 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTube Diffusion Policy: Reactive Visual-Tactile Policy Learning for Contact-rich Manipulation
Apr 26, 2026Contact-rich manipulation is central to many everyday human activities, requiring continuous adaptation to contact uncertainty and external disturbances through multi-modal perception, particularly vision and tactile feedback. While imitation learning has shown strong potential for learning complex manipulation behaviors, most existing approaches rely on action chunking, which fundamentally limits their ability to react to unforeseen observations during execution. This limitation becomes especially critical in contact-rich scenarios, where physical uncertainty and high-frequency tactile feedback demand rapid, reactive control. To address this challenge, we propose Tube Diffusion Policy (TDP), a novel reactive visual-tactile policy learning framework that bridges diffusion-based imitation learning with tube-based feedback control. By leveraging the expressive power of generative models, TDP learns an observation-conditioned feedback flow around nominal action chunks, forming an action tube that enables fast and adaptive reactions during execution. We evaluate TDP on the widely used Push-T benchmark and three additional challenging visual-tactile dexterous manipulation tasks. Across all benchmarks, TDP consistently outperforms state-of-the-art imitation learning baselines. Two real-world experiments further validate its robust reactivity under contact uncertainty and external disturbances. Moreover, the step-wise correction mechanism enabled by action tube significantly reduces the required denoising steps, making TDP well suited for real-time, high-frequency feedback control in contact-rich manipulation.
Efficient and Real-Time Motion Planning for Robotics Using Projection-Based Optimization
Jun 17, 2025Generating motions for robots interacting with objects of various shapes is a complex challenge, further complicated by the robot geometry and multiple desired behaviors. While current robot programming tools (such as inverse kinematics, collision avoidance, and manipulation planning) often treat these problems as constrained optimization, many existing solvers focus on specific problem domains or do not exploit geometric constraints effectively. We propose an efficient first-order method, Augmented Lagrangian Spectral Projected Gradient Descent (ALSPG), which leverages geometric projections via Euclidean projections, Minkowski sums, and basis functions. We show that by using geometric constraints rather than full constraints and gradients, ALSPG significantly improves real-time performance. Compared to second-order methods like iLQR, ALSPG remains competitive in the unconstrained case. We validate our method through toy examples and extensive simulations, and demonstrate its effectiveness on a 7-axis Franka robot, a 6-axis P-Rob robot and a 1:10 scale car in real-world experiments. Source codes, experimental data and videos are available on the project webpage: https://sites.google.com/view/alspg-oc
Sampling-Based Constrained Motion Planning with Products of Experts
Dec 23, 2024We present a novel approach to enhance the performance of sampling-based Model Predictive Control (MPC) in constrained optimization by leveraging products of experts. Our methodology divides the main problem into two components: one focused on optimality and the other on feasibility. By combining the solutions from each component, represented as distributions, we apply products of experts to implement a project-then-sample strategy. In this strategy, the optimality distribution is projected into the feasible area, allowing for more efficient sampling. This approach contrasts with the traditional sample-then-project method, leading to more diverse exploration and reducing the accumulation of samples on the boundaries. We demonstrate an effective implementation of this principle using a tensor train-based distribution model, which is characterized by its non-parametric nature, ease of combination with other distributions at the task level, and straightforward sampling technique. We adapt existing tensor train models to suit this purpose and validate the efficacy of our approach through experiments in various tasks, including obstacle avoidance, non-prehensile manipulation, and tasks involving staying on manifolds. Our experimental results demonstrate that the proposed method consistently outperforms known baselines, providing strong empirical support for its effectiveness.
Robust Contact-rich Manipulation through Implicit Motor Adaptation
Dec 16, 2024Contact-rich manipulation plays a vital role in daily human activities, yet uncertain physical parameters pose significant challenges for both model-based and model-free planning and control. A promising approach to address this challenge is to develop policies robust to a wide range of parameters. Domain adaptation and domain randomization are commonly used to achieve such policies but often compromise generalization to new instances or perform conservatively due to neglecting instance-specific information. \textit{Explicit motor adaptation} addresses these issues by estimating system parameters online and then retrieving the parameter-conditioned policy from a parameter-augmented base policy. However, it typically relies on precise system identification or additional high-quality policy retraining, presenting substantial challenges for contact-rich tasks with diverse physical parameters. In this work, we propose \textit{implicit motor adaptation}, which leverages tensor factorization as an implicit representation of the base policy. Given a roughly estimated parameter distribution, the parameter-conditioned policy can be efficiently derived by exploiting the separable structure of tensor cores from the base policy. This framework eliminates the need for precise system estimation and policy retraining while preserving optimal behavior and strong generalization. We provide a theoretical analysis validating this method, supported by numerical evaluations on three contact-rich manipulation primitives. Both simulation and real-world experiments demonstrate its ability to generate robust policies for diverse instances.
Robust Manipulation Primitive Learning via Domain Contraction
Oct 15, 2024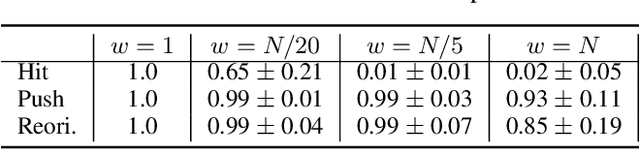



Contact-rich manipulation plays an important role in human daily activities, but uncertain parameters pose significant challenges for robots to achieve comparable performance through planning and control. To address this issue, domain adaptation and domain randomization have been proposed for robust policy learning. However, they either lose the generalization ability across diverse instances or perform conservatively due to neglecting instance-specific information. In this paper, we propose a bi-level approach to learn robust manipulation primitives, including parameter-augmented policy learning using multiple models, and parameter-conditioned policy retrieval through domain contraction. This approach unifies domain randomization and domain adaptation, providing optimal behaviors while keeping generalization ability. We validate the proposed method on three contact-rich manipulation primitives: hitting, pushing, and reorientation. The experimental results showcase the superior performance of our approach in generating robust policies for instances with diverse physical parameters.
Logic-Skill Programming: An Optimization-based Approach to Sequential Skill Planning
May 07, 2024


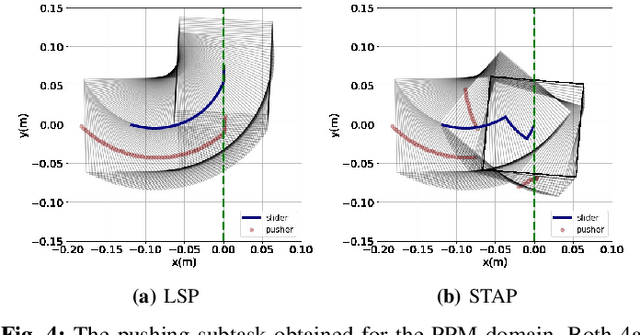
Recent advances in robot skill learning have unlocked the potential to construct task-agnostic skill libraries, facilitating the seamless sequencing of multiple simple manipulation primitives (aka. skills) to tackle significantly more complex tasks. Nevertheless, determining the optimal sequence for independently learned skills remains an open problem, particularly when the objective is given solely in terms of the final geometric configuration rather than a symbolic goal. To address this challenge, we propose Logic-Skill Programming (LSP), an optimization-based approach that sequences independently learned skills to solve long-horizon tasks. We formulate a first-order extension of a mathematical program to optimize the overall cumulative reward of all skills within a plan, abstracted by the sum of value functions. To solve such programs, we leverage the use of Tensor Train to construct the value function space, and rely on alternations between symbolic search and skill value optimization to find the appropriate skill skeleton and optimal subgoal sequence. Experimental results indicate that the obtained value functions provide a superior approximation of cumulative rewards compared to state-of-the-art Reinforcement Learning methods. Furthermore, we validate LSP in three manipulation domains, encompassing both prehensile and non-prehensile primitives. The results demonstrate its capability to identify the optimal solution over the full logic and geometric path. The real-robot experiments showcase the effectiveness of our approach to cope with contact uncertainty and external disturbances in the real world.
Logic Dynamic Movement Primitives for Long-horizon Manipulation Tasks in Dynamic Environments
Apr 24, 2024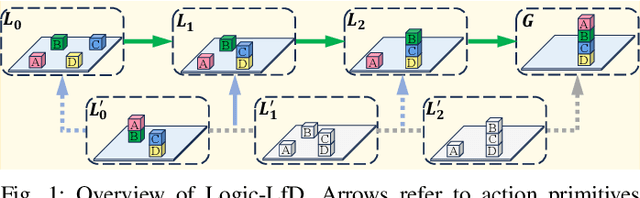

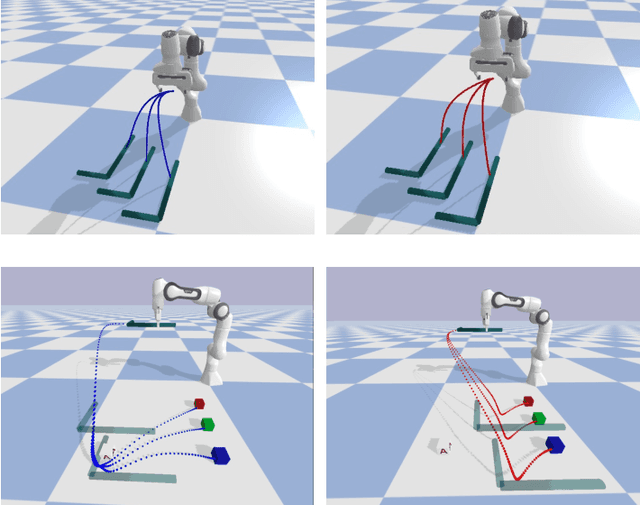

Learning from Demonstration (LfD) stands as an efficient framework for imparting human-like skills to robots. Nevertheless, designing an LfD framework capable of seamlessly imitating, generalizing, and reacting to disturbances for long-horizon manipulation tasks in dynamic environments remains a challenge. To tackle this challenge, we present Logic Dynamic Movement Primitives (Logic-DMP), which combines Task and Motion Planning (TAMP) with an optimal control formulation of DMP, allowing us to incorporate motion-level via-point specifications and to handle task-level variations or disturbances in dynamic environments. We conduct a comparative analysis of our proposed approach against several baselines, evaluating its generalization ability and reactivity across three long-horizon manipulation tasks. Our experiment demonstrates the fast generalization and reactivity of Logic-DMP for handling task-level variants and disturbances in long-horizon manipulation tasks.
D-LGP: Dynamic Logic-Geometric Program for Combined Task and Motion Planning
Dec 05, 2023
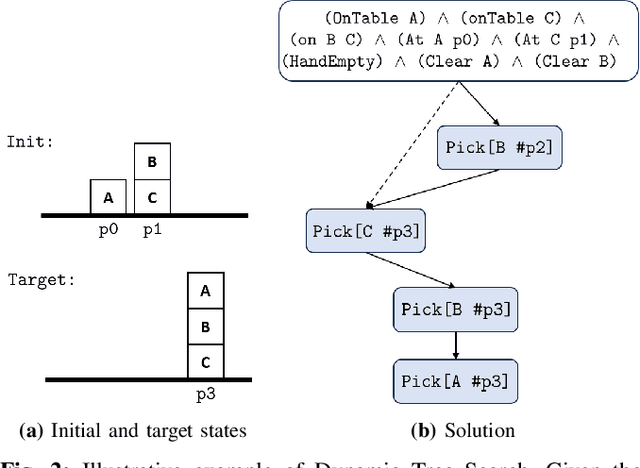

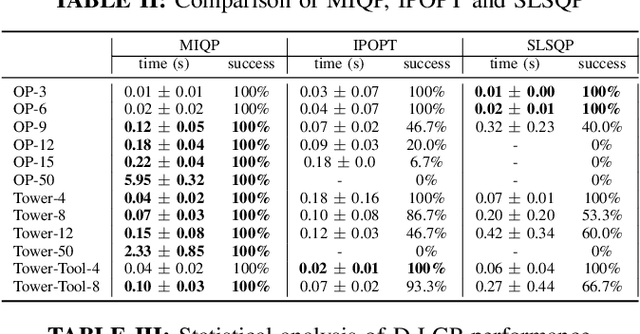
Many real-world sequential manipulation tasks involve a combination of discrete symbolic search and continuous motion planning, collectively known as combined task and motion planning (TAMP). However, prevailing methods often struggle with the computational burden and intricate combinatorial challenges stemming from the multitude of action skeletons. To address this, we propose Dynamic Logic-Geometric Program (D-LGP), a novel approach integrating Dynamic Tree Search and global optimization for efficient hybrid planning. Through empirical evaluation on three benchmarks, we demonstrate the efficacy of our approach, showcasing superior performance in comparison to state-of-the-art techniques. We validate our approach through simulation and demonstrate its capability for online replanning under uncertainty and external disturbances in the real world.
Projection-based first-order constrained optimization solver for robotics
Jun 30, 2023Robot programming tools ranging from inverse kinematics (IK) to model predictive control (MPC) are most often described as constrained optimization problems. Even though there are currently many commercially-available second-order solvers, robotics literature recently focused on efficient implementations and improvements over these solvers for real-time robotic applications. However, most often, these implementations stay problem-specific and are not easy to access or implement, or do not exploit the geometric aspect of the robotics problems. In this work, we propose to solve these problems using a fast, easy-to-implement first-order method that fully exploits the geometric constraints via Euclidean projections, called Augmented Lagrangian Spectral Projected Gradient Descent (ALSPG). We show that 1. using projections instead of full constraints and gradients improves the performance of the solver and 2. ALSPG stays competitive to the standard second-order methods such as iLQR in the unconstrained case. We showcase these results with IK and motion planning problems on simulated examples and with an MPC problem on a 7-axis manipulator experiment.
Contact Optimization with Learning from Demonstration: Application in Long-term Non-prehensile Planar Manipulation
May 19, 2023Long-term non-prehensile planar manipulation is a challenging task for planning and control, requiring determination of both continuous and discrete contact configurations, such as contact points and modes. This leads to the non-convexity and hybridness of contact optimization. To overcome these difficulties, we propose a novel approach that incorporates human demonstrations into trajectory optimization. We show that our approach effectively handles the hybrid combinatorial nature of the problem, mitigates the issues with local minima present in current state-of-the-art solvers, and requires only a small number of demonstrations while delivering robust generalization performance. We validate our results in simulation and demonstrate its applicability on a pusher-slider system with a real Franka Emika robot.