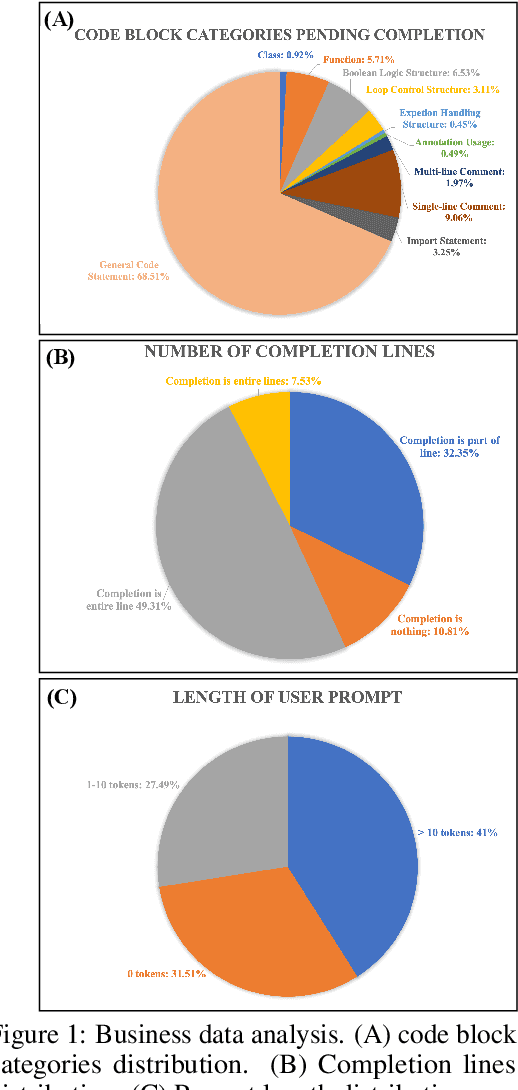

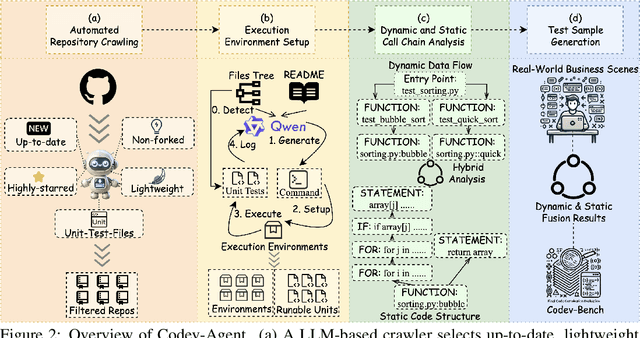
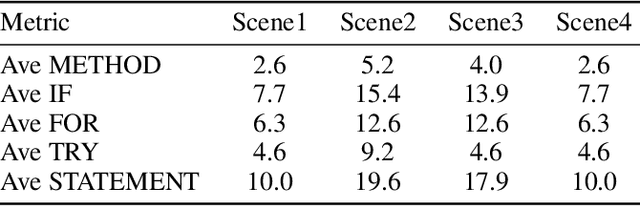
Code completion, a key downstream task in code generation, is one of the most frequent and impactful methods for enhancing developer productivity in software development. As intelligent completion tools evolve, we need a robust evaluation benchmark that enables meaningful comparisons between products and guides future advancements. However, existing benchmarks focus more on coarse-grained tasks without industrial analysis resembling general code generation rather than the real-world scenarios developers encounter. Moreover, these benchmarks often rely on costly and time-consuming human annotation, and the standalone test cases fail to leverage minimal tests for maximum repository-level understanding and code coverage. To address these limitations, we first analyze business data from an industrial code completion tool and redefine the evaluation criteria to better align with the developer's intent and desired completion behavior throughout the coding process. Based on these insights, we introduce Codev-Agent, an agent-based system that automates repository crawling, constructs execution environments, extracts dynamic calling chains from existing unit tests, and generates new test samples to avoid data leakage, ensuring fair and effective comparisons. Using Codev-Agent, we present the Code-Development Benchmark (Codev-Bench), a fine-grained, real-world, repository-level, and developer-centric evaluation framework. Codev-Bench assesses whether a code completion tool can capture a developer's immediate intent and suggest appropriate code across diverse contexts, providing a more realistic benchmark for code completion in modern software development.
Make BERT-based Chinese Spelling Check Model Enhanced by Layerwise Attention and Gaussian Mixture Model
Dec 27, 2023BERT-based models have shown a remarkable ability in the Chinese Spelling Check (CSC) task recently. However, traditional BERT-based methods still suffer from two limitations. First, although previous works have identified that explicit prior knowledge like Part-Of-Speech (POS) tagging can benefit in the CSC task, they neglected the fact that spelling errors inherent in CSC data can lead to incorrect tags and therefore mislead models. Additionally, they ignored the correlation between the implicit hierarchical information encoded by BERT's intermediate layers and different linguistic phenomena. This results in sub-optimal accuracy. To alleviate the above two issues, we design a heterogeneous knowledge-infused framework to strengthen BERT-based CSC models. To incorporate explicit POS knowledge, we utilize an auxiliary task strategy driven by Gaussian mixture model. Meanwhile, to incorporate implicit hierarchical linguistic knowledge within the encoder, we propose a novel form of n-gram-based layerwise self-attention to generate a multilayer representation. Experimental results show that our proposed framework yields a stable performance boost over four strong baseline models and outperforms the previous state-of-the-art methods on two datasets.
* 10 pages, 4 figures, 2023 International Joint Conference on Neural Networks (IJCNN)