 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Inspired Gaussian Splatting for HDR Novel View Synthesis
Mar 30, 2026High dynamic range novel view synthesis (HDR-NVS) reconstructs scenes with dynamic details by fusing multi-exposure low dynamic range (LDR) views, yet it struggles to capture ambient illumination-dependent appearance. Implicitly supervising HDR content by constraining tone-mapped results fails in correcting abnormal HDR values, and results in limited gradients for Gaussians in under/over-exposed regions. To this end, we introduce PhysHDR-GS, a physically inspired HDR-NVS framework that models scene appearance via intrinsic reflectance and adjustable ambient illumination. PhysHDR-GS employs a complementary image-exposure (IE) branch and Gaussian-illumination (GI) branch to faithfully reproduce standard camera observations and capture illumination-dependent appearance changes, respectively. During training, the proposed cross-branch HDR consistency loss provides explicit supervision for HDR content, while an illumination-guided gradient scaling strategy mitigates exposure-biased gradient starvation and reduces under-densified representations. Experimental results across realistic and synthetic datasets demonstrate our superiority in reconstructing HDR details (e.g., a PSNR gain of 2.04 dB over HDR-GS), while maintaining real-time rendering speed (up to 76 FPS). Code and models are available at https://huimin-zeng.github.io/PhysHDR-GS/.
The Rise of Large Language Models and the Direction and Impact of US Federal Research Funding
Jan 21, 2026Federal research funding shapes the direction, diversity, and impact of the US scientific enterprise. Large language models (LLMs) are rapidly diffusing into scientific practice, holding substantial promise while raising widespread concerns. Despite growing attention to AI use in scientific writing and evaluation, little is known about how the rise of LLMs is reshaping the public funding landscape. Here, we examine LLM involvement at key stages of the federal funding pipeline by combining two complementary data sources: confidential National Science Foundation (NSF) and National Institutes of Health (NIH) proposal submissions from two large US R1 universities, including funded, unfunded, and pending proposals, and the full population of publicly released NSF and NIH awards. We find that LLM use rises sharply beginning in 2023 and exhibits a bimodal distribution, indicating a clear split between minimal and substantive use. Across both private submissions and public awards, higher LLM involvement is consistently associated with lower semantic distinctiveness, positioning projects closer to recently funded work within the same agency. The consequences of this shift are agency-dependent. LLM use is positively associated with proposal success and higher subsequent publication output at NIH, whereas no comparable associations are observed at NSF. Notably, the productivity gains at NIH are concentrated in non-hit papers rather than the most highly cited work. Together, these findings provide large-scale evidence that the rise of LLMs is reshaping how scientific ideas are positioned, selected, and translated into publicly funded research, with implications for portfolio governance, research diversity, and the long-run impact of science.
Rethinking Fine-Tuning: Unlocking Hidden Capabilities in Vision-Language Models
Dec 28, 2025Explorations in fine-tuning Vision-Language Models (VLMs), such as Low-Rank Adaptation (LoRA) from Parameter Efficient Fine-Tuning (PEFT), have made impressive progress. However, most approaches rely on explicit weight updates, overlooking the extensive representational structures already encoded in pre-trained models that remain underutilized. Recent works have demonstrated that Mask Fine-Tuning (MFT) can be a powerful and efficient post-training paradigm for language models. Instead of updating weights, MFT assigns learnable gating scores to each weight, allowing the model to reorganize its internal subnetworks for downstream task adaptation. In this paper, we rethink fine-tuning for VLMs from a structural reparameterization perspective grounded in MFT. We apply MFT to the language and projector components of VLMs with different language backbones and compare against strong PEFT baselines. Experiments show that MFT consistently surpasses LoRA variants and even full fine-tuning, achieving high performance without altering the frozen backbone. Our findings reveal that effective adaptation can emerge not only from updating weights but also from reestablishing connections among the model's existing knowledge. Code available at: https://github.com/Ming-K9/MFT-VLM
Boosting Large Language Models with Mask Fine-Tuning
Mar 27, 2025The model is usually kept integral in the mainstream large language model (LLM) fine-tuning protocols. No works have questioned whether maintaining the integrity of the model is indispensable for performance. In this work, we introduce Mask Fine-Tuning (MFT), a brand-new LLM fine-tuning paradigm to show that properly breaking the integrity of the model can surprisingly lead to improved performance. Specifically, MFT learns a set of binary masks supervised by the typical LLM fine-tuning objective. Extensive experiments show that MFT gains a consistent performance boost across various domains and backbones (e.g., 1.95%/1.88% average gain in coding with LLaMA2-7B/3.1-8B). Detailed procedures are provided to study the proposed MFT from different hyperparameter perspectives for better insight. In particular, MFT naturally updates the current LLM training protocol by deploying it on a complete well-trained model. This study extends the functionality of mask learning from its conventional network pruning context for model compression to a more general scope.
Accessing Vision Foundation Models at ImageNet-level Costs
Jul 15, 2024



Vision foundation models are renowned for their generalization ability due to massive training data. Nevertheless, they demand tremendous training resources, and the training data is often inaccessible, e.g., CLIP, DINOv2, posing great challenges to developing derivatives that could advance research in this field. In this work, we offer a very simple and general solution, named Proteus, to distill foundation models into smaller equivalents on ImageNet-1K without access to the original training data. Specifically, we remove the designs from conventional knowledge distillation settings that result in dataset bias and present three levels of training objectives, i.e., token, patch, and feature, to maximize the efficacy of knowledge transfer. In this manner, Proteus is trained at ImageNet-level costs with surprising ability, facilitating the accessibility of training foundation models for the broader research community. Leveraging DINOv2-g/14 as the teacher, Proteus-L/14 matches the performance of the Oracle method DINOv2-L/14 (142M training data) across 15 benchmarks and outperforms other vision foundation models including CLIP-L/14 (400M), OpenCLIP-L/14 (400M/2B) and SynCLR-L/14 (600M).
SoupLM: Model Integration in Large Language and Multi-Modal Models
Jul 11, 2024

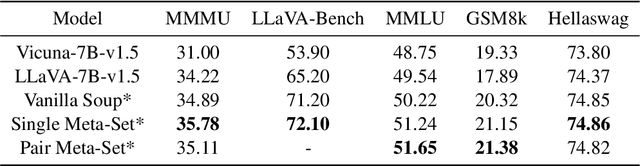
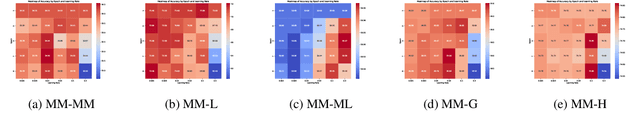
Training large language models (LLMs) and multimodal LLMs necessitates significant computing resources, and existing publicly available LLMs are typically pre-trained on diverse, privately curated datasets spanning various tasks. For instance, LLaMA, Vicuna, and LLaVA are three LLM variants trained with LLaMA base models using very different training recipes, tasks, and data modalities. The training cost and complexity for such LLM variants grow rapidly. In this study, we propose to use a soup strategy to assemble these LLM variants into a single well-generalized multimodal LLM (SoupLM) in a cost-efficient manner. Assembling these LLM variants efficiently brings knowledge and specialities trained from different domains and data modalities into an integrated one (e.g., chatbot speciality from user-shared conversations for Vicuna, and visual capacity from vision-language data for LLaVA), therefore, to avoid computing costs of repetitive training on several different domains. We propose series of soup strategies to systematically benchmark performance gains across various configurations, and probe the soup behavior across base models in the interpolation space.
Rewrite the Stars
Mar 29, 2024Recent studies have drawn attention to the untapped potential of the "star operation" (element-wise multiplication) in network design. While intuitive explanations abound, the foundational rationale behind its application remains largely unexplored. Our study attempts to reveal the star operation's ability to map inputs into high-dimensional, non-linear feature spaces -- akin to kernel tricks -- without widening the network. We further introduce StarNet, a simple yet powerful prototype, demonstrating impressive performance and low latency under compact network structure and efficient budget. Like stars in the sky, the star operation appears unremarkable but holds a vast universe of potential. Our work encourages further exploration across tasks, with codes available at https://github.com/ma-xu/Rewrite-the-Stars.
Don't Judge by the Look: Towards Motion Coherent Video Representation
Mar 25, 2024



Current training pipelines in object recognition neglect Hue Jittering when doing data augmentation as it not only brings appearance changes that are detrimental to classification, but also the implementation is inefficient in practice. In this study, we investigate the effect of hue variance in the context of video understanding and find this variance to be beneficial since static appearances are less important in videos that contain motion information. Based on this observation, we propose a data augmentation method for video understanding, named Motion Coherent Augmentation (MCA), that introduces appearance variation in videos and implicitly encourages the model to prioritize motion patterns, rather than static appearances. Concretely, we propose an operation SwapMix to efficiently modify the appearance of video samples, and introduce Variation Alignment (VA) to resolve the distribution shift caused by SwapMix, enforcing the model to learn appearance invariant representations. Comprehensive empirical evaluation across various architectures and different datasets solidly validates the effectiveness and generalization ability of MCA, and the application of VA in other augmentation methods. Code is available at https://github.com/BeSpontaneous/MCA-pytorch.
Latent Graph Inference with Limited Supervision
Oct 06, 2023Latent graph inference (LGI) aims to jointly learn the underlying graph structure and node representations from data features. However, existing LGI methods commonly suffer from the issue of supervision starvation, where massive edge weights are learned without semantic supervision and do not contribute to the training loss. Consequently, these supervision-starved weights, which may determine the predictions of testing samples, cannot be semantically optimal, resulting in poor generalization. In this paper, we observe that this issue is actually caused by the graph sparsification operation, which severely destroys the important connections established between pivotal nodes and labeled ones. To address this, we propose to restore the corrupted affinities and replenish the missed supervision for better LGI. The key challenge then lies in identifying the critical nodes and recovering the corrupted affinities. We begin by defining the pivotal nodes as $k$-hop starved nodes, which can be identified based on a given adjacency matrix. Considering the high computational burden, we further present a more efficient alternative inspired by CUR matrix decomposition. Subsequently, we eliminate the starved nodes by reconstructing the destroyed connections. Extensive experiments on representative benchmarks demonstrate that reducing the starved nodes consistently improves the performance of state-of-the-art LGI methods, especially under extremely limited supervision (6.12% improvement on Pubmed with a labeling rate of only 0.3%).
Frame Flexible Network
Mar 26, 2023Existing video recognition algorithms always conduct different training pipelines for inputs with different frame numbers, which requires repetitive training operations and multiplying storage costs. If we evaluate the model using other frames which are not used in training, we observe the performance will drop significantly (see Fig.1), which is summarized as Temporal Frequency Deviation phenomenon. To fix this issue, we propose a general framework, named Frame Flexible Network (FFN), which not only enables the model to be evaluated at different frames to adjust its computation, but also reduces the memory costs of storing multiple models significantly. Concretely, FFN integrates several sets of training sequences, involves Multi-Frequency Alignment (MFAL) to learn temporal frequency invariant representations, and leverages Multi-Frequency Adaptation (MFAD) to further strengthen the representation abilities. Comprehensive empirical validations using various architectures and popular benchmarks solidly demonstrate the effectiveness and generalization of FFN (e.g., 7.08/5.15/2.17% performance gain at Frame 4/8/16 on Something-Something V1 dataset over Uniformer). Code is available at https://github.com/BeSpontaneous/FFN.