 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodev-Bench: How Do LLMs Understand Developer-Centric Code Completion?
Paper and Code
Oct 02, 2024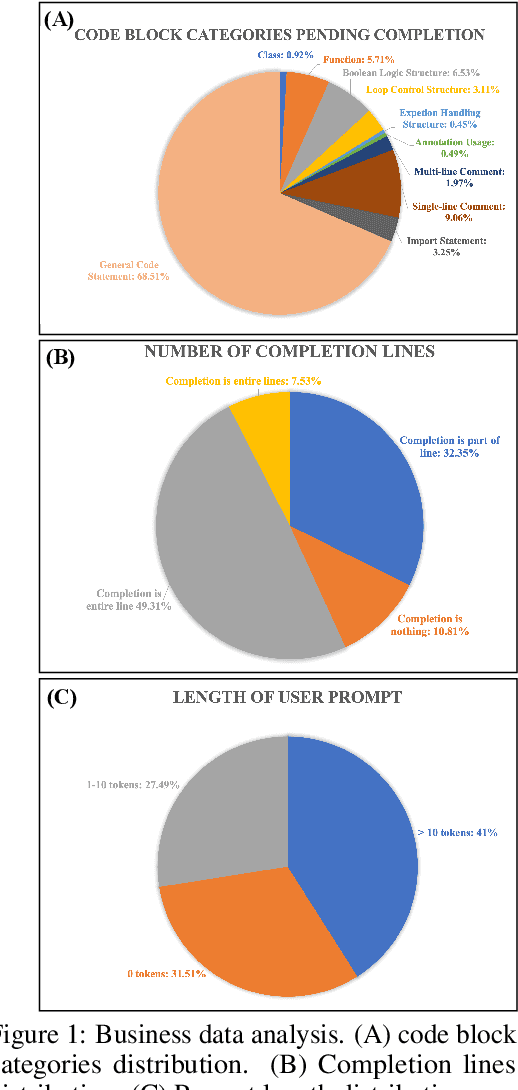

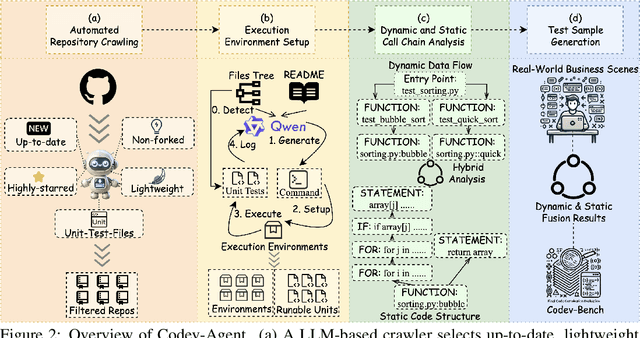
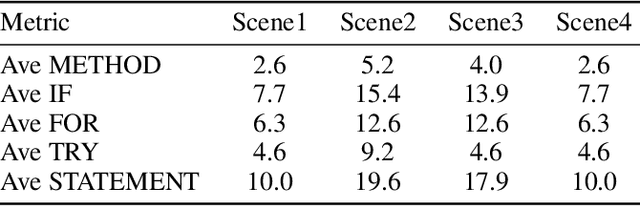
Code completion, a key downstream task in code generation, is one of the most frequent and impactful methods for enhancing developer productivity in software development. As intelligent completion tools evolve, we need a robust evaluation benchmark that enables meaningful comparisons between products and guides future advancements. However, existing benchmarks focus more on coarse-grained tasks without industrial analysis resembling general code generation rather than the real-world scenarios developers encounter. Moreover, these benchmarks often rely on costly and time-consuming human annotation, and the standalone test cases fail to leverage minimal tests for maximum repository-level understanding and code coverage. To address these limitations, we first analyze business data from an industrial code completion tool and redefine the evaluation criteria to better align with the developer's intent and desired completion behavior throughout the coding process. Based on these insights, we introduce Codev-Agent, an agent-based system that automates repository crawling, constructs execution environments, extracts dynamic calling chains from existing unit tests, and generates new test samples to avoid data leakage, ensuring fair and effective comparisons. Using Codev-Agent, we present the Code-Development Benchmark (Codev-Bench), a fine-grained, real-world, repository-level, and developer-centric evaluation framework. Codev-Bench assesses whether a code completion tool can capture a developer's immediate intent and suggest appropriate code across diverse contexts, providing a more realistic benchmark for code completion in modern software development.