 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Indra Representation Hypothesis for Multimodal Alignment
Apr 06, 2026Recent studies have uncovered an interesting phenomenon: unimodal foundation models tend to learn convergent representations, regardless of differences in architecture, training objectives, or data modalities. However, these representations are essentially internal abstractions of samples that characterize samples independently, leading to limited expressiveness. In this paper, we propose The Indra Representation Hypothesis, inspired by the philosophical metaphor of Indra's Net. We argue that representations from unimodal foundation models are converging to implicitly reflect a shared relational structure underlying reality, akin to the relational ontology of Indra's Net. We formalize this hypothesis using the V-enriched Yoneda embedding from category theory, defining the Indra representation as a relational profile of each sample with respect to others. This formulation is shown to be unique, complete, and structure-preserving under a given cost function. We instantiate the Indra representation using angular distance and evaluate it in cross-model and cross-modal scenarios involving vision, language, and audio. Extensive experiments demonstrate that Indra representations consistently enhance robustness and alignment across architectures and modalities, providing a theoretically grounded and practical framework for training-free alignment of unimodal foundation models. Our code is available at https://github.com/Jianglin954/Indra.
ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
Mar 23, 2026Recent progress in latent world models (e.g., V-JEPA2) has shown promising capability in forecasting future world states from video observations. Nevertheless, dense prediction from a short observation window limits temporal context and can bias predictors toward local, low-level extrapolation, making it difficult to capture long-horizon semantics and reducing downstream utility. Vision--language models (VLMs), in contrast, provide strong semantic grounding and general knowledge by reasoning over uniformly sampled frames, but they are not ideal as standalone dense predictors due to compute-driven sparse sampling, a language-output bottleneck that compresses fine-grained interaction states into text-oriented representations, and a data-regime mismatch when adapting to small action-conditioned datasets. We propose a VLM-guided JEPA-style latent world modeling framework that combines dense-frame dynamics modeling with long-horizon semantic guidance via a dual-temporal pathway: a dense JEPA branch for fine-grained motion and interaction cues, and a uniformly sampled VLM \emph{thinker} branch with a larger temporal stride for knowledge-rich guidance. To transfer the VLM's progressive reasoning signals effectively, we introduce a hierarchical pyramid representation extraction module that aggregates multi-layer VLM representations into guidance features compatible with latent prediction. Experiments on hand-manipulation trajectory prediction show that our method outperforms both a strong VLM-only baseline and a JEPA-predictor baseline, and yields more robust long-horizon rollout behavior.
Ref-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
Feb 27, 2026Referring Expression Comprehension (REC) links language to region level visual perception. Standard benchmarks (RefCOCO, RefCOCO+, RefCOCOg) have progressed rapidly with multimodal LLMs but remain weak tests of visual reasoning and grounding: (i) many expressions are very short, leaving little reasoning demand; (ii) images often contain few distractors, making the target easy to find; and (iii) redundant descriptors enable shortcut solutions that bypass genuine text understanding and visual reasoning. We introduce Ref-Adv, a modern REC benchmark that suppresses shortcuts by pairing linguistically nontrivial expressions with only the information necessary to uniquely identify the target. The dataset contains referring expressions on real images, curated with hard distractors and annotated with reasoning facets including negation. We conduct comprehensive ablations (word order perturbations and descriptor deletion sufficiency) to show that solving Ref-Adv requires reasoning beyond simple cues, and we evaluate a broad suite of contemporary multimodal LLMs on Ref-Adv. Despite strong results on RefCOCO, RefCOCO+, and RefCOCOg, models drop markedly on Ref-Adv, revealing reliance on shortcuts and gaps in visual reasoning and grounding. We provide an in depth failure analysis and aim for Ref-Adv to guide future work on visual reasoning and grounding in MLLMs.
Seeing Through Words: Controlling Visual Retrieval Quality with Language Models
Feb 24, 2026Text-to-image retrieval is a fundamental task in vision-language learning, yet in real-world scenarios it is often challenged by short and underspecified user queries. Such queries are typically only one or two words long, rendering them semantically ambiguous, prone to collisions across diverse visual interpretations, and lacking explicit control over the quality of retrieved images. To address these issues, we propose a new paradigm of quality-controllable retrieval, which enriches short queries with contextual details while incorporating explicit notions of image quality. Our key idea is to leverage a generative language model as a query completion function, extending underspecified queries into descriptive forms that capture fine-grained visual attributes such as pose, scene, and aesthetics. We introduce a general framework that conditions query completion on discretized quality levels, derived from relevance and aesthetic scoring models, so that query enrichment is not only semantically meaningful but also quality-aware. The resulting system provides three key advantages: 1) flexibility, it is compatible with any pretrained vision-language model (VLMs) without modification; 2) transparency, enriched queries are explicitly interpretable by users; and 3) controllability, enabling retrieval results to be steered toward user-preferred quality levels. Extensive experiments demonstrate that our proposed approach significantly improves retrieval results and provides effective quality control, bridging the gap between the expressive capacity of modern VLMs and the underspecified nature of short user queries. Our code is available at https://github.com/Jianglin954/QCQC.
SimpleCall: A Lightweight Image Restoration Agent in Label-Free Environments with MLLM Perceptual Feedback
Dec 21, 2025Complex image restoration aims to recover high-quality images from inputs affected by multiple degradations such as blur, noise, rain, and compression artifacts. Recent restoration agents, powered by vision-language models and large language models, offer promising restoration capabilities but suffer from significant efficiency bottlenecks due to reflection, rollback, and iterative tool searching. Moreover, their performance heavily depends on degradation recognition models that require extensive annotations for training, limiting their applicability in label-free environments. To address these limitations, we propose a policy optimization-based restoration framework that learns an lightweight agent to determine tool-calling sequences. The agent operates in a sequential decision process, selecting the most appropriate restoration operation at each step to maximize final image quality. To enable training within label-free environments, we introduce a novel reward mechanism driven by multimodal large language models, which act as human-aligned evaluator and provide perceptual feedback for policy improvement. Once trained, our agent executes a deterministic restoration plans without redundant tool invocations, significantly accelerating inference while maintaining high restoration quality. Extensive experiments show that despite using no supervision, our method matches SOTA performance on full-reference metrics and surpasses existing approaches on no-reference metrics across diverse degradation scenarios.
Scale-Free Graph-Language Models
Feb 21, 2025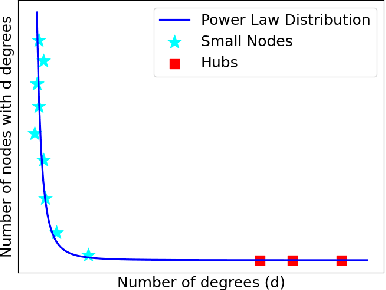
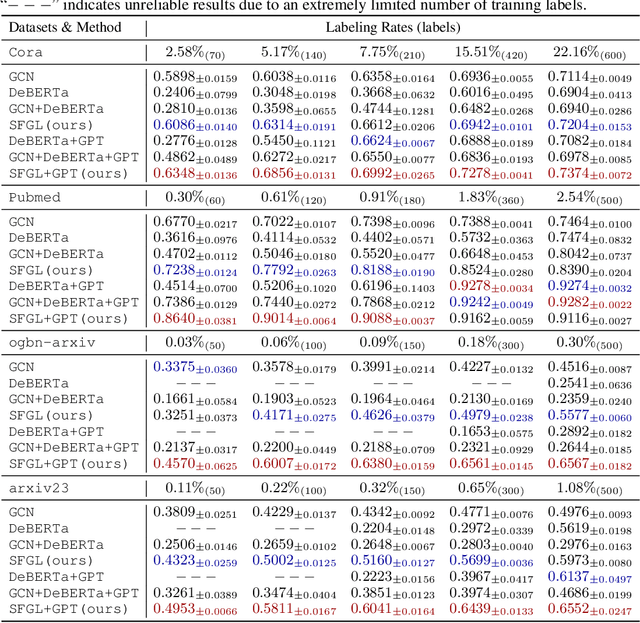
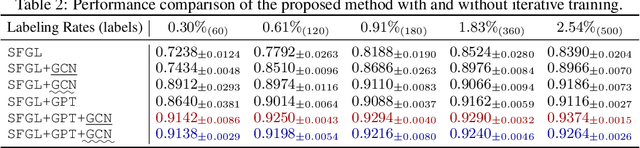
Graph-language models (GLMs) have demonstrated great potential in graph-based semi-supervised learning. A typical GLM consists of two key stages: graph generation and text embedding, which are usually implemented by inferring a latent graph and finetuning a language model (LM), respectively. However, the former often relies on artificial assumptions about the underlying edge distribution, while the latter requires extensive data annotations. To tackle these challenges, this paper introduces a novel GLM that integrates graph generation and text embedding within a unified framework. Specifically, for graph generation, we leverage an inherent characteristic of real edge distribution--the scale-free property--as a structural prior. We unexpectedly find that this natural property can be effectively approximated by a simple k-nearest neighbor (KNN) graph. For text embedding, we develop a graph-based pseudo-labeler that utilizes scale-free graphs to provide complementary supervision for improved LM finetuning. Extensive experiments on representative datasets validate our findings on the scale-free structural approximation of KNN graphs and demonstrate the effectiveness of integrating graph generation and text embedding with a real structural prior. Our code is available at https://github.com/Jianglin954/SFGL.
Latent Graph Inference with Limited Supervision
Oct 06, 2023Latent graph inference (LGI) aims to jointly learn the underlying graph structure and node representations from data features. However, existing LGI methods commonly suffer from the issue of supervision starvation, where massive edge weights are learned without semantic supervision and do not contribute to the training loss. Consequently, these supervision-starved weights, which may determine the predictions of testing samples, cannot be semantically optimal, resulting in poor generalization. In this paper, we observe that this issue is actually caused by the graph sparsification operation, which severely destroys the important connections established between pivotal nodes and labeled ones. To address this, we propose to restore the corrupted affinities and replenish the missed supervision for better LGI. The key challenge then lies in identifying the critical nodes and recovering the corrupted affinities. We begin by defining the pivotal nodes as $k$-hop starved nodes, which can be identified based on a given adjacency matrix. Considering the high computational burden, we further present a more efficient alternative inspired by CUR matrix decomposition. Subsequently, we eliminate the starved nodes by reconstructing the destroyed connections. Extensive experiments on representative benchmarks demonstrate that reducing the starved nodes consistently improves the performance of state-of-the-art LGI methods, especially under extremely limited supervision (6.12% improvement on Pubmed with a labeling rate of only 0.3%).
Asymmetric Transfer Hashing with Adaptive Bipartite Graph Learning
Jun 25, 2022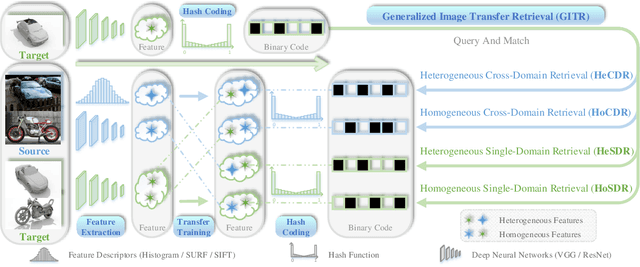
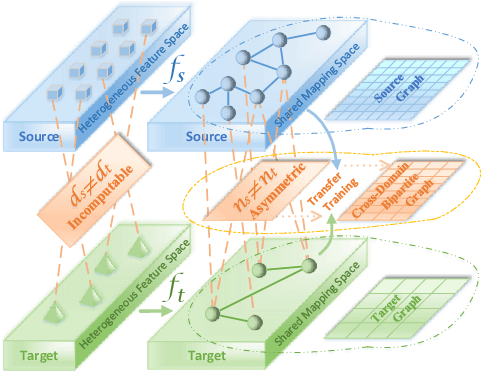
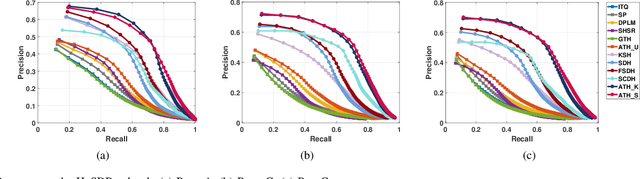
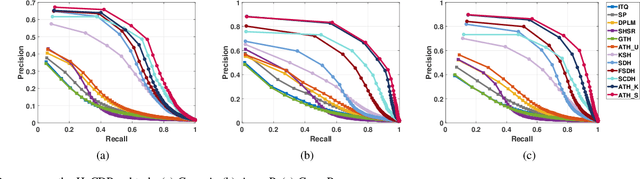
Thanks to the efficient retrieval speed and low storage consumption, learning to hash has been widely used in visual retrieval tasks. However, existing hashing methods assume that the query and retrieval samples lie in homogeneous feature space within the same domain. As a result, they cannot be directly applied to heterogeneous cross-domain retrieval. In this paper, we propose a Generalized Image Transfer Retrieval (GITR) problem, which encounters two crucial bottlenecks: 1) the query and retrieval samples may come from different domains, leading to an inevitable {domain distribution gap}; 2) the features of the two domains may be heterogeneous or misaligned, bringing up an additional {feature gap}. To address the GITR problem, we propose an Asymmetric Transfer Hashing (ATH) framework with its unsupervised/semi-supervised/supervised realizations. Specifically, ATH characterizes the domain distribution gap by the discrepancy between two asymmetric hash functions, and minimizes the feature gap with the help of a novel adaptive bipartite graph constructed on cross-domain data. By jointly optimizing asymmetric hash functions and the bipartite graph, not only can knowledge transfer be achieved but information loss caused by feature alignment can also be avoided. Meanwhile, to alleviate negative transfer, the intrinsic geometrical structure of single-domain data is preserved by involving a domain affinity graph. Extensive experiments on both single-domain and cross-domain benchmarks under different GITR subtasks indicate the superiority of our ATH method in comparison with the state-of-the-art hashing methods.
Deep Asymmetric Hashing with Dual Semantic Regression and Class Structure Quantization
Oct 24, 2021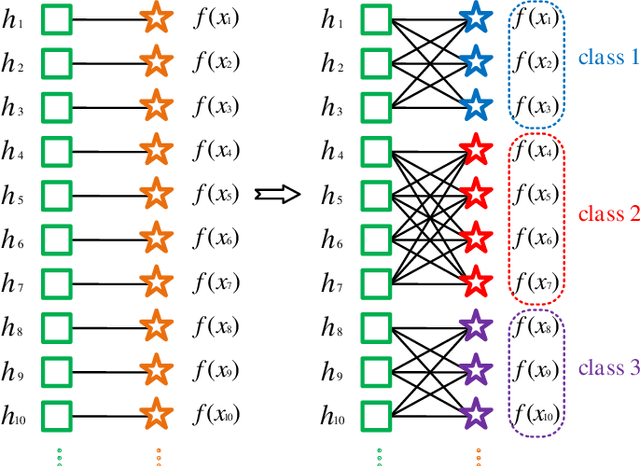
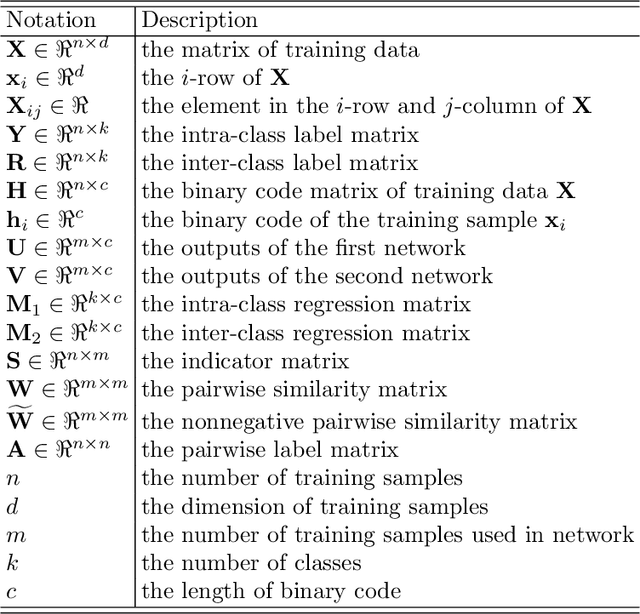
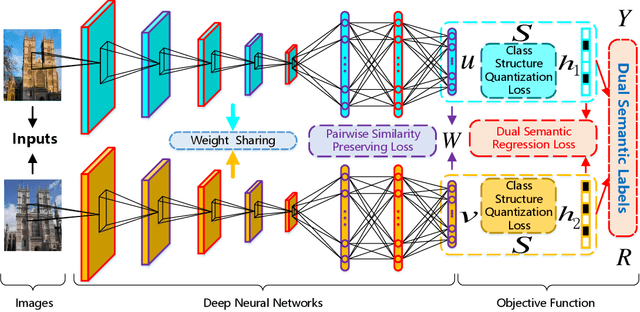
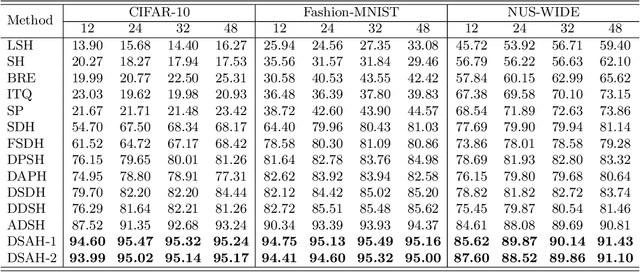
Recently, deep hashing methods have been widely used in image retrieval task. Most existing deep hashing approaches adopt one-to-one quantization to reduce information loss. However, such class-unrelated quantization cannot give discriminative feedback for network training. In addition, these methods only utilize single label to integrate supervision information of data for hashing function learning, which may result in inferior network generalization performance and relatively low-quality hash codes since the inter-class information of data is totally ignored. In this paper, we propose a dual semantic asymmetric hashing (DSAH) method, which generates discriminative hash codes under three-fold constrains. Firstly, DSAH utilizes class prior to conduct class structure quantization so as to transmit class information during the quantization process. Secondly, a simple yet effective label mechanism is designed to characterize both the intra-class compactness and inter-class separability of data, thereby achieving semantic-sensitive binary code learning. Finally, a meaningful pairwise similarity preserving loss is devised to minimize the distances between class-related network outputs based on an affinity graph. With these three main components, high-quality hash codes can be generated through network. Extensive experiments conducted on various datasets demonstrate the superiority of DSAH in comparison with state-of-the-art deep hashing methods.
Deep Superpixel Cut for Unsupervised Image Segmentation
Mar 10, 2021


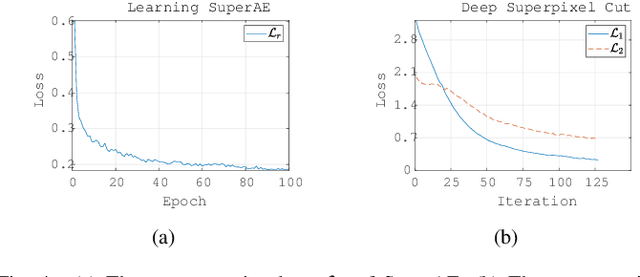
Image segmentation, one of the most critical vision tasks, has been studied for many years. Most of the early algorithms are unsupervised methods, which use hand-crafted features to divide the image into many regions. Recently, owing to the great success of deep learning technology, CNNs based methods show superior performance in image segmentation. However, these methods rely on a large number of human annotations, which are expensive to collect. In this paper, we propose a deep unsupervised method for image segmentation, which contains the following two stages. First, a Superpixelwise Autoencoder (SuperAE) is designed to learn the deep embedding and reconstruct a smoothed image, then the smoothed image is passed to generate superpixels. Second, we present a novel clustering algorithm called Deep Superpixel Cut (DSC), which measures the deep similarity between superpixels and formulates image segmentation as a soft partitioning problem. Via backpropagation, DSC adaptively partitions the superpixels into perceptual regions. Experimental results on the BSDS500 dataset demonstrate the effectiveness of the proposed method.