 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025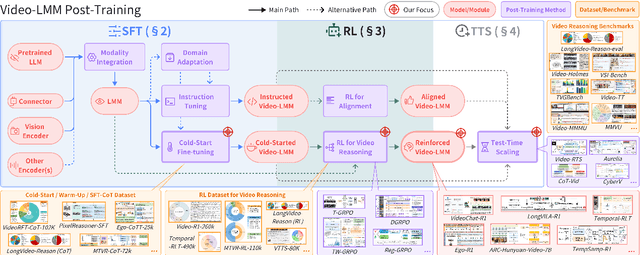
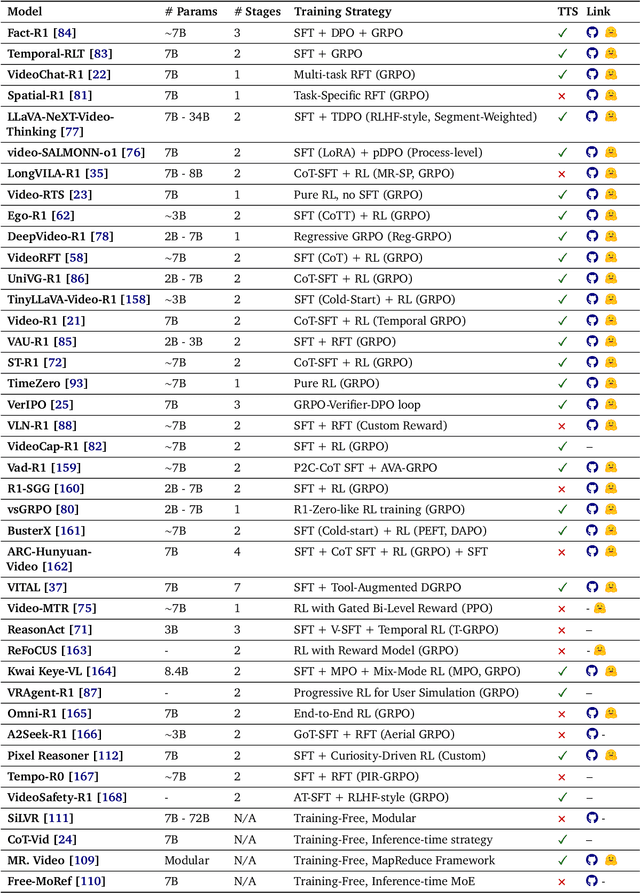
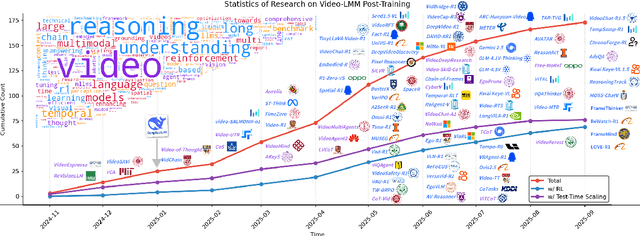
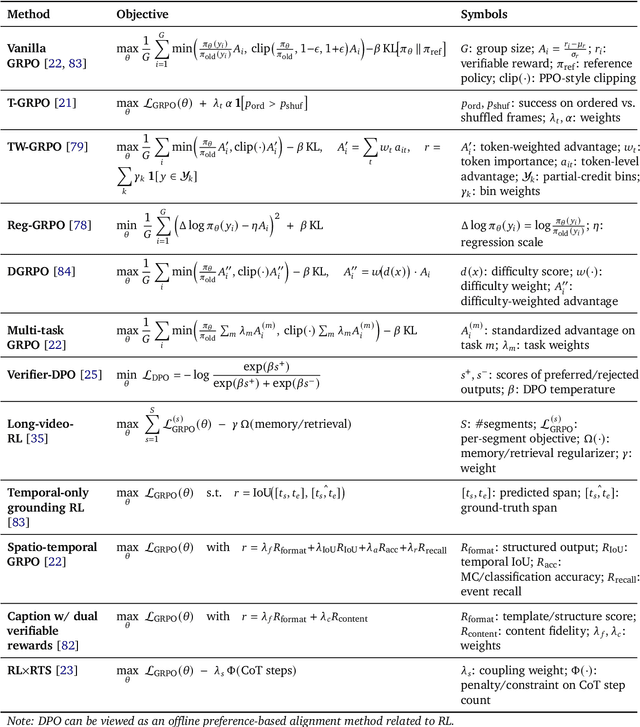
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025



LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
SciSciGPT: Advancing Human-AI Collaboration in the Science of Science
Apr 07, 2025



The increasing availability of large-scale datasets has fueled rapid progress across many scientific fields, creating unprecedented opportunities for research and discovery while posing significant analytical challenges. Recent advances in large language models (LLMs) and AI agents have opened new possibilities for human-AI collaboration, offering powerful tools to navigate this complex research landscape. In this paper, we introduce SciSciGPT, an open-source, prototype AI collaborator that uses the science of science as a testbed to explore the potential of LLM-powered research tools. SciSciGPT automates complex workflows, supports diverse analytical approaches, accelerates research prototyping and iteration, and facilitates reproducibility. Through case studies, we demonstrate its ability to streamline a wide range of empirical and analytical research tasks while highlighting its broader potential to advance research. We further propose an LLM Agent capability maturity model for human-AI collaboration, envisioning a roadmap to further improve and expand upon frameworks like SciSciGPT. As AI capabilities continue to evolve, frameworks like SciSciGPT may play increasingly pivotal roles in scientific research and discovery, unlocking further opportunities. At the same time, these new advances also raise critical challenges, from ensuring transparency and ethical use to balancing human and AI contributions. Addressing these issues may shape the future of scientific inquiry and inform how we train the next generation of scientists to thrive in an increasingly AI-integrated research ecosystem.
Do Code LLMs Understand Design Patterns?
Jan 08, 2025

Code Large Language Models (LLMs) demonstrate great versatility in adapting to various downstream tasks, including code generation and completion, as well as bug detection and fixing. However, Code LLMs often fail to capture existing coding standards, leading to the generation of code that conflicts with the required design patterns for a given project. As a result, developers must post-process to adapt the generated code to the project's design norms. In this work, we empirically investigate the biases of Code LLMs in software development. Through carefully designed experiments, we assess the models' understanding of design patterns across recognition, comprehension, and generation. Our findings reveal that biases in Code LLMs significantly affect the reliability of downstream tasks.
Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion?
Oct 02, 2024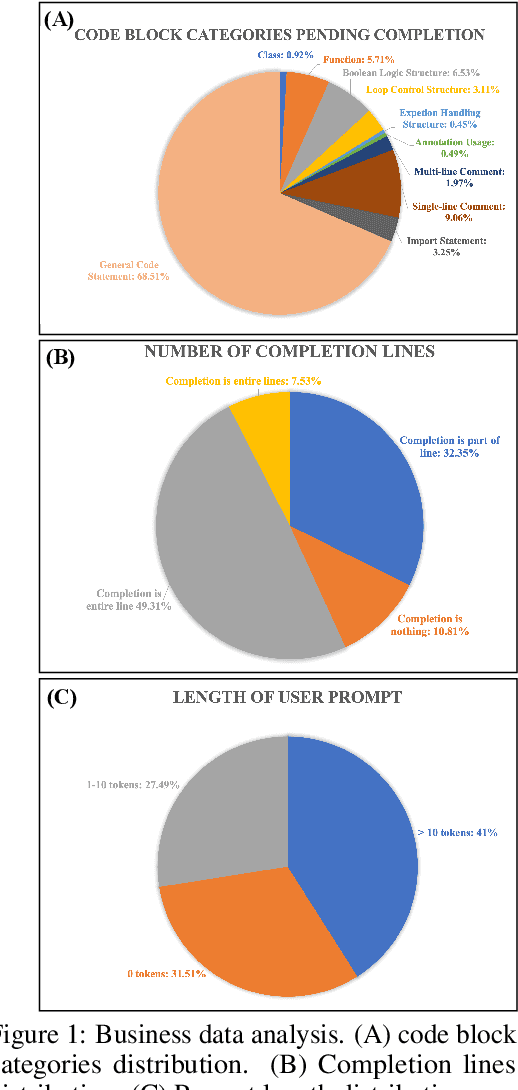

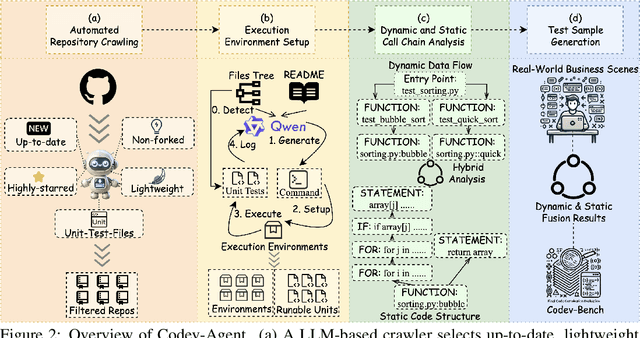
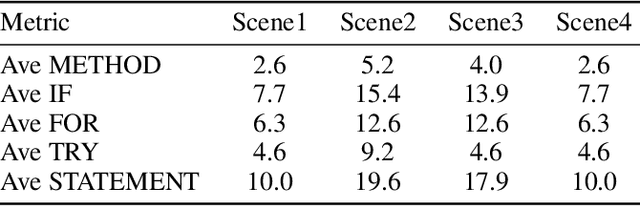
Code completion, a key downstream task in code generation, is one of the most frequent and impactful methods for enhancing developer productivity in software development. As intelligent completion tools evolve, we need a robust evaluation benchmark that enables meaningful comparisons between products and guides future advancements. However, existing benchmarks focus more on coarse-grained tasks without industrial analysis resembling general code generation rather than the real-world scenarios developers encounter. Moreover, these benchmarks often rely on costly and time-consuming human annotation, and the standalone test cases fail to leverage minimal tests for maximum repository-level understanding and code coverage. To address these limitations, we first analyze business data from an industrial code completion tool and redefine the evaluation criteria to better align with the developer's intent and desired completion behavior throughout the coding process. Based on these insights, we introduce Codev-Agent, an agent-based system that automates repository crawling, constructs execution environments, extracts dynamic calling chains from existing unit tests, and generates new test samples to avoid data leakage, ensuring fair and effective comparisons. Using Codev-Agent, we present the Code-Development Benchmark (Codev-Bench), a fine-grained, real-world, repository-level, and developer-centric evaluation framework. Codev-Bench assesses whether a code completion tool can capture a developer's immediate intent and suggest appropriate code across diverse contexts, providing a more realistic benchmark for code completion in modern software development.
Conv-CoA: Improving Open-domain Question Answering in Large Language Models via Conversational Chain-of-Action
May 28, 2024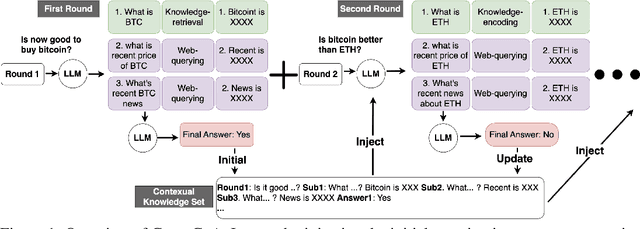
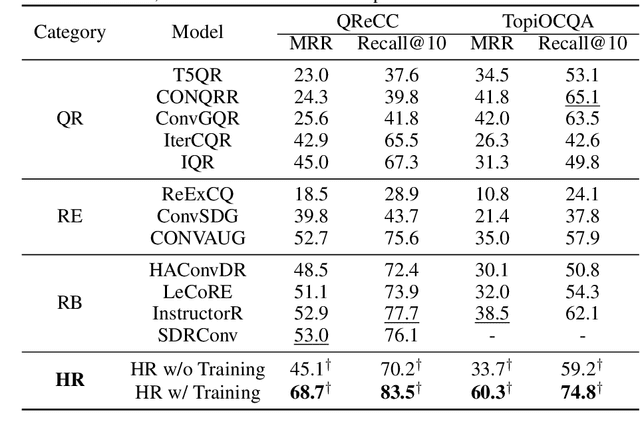

We present a Conversational Chain-of-Action (Conv-CoA) framework for Open-domain Conversational Question Answering (OCQA). Compared with literature, Conv-CoA addresses three major challenges: (i) unfaithful hallucination that is inconsistent with real-time or domain facts, (ii) weak reasoning performance in conversational scenarios, and (iii) unsatisfying performance in conversational information retrieval. Our key contribution is a dynamic reasoning-retrieval mechanism that extracts the intent of the question and decomposes it into a reasoning chain to be solved via systematic prompting, pre-designed actions, updating the Contextual Knowledge Set (CKS), and a novel Hopfield-based retriever. Methodologically, we propose a resource-efficiency Hopfield retriever to enhance the efficiency and accuracy of conversational information retrieval within our actions. Additionally, we propose a conversational-multi-reference faith score (Conv-MRFS) to verify and resolve conflicts between retrieved knowledge and answers in conversations. Empirically, we conduct comparisons between our framework and 23 state-of-the-art methods across five different research directions and two public benchmarks. These comparisons demonstrate that our Conv-CoA outperforms other methods in both the accuracy and efficiency dimensions.
HeteGraph-Mamba: Heterogeneous Graph Learning via Selective State Space Model
May 22, 2024

We propose a heterogeneous graph mamba network (HGMN) as the first exploration in leveraging the selective state space models (SSSMs) for heterogeneous graph learning. Compared with the literature, our HGMN overcomes two major challenges: (i) capturing long-range dependencies among heterogeneous nodes and (ii) adapting SSSMs to heterogeneous graph data. Our key contribution is a general graph architecture that can solve heterogeneous nodes in real-world scenarios, followed an efficient flow. Methodologically, we introduce a two-level efficient tokenization approach that first captures long-range dependencies within identical node types, and subsequently across all node types. Empirically, we conduct comparisons between our framework and 19 state-of-the-art methods on the heterogeneous benchmarks. The extensive comparisons demonstrate that our framework outperforms other methods in both the accuracy and efficiency dimensions.
Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
Mar 26, 2024


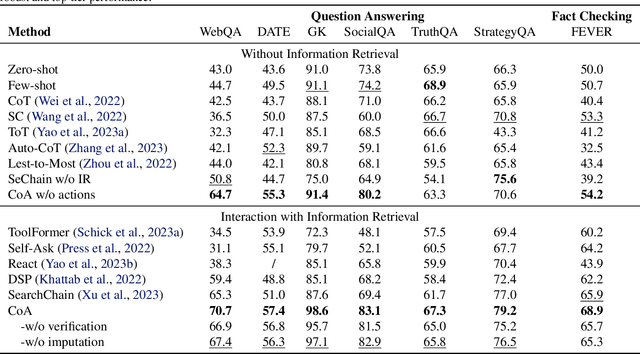
We present a Chain-of-Action (CoA) framework for multimodal and retrieval-augmented Question-Answering (QA). Compared to the literature, CoA overcomes two major challenges of current QA applications: (i) unfaithful hallucination that is inconsistent with real-time or domain facts and (ii) weak reasoning performance over compositional information. Our key contribution is a novel reasoning-retrieval mechanism that decomposes a complex question into a reasoning chain via systematic prompting and pre-designed actions. Methodologically, we propose three types of domain-adaptable `Plug-and-Play' actions for retrieving real-time information from heterogeneous sources. We also propose a multi-reference faith score (MRFS) to verify and resolve conflicts in the answers. Empirically, we exploit both public benchmarks and a Web3 case study to demonstrate the capability of CoA over other methods.
CoRMF: Criticality-Ordered Recurrent Mean Field Ising Solver
Mar 07, 2024


We propose an RNN-based efficient Ising model solver, the Criticality-ordered Recurrent Mean Field (CoRMF), for forward Ising problems. In its core, a criticality-ordered spin sequence of an $N$-spin Ising model is introduced by sorting mission-critical edges with greedy algorithm, such that an autoregressive mean-field factorization can be utilized and optimized with Recurrent Neural Networks (RNNs). Our method has two notable characteristics: (i) by leveraging the approximated tree structure of the underlying Ising graph, the newly-obtained criticality order enables the unification between variational mean-field and RNN, allowing the generally intractable Ising model to be efficiently probed with probabilistic inference; (ii) it is well-modulized, model-independent while at the same time expressive enough, and hence fully applicable to any forward Ising inference problems with minimal effort. Computationally, by using a variance-reduced Monte Carlo gradient estimator, CoRFM solves the Ising problems in a self-train fashion without data/evidence, and the inference tasks can be executed by directly sampling from RNN. Theoretically, we establish a provably tighter error bound than naive mean-field by using the matrix cut decomposition machineries. Numerically, we demonstrate the utility of this framework on a series of Ising datasets.