 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Limits of Prompt Tuning Transformers: Universality, Capacity and Efficiency
Nov 25, 2024We investigate the statistical and computational limits of prompt tuning for transformer-based foundation models. Our key contributions are prompt tuning on \textit{single-head} transformers with only a \textit{single} self-attention layer: (i) is universal, and (ii) supports efficient (even almost-linear time) algorithms under the Strong Exponential Time Hypothesis (SETH). Statistically, we prove that prompt tuning on such simplest possible transformers are universal approximators for sequence-to-sequence Lipschitz functions. In addition, we provide an exponential-in-$dL$ and -in-$(1/\epsilon)$ lower bound on the required soft-prompt tokens for prompt tuning to memorize any dataset with 1-layer, 1-head transformers. Computationally, we identify a phase transition in the efficiency of prompt tuning, determined by the norm of the \textit{soft-prompt-induced} keys and queries, and provide an upper bound criterion. Beyond this criterion, no sub-quadratic (efficient) algorithm for prompt tuning exists under SETH. Within this criterion, we showcase our theory by proving the existence of almost-linear time prompt tuning inference algorithms. These fundamental limits provide important necessary conditions for designing expressive and efficient prompt tuning methods for practitioners.
BiSHop: Bi-Directional Cellular Learning for Tabular Data with Generalized Sparse Modern Hopfield Model
Apr 04, 2024



We introduce the \textbf{B}i-Directional \textbf{S}parse \textbf{Hop}field Network (\textbf{BiSHop}), a novel end-to-end framework for deep tabular learning. BiSHop handles the two major challenges of deep tabular learning: non-rotationally invariant data structure and feature sparsity in tabular data. Our key motivation comes from the recent established connection between associative memory and attention mechanisms. Consequently, BiSHop uses a dual-component approach, sequentially processing data both column-wise and row-wise through two interconnected directional learning modules. Computationally, these modules house layers of generalized sparse modern Hopfield layers, a sparse extension of the modern Hopfield model with adaptable sparsity. Methodologically, BiSHop facilitates multi-scale representation learning, capturing both intra-feature and inter-feature interactions, with adaptive sparsity at each scale. Empirically, through experiments on diverse real-world datasets, we demonstrate that BiSHop surpasses current SOTA methods with significantly less HPO runs, marking it a robust solution for deep tabular learning.
CoRMF: Criticality-Ordered Recurrent Mean Field Ising Solver
Mar 07, 2024


We propose an RNN-based efficient Ising model solver, the Criticality-ordered Recurrent Mean Field (CoRMF), for forward Ising problems. In its core, a criticality-ordered spin sequence of an $N$-spin Ising model is introduced by sorting mission-critical edges with greedy algorithm, such that an autoregressive mean-field factorization can be utilized and optimized with Recurrent Neural Networks (RNNs). Our method has two notable characteristics: (i) by leveraging the approximated tree structure of the underlying Ising graph, the newly-obtained criticality order enables the unification between variational mean-field and RNN, allowing the generally intractable Ising model to be efficiently probed with probabilistic inference; (ii) it is well-modulized, model-independent while at the same time expressive enough, and hence fully applicable to any forward Ising inference problems with minimal effort. Computationally, by using a variance-reduced Monte Carlo gradient estimator, CoRFM solves the Ising problems in a self-train fashion without data/evidence, and the inference tasks can be executed by directly sampling from RNN. Theoretically, we establish a provably tighter error bound than naive mean-field by using the matrix cut decomposition machineries. Numerically, we demonstrate the utility of this framework on a series of Ising datasets.
Feature Programming for Multivariate Time Series Prediction
Jun 09, 2023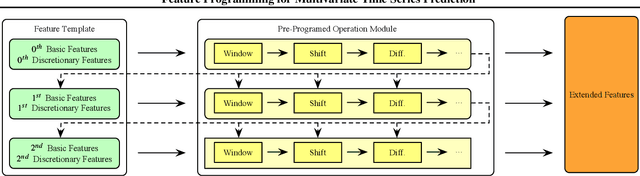
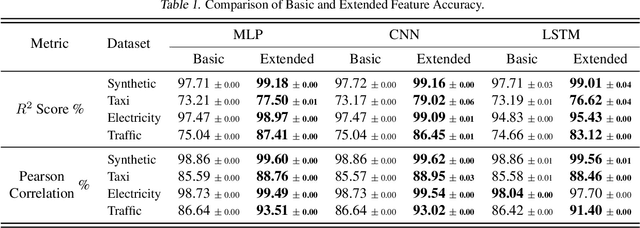

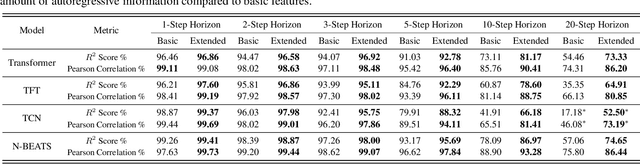
We introduce the concept of programmable feature engineering for time series modeling and propose a feature programming framework. This framework generates large amounts of predictive features for noisy multivariate time series while allowing users to incorporate their inductive bias with minimal effort. The key motivation of our framework is to view any multivariate time series as a cumulative sum of fine-grained trajectory increments, with each increment governed by a novel spin-gas dynamical Ising model. This fine-grained perspective motivates the development of a parsimonious set of operators that summarize multivariate time series in an abstract fashion, serving as the foundation for large-scale automated feature engineering. Numerically, we validate the efficacy of our method on several synthetic and real-world noisy time series datasets.
Unsupervised Hypergraph Feature Selection via a Novel Point-Weighting Framework and Low-Rank Representation
Oct 03, 2018
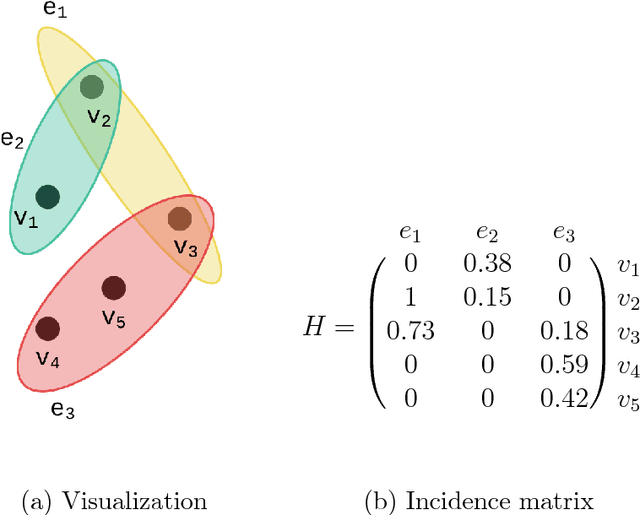
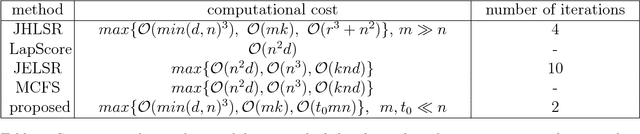
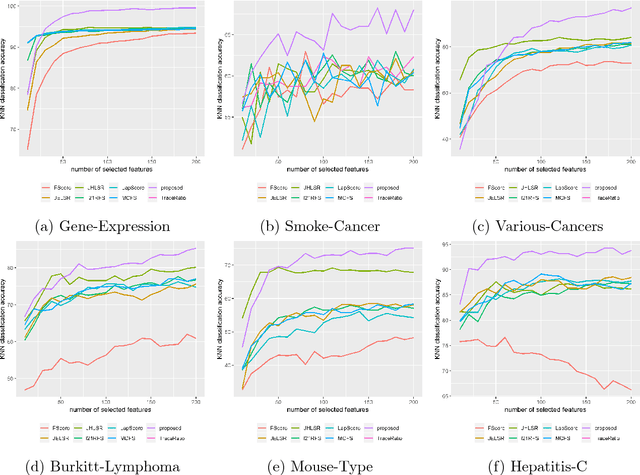
Feature selection methods are widely used in order to solve the 'curse of dimensionality' problem. Many proposed feature selection frameworks, treat all data points equally; neglecting their different representation power and importance. In this paper, we propose an unsupervised hypergraph feature selection method via a novel point-weighting framework and low-rank representation that captures the importance of different data points. We introduce a novel soft hypergraph with low complexity to model data. Then, we formulate the feature selection as an optimization problem to preserve local relationships and also global structure of data. Our approach for global structure preservation helps the framework overcome the problem of unavailability of data labels in unsupervised learning. The proposed feature selection method treats with different data points based on their importance in defining data structure and representation power. Moreover, since the robustness of feature selection methods against noise and outlier is of great importance, we adopt low-rank representation in our model. Also, we provide an efficient algorithm to solve the proposed optimization problem. The computational cost of the proposed algorithm is lower than many state-of-the-art methods which is of high importance in feature selection tasks. We conducted comprehensive experiments with various evaluation methods on different benchmark data sets. These experiments indicate significant improvement, compared with state-of-the-art feature selection methods.