 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise of Large Language Models and the Direction and Impact of US Federal Research Funding
Jan 21, 2026Federal research funding shapes the direction, diversity, and impact of the US scientific enterprise. Large language models (LLMs) are rapidly diffusing into scientific practice, holding substantial promise while raising widespread concerns. Despite growing attention to AI use in scientific writing and evaluation, little is known about how the rise of LLMs is reshaping the public funding landscape. Here, we examine LLM involvement at key stages of the federal funding pipeline by combining two complementary data sources: confidential National Science Foundation (NSF) and National Institutes of Health (NIH) proposal submissions from two large US R1 universities, including funded, unfunded, and pending proposals, and the full population of publicly released NSF and NIH awards. We find that LLM use rises sharply beginning in 2023 and exhibits a bimodal distribution, indicating a clear split between minimal and substantive use. Across both private submissions and public awards, higher LLM involvement is consistently associated with lower semantic distinctiveness, positioning projects closer to recently funded work within the same agency. The consequences of this shift are agency-dependent. LLM use is positively associated with proposal success and higher subsequent publication output at NIH, whereas no comparable associations are observed at NSF. Notably, the productivity gains at NIH are concentrated in non-hit papers rather than the most highly cited work. Together, these findings provide large-scale evidence that the rise of LLMs is reshaping how scientific ideas are positioned, selected, and translated into publicly funded research, with implications for portfolio governance, research diversity, and the long-run impact of science.
SciSciGPT: Advancing Human-AI Collaboration in the Science of Science
Apr 07, 2025



The increasing availability of large-scale datasets has fueled rapid progress across many scientific fields, creating unprecedented opportunities for research and discovery while posing significant analytical challenges. Recent advances in large language models (LLMs) and AI agents have opened new possibilities for human-AI collaboration, offering powerful tools to navigate this complex research landscape. In this paper, we introduce SciSciGPT, an open-source, prototype AI collaborator that uses the science of science as a testbed to explore the potential of LLM-powered research tools. SciSciGPT automates complex workflows, supports diverse analytical approaches, accelerates research prototyping and iteration, and facilitates reproducibility. Through case studies, we demonstrate its ability to streamline a wide range of empirical and analytical research tasks while highlighting its broader potential to advance research. We further propose an LLM Agent capability maturity model for human-AI collaboration, envisioning a roadmap to further improve and expand upon frameworks like SciSciGPT. As AI capabilities continue to evolve, frameworks like SciSciGPT may play increasingly pivotal roles in scientific research and discovery, unlocking further opportunities. At the same time, these new advances also raise critical challenges, from ensuring transparency and ethical use to balancing human and AI contributions. Addressing these issues may shape the future of scientific inquiry and inform how we train the next generation of scientists to thrive in an increasingly AI-integrated research ecosystem.
Geometric graphs from data to aid classification tasks with graph convolutional networks
May 08, 2020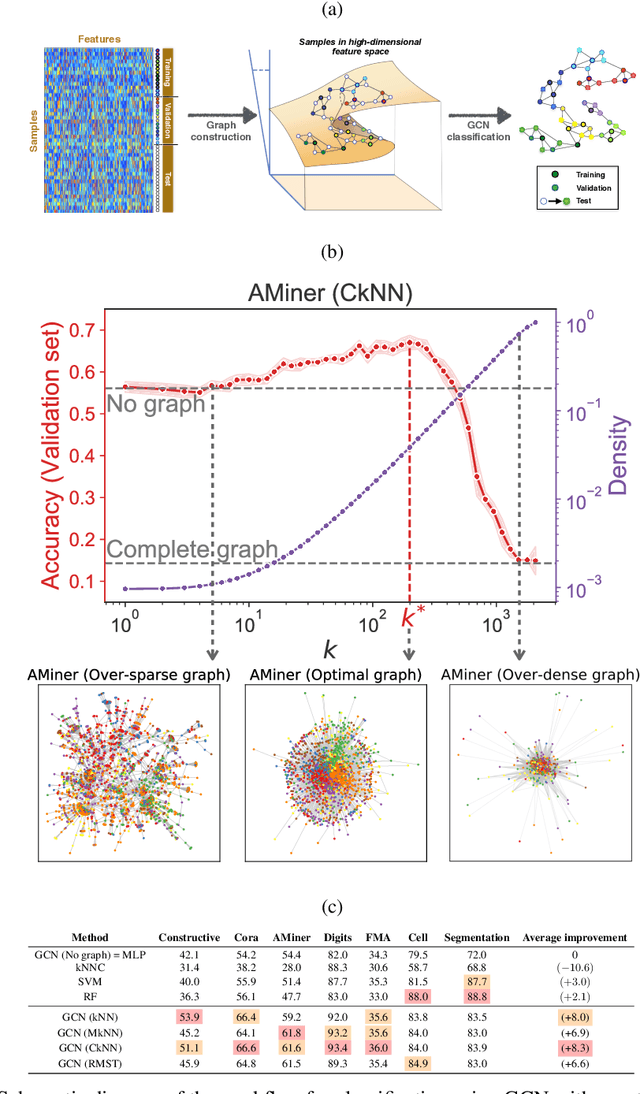
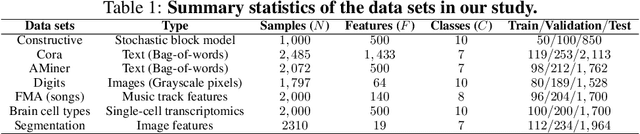


Classification is a classic problem in data analytics and has been approached from many different angles, including machine learning. Traditionally, machine learning methods classify samples based solely on their features. This paradigm is evolving. Recent developments on Graph Convolutional Networks have shown that explicitly using information not directly present in the features to represent a type of relationship between samples can improve the classification performance by a significant margin. However, graphs are not often immediately present in data sets, thus limiting the applicability of Graph Convolutional Networks. In this paper, we explore if graphs extracted from the features themselves can aid classification performance. First, we show that constructing optimal geometric graphs directly from data features can aid classification tasks on both synthetic and real-world data sets from different domains. Second, we introduce two metrics to characterize optimal graphs: i) by measuring the alignment between the subspaces spanned by the features convolved with the graph and the ground truth; and ii) ratio of class separation in the output activations of Graph Convolutional Networks: this shows that the optimal graph maximally separates classes. Finally, we find that sparsifying the optimal graph can potentially improve classification performance.
Quantifying the alignment of graph and features in deep learning
May 30, 2019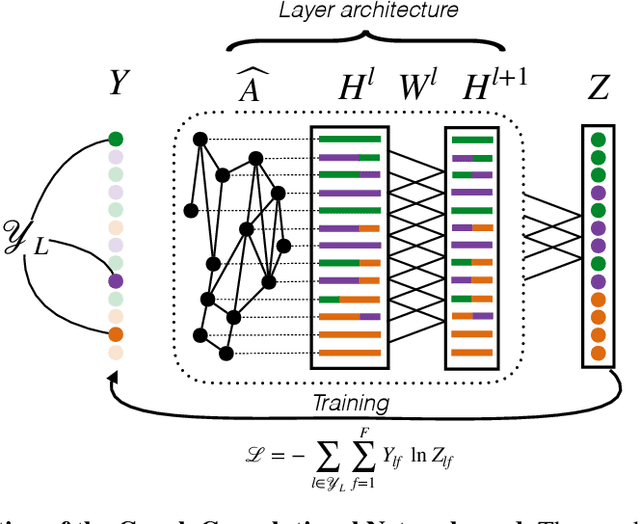
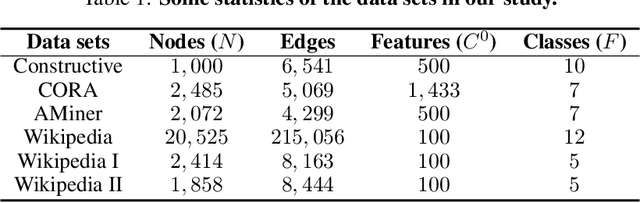
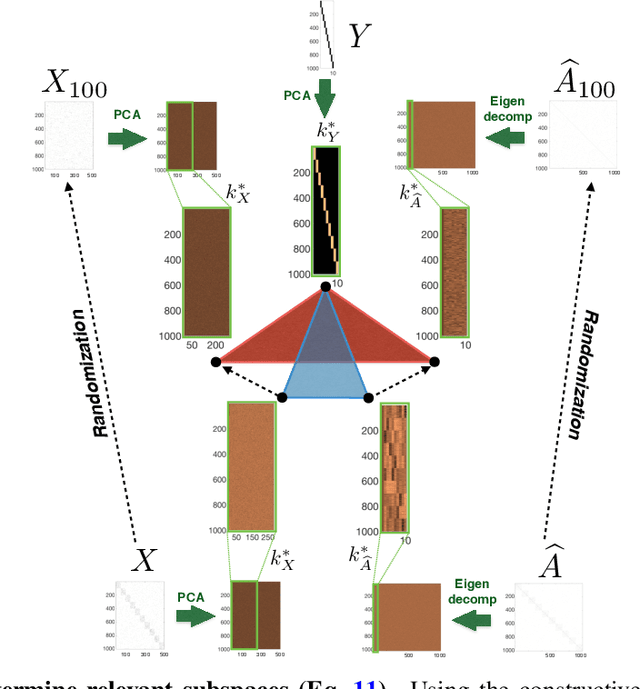
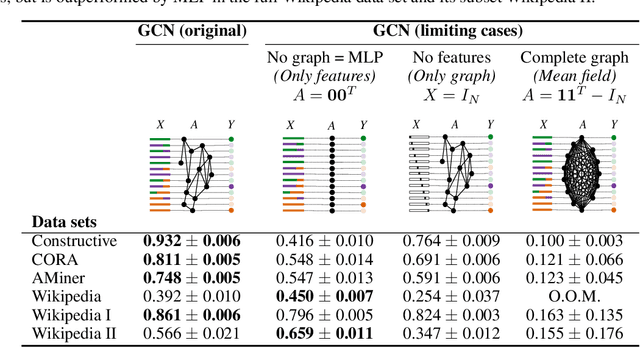
We show that the classification performance of Graph Convolutional Networks is related to the alignment between features, graph and ground truth, which we quantify using a subspace alignment measure corresponding to the Frobenius norm of the matrix of pairwise chordal distances between three subspaces associated with features, graph and ground truth. The proposed measure is based on the principal angles between subspaces and has both spectral and geometrical interpretations. We showcase the relationship between the subspace alignment measure and the classification performance through the study of limiting cases of Graph Convolutional Networks as well as systematic randomizations of both features and graph structure applied to a constructive example and several examples of citation networks of different origin. The analysis also reveals the relative importance of the graph and features for classification purposes.