 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise of Large Language Models and the Direction and Impact of US Federal Research Funding
Jan 21, 2026Federal research funding shapes the direction, diversity, and impact of the US scientific enterprise. Large language models (LLMs) are rapidly diffusing into scientific practice, holding substantial promise while raising widespread concerns. Despite growing attention to AI use in scientific writing and evaluation, little is known about how the rise of LLMs is reshaping the public funding landscape. Here, we examine LLM involvement at key stages of the federal funding pipeline by combining two complementary data sources: confidential National Science Foundation (NSF) and National Institutes of Health (NIH) proposal submissions from two large US R1 universities, including funded, unfunded, and pending proposals, and the full population of publicly released NSF and NIH awards. We find that LLM use rises sharply beginning in 2023 and exhibits a bimodal distribution, indicating a clear split between minimal and substantive use. Across both private submissions and public awards, higher LLM involvement is consistently associated with lower semantic distinctiveness, positioning projects closer to recently funded work within the same agency. The consequences of this shift are agency-dependent. LLM use is positively associated with proposal success and higher subsequent publication output at NIH, whereas no comparable associations are observed at NSF. Notably, the productivity gains at NIH are concentrated in non-hit papers rather than the most highly cited work. Together, these findings provide large-scale evidence that the rise of LLMs is reshaping how scientific ideas are positioned, selected, and translated into publicly funded research, with implications for portfolio governance, research diversity, and the long-run impact of science.
SciSciGPT: Advancing Human-AI Collaboration in the Science of Science
Apr 07, 2025



The increasing availability of large-scale datasets has fueled rapid progress across many scientific fields, creating unprecedented opportunities for research and discovery while posing significant analytical challenges. Recent advances in large language models (LLMs) and AI agents have opened new possibilities for human-AI collaboration, offering powerful tools to navigate this complex research landscape. In this paper, we introduce SciSciGPT, an open-source, prototype AI collaborator that uses the science of science as a testbed to explore the potential of LLM-powered research tools. SciSciGPT automates complex workflows, supports diverse analytical approaches, accelerates research prototyping and iteration, and facilitates reproducibility. Through case studies, we demonstrate its ability to streamline a wide range of empirical and analytical research tasks while highlighting its broader potential to advance research. We further propose an LLM Agent capability maturity model for human-AI collaboration, envisioning a roadmap to further improve and expand upon frameworks like SciSciGPT. As AI capabilities continue to evolve, frameworks like SciSciGPT may play increasingly pivotal roles in scientific research and discovery, unlocking further opportunities. At the same time, these new advances also raise critical challenges, from ensuring transparency and ethical use to balancing human and AI contributions. Addressing these issues may shape the future of scientific inquiry and inform how we train the next generation of scientists to thrive in an increasingly AI-integrated research ecosystem.
One-shot Transfer Learning for Population Mapping
Aug 17, 2021
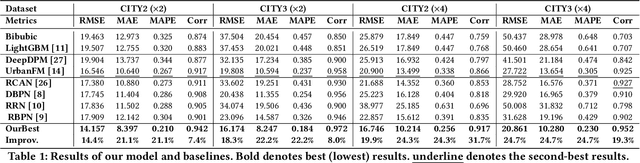


Fine-grained population distribution data is of great importance for many applications, e.g., urban planning, traffic scheduling, epidemic modeling, and risk control. However, due to the limitations of data collection, including infrastructure density, user privacy, and business security, such fine-grained data is hard to collect and usually, only coarse-grained data is available. Thus, obtaining fine-grained population distribution from coarse-grained distribution becomes an important problem. To tackle this problem, existing methods mainly rely on sufficient fine-grained ground truth for training, which is not often available for the majority of cities. That limits the applications of these methods and brings the necessity to transfer knowledge between data-sufficient source cities to data-scarce target cities. In knowledge transfer scenario, we employ single reference fine-grained ground truth in target city, which is easy to obtain via remote sensing or questionnaire, as the ground truth to inform the large-scale urban structure and support the knowledge transfer in target city. By this approach, we transform the fine-grained population mapping problem into a one-shot transfer learning problem. In this paper, we propose a novel one-shot transfer learning framework PSRNet to transfer spatial-temporal knowledge across cities from the view of network structure, the view of data, and the view of optimization. Experiments on real-life datasets of 4 cities demonstrate that PSRNet has significant advantages over 8 state-of-the-art baselines by reducing RMSE and MAE by more than 25%. Our code and datasets are released in Github (https://github.com/erzhuoshao/PSRNet-CIKM).