 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpline Policy: A Structured Representation for Robot Policies
Jun 05, 2026Modern imitation-learning policies for robot manipulation often represent actions as fixed-resolution action chunks, which are simple and effective but expose limited geometric and temporal structure before execution. This paper studies Spline Policy (SP), a structured representation that replaces action chunks with spline parameters while keeping the policy backbone unchanged. The predicted spline can be decoded as a compact continuous trajectory, queried at different temporal resolutions, constrained or edited in parameter space, and passed to downstream controllers. For quadratic spline outputs, the same representation can also be converted into a state-dependent vector field through an analytical distance-field construction. Under the regularity and projection assumptions of this construction, the induced dynamics do not increase the distance to the generated spline, yielding a principled local corrective mechanism around the predicted motion. The spline output further supports uncertainty propagation from observations to spline parameters, trajectories, and flow fields, and can be combined with classical control mechanisms such as null-space collision avoidance without retraining the policy backbone. We instantiate SP with diffusion, flow-matching, transformer-based, and vision-language-action backbones. Experiments in low-dimensional motion learning, simulated manipulation under matched backbones, dexterous manipulation, and real-robot case studies show that SP remains compatible with modern policy learners while exposing useful motion-structure properties, including compact decoding, temporal resampling, local correction around predicted motions, uncertainty evaluation, and controller compatibility.
Ergodic Imitation for Adaptive Exploration around Demonstrations
May 13, 2026In robotics, a common challenge in imitation learning is the mismatch between training and deployment conditions, caused, for example, by environmental changes or imperfect observation and control. When a robot follows a nominal trajectory under such mismatch, it may become stuck and fail to complete the task. This calls for adaptive online exploration strategies that remain grounded in demonstrations. To this end, we propose an adaptive ergodic imitation approach that constructs a target distribution from the geometry of the retrieved demonstrations and uses it to generate trajectories that adaptively interpolate between tracking and exploration. Our method extends ergodic control beyond its traditional role in area-coverage and search by incorporating demonstrations into a retrieval-based receding-horizon framework for adaptive imitation.
Curve-Induced Dynamical Systems on Riemannian Manifolds and Lie Groups
Mar 05, 2026Deploying robots in household environments requires safe, adaptable, and interpretable behaviors that respect the geometric structure of tasks. Often represented on Lie groups and Riemannian manifolds, this includes poses on SE(3) or symmetric positive definite matrices encoding stiffness or damping matrices. In this context, dynamical system-based approaches offer a natural framework for generating such behavior, providing stability and convergence while remaining responsive to changes in the environment. We introduce Curve-induced Dynamical systems on Smooth Manifolds (CDSM), a real-time framework for constructing dynamical systems directly on Riemannian manifolds and Lie groups. The proposed approach constructs a nominal curve on the manifold, and generates a dynamical system which combines a tangential component that drives motion along the curve and a normal component that attracts the state toward the curve. We provide a stability analysis of the resulting dynamical system and validate the method quantitatively. On an S2 benchmark, CDSM demonstrates improved trajectory accuracy, reduced path deviation, and faster generation and query times compared to state-of-the-art methods. Finally, we demonstrate the practical applicability of the framework on both a robotic manipulator, where poses on SE(3) and damping matrices on SPD(n) are adapted online, and a mobile manipulator.
Smoothly Differentiable and Efficiently Vectorizable Contact Manifold Generation
Feb 23, 2026Simulating rigid-body dynamics with contact in a fast, massively vectorizable, and smoothly differentiable manner is highly desirable in robotics. An important bottleneck faced by existing differentiable simulation frameworks is contact manifold generation: representing the volume of intersection between two colliding geometries via a discrete set of properly distributed contact points. A major factor contributing to this bottleneck is that the related routines of commonly used robotics simulators were not designed with vectorization and differentiability as a primary concern, and thus rely on logic and control flow that hinder these goals. We instead propose a framework designed from the ground up with these goals in mind, by trying to strike a middle ground between: i) convex primitive based approaches used by common robotics simulators (efficient but not differentiable), and ii) mollified vertex-face and edge-edge unsigned distance-based approaches used by barrier methods (differentiable but inefficient). Concretely, we propose: i) a representative set of smooth analytical signed distance primitives to implement vertex-face collisions, and ii) a novel differentiable edge-edge collision routine that can provide signed distances and signed contact normals. The proposed framework is evaluated via a set of didactic experiments and benchmarked against the collision detection routine of the well-established Mujoco XLA framework, where we observe a significant speedup. Supplementary videos can be found at https://github.com/bekeronur/contax, where a reference implementation in JAX will also be made available at the conclusion of the review process.
Fast and Safe Trajectory Optimization for Mobile Manipulators With Neural Configuration Space Distance Field
Jan 27, 2026Mobile manipulators promise agile, long-horizon behavior by coordinating base and arm motion, yet whole-body trajectory optimization in cluttered, confined spaces remains difficult due to high-dimensional nonconvexity and the need for fast, accurate collision reasoning. Configuration Space Distance Fields (CDF) enable fixed-base manipulators to model collisions directly in configuration space via smooth, implicit distances. This representation holds strong potential to bypass the nonlinear configuration-to-workspace mapping while preserving accurate whole-body geometry and providing optimization-friendly collision costs. Yet, extending this capability to mobile manipulators is hindered by unbounded workspaces and tighter base-arm coupling. We lift this promise to mobile manipulation with Generalized Configuration Space Distance Fields (GCDF), extending CDF to robots with both translational and rotational joints in unbounded workspaces with tighter base-arm coupling. We prove that GCDF preserves Euclidean-like local distance structure and accurately encodes whole-body geometry in configuration space, and develop a data generation and training pipeline that yields continuous neural GCDFs with accurate values and gradients, supporting efficient GPU-batched queries. Building on this representation, we develop a high-performance sequential convex optimization framework centered on GCDF-based collision reasoning. The solver scales to large numbers of implicit constraints through (i) online specification of neural constraints, (ii) sparsity-aware active-set detection with parallel batched evaluation across thousands of constraints, and (iii) incremental constraint management for rapid replanning under scene changes.
Diffusion-based Inverse Model of a Distributed Tactile Sensor for Object Pose Estimation
Jan 19, 2026Tactile sensing provides a promising sensing modality for object pose estimation in manipulation settings where visual information is limited due to occlusion or environmental effects. However, efficiently leveraging tactile data for estimation remains a challenge due to partial observability, with single observations corresponding to multiple possible contact configurations. This limits conventional estimation approaches largely tailored to vision. We propose to address these challenges by learning an inverse tactile sensor model using denoising diffusion. The model is conditioned on tactile observations from a distributed tactile sensor and trained in simulation using a geometric sensor model based on signed distance fields. Contact constraints are enforced during inference through single-step projection using distance and gradient information from the signed distance field. For online pose estimation, we integrate the inverse model with a particle filter through a proposal scheme that combines generated hypotheses with particles from the prior belief. Our approach is validated in simulated and real-world planar pose estimation settings, without access to visual data or tight initial pose priors. We further evaluate robustness to unmodeled contact and sensor dynamics for pose tracking in a box-pushing scenario. Compared to local sampling baselines, the inverse sensor model improves sampling efficiency and estimation accuracy while preserving multimodal beliefs across objects with varying tactile discriminability.
Interactive Motion Planning for Human-Robot Collaboration Based on Human-Centric Configuration Space Ergonomic Field
Dec 16, 2025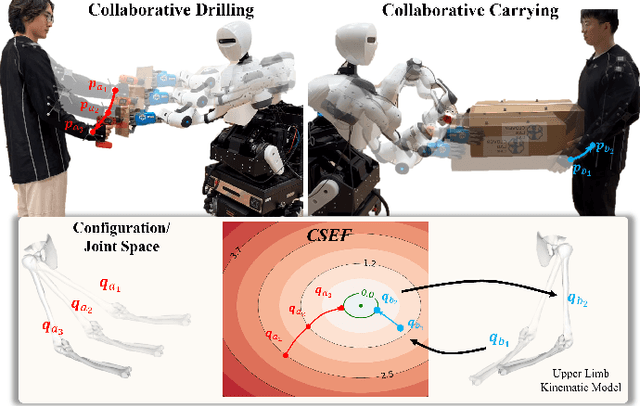
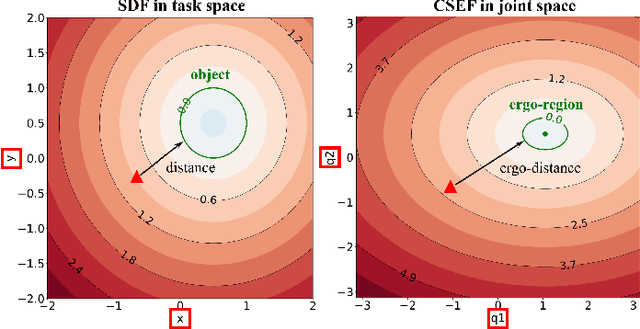
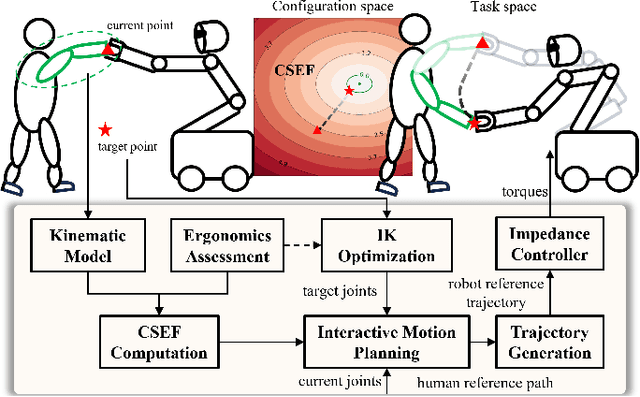
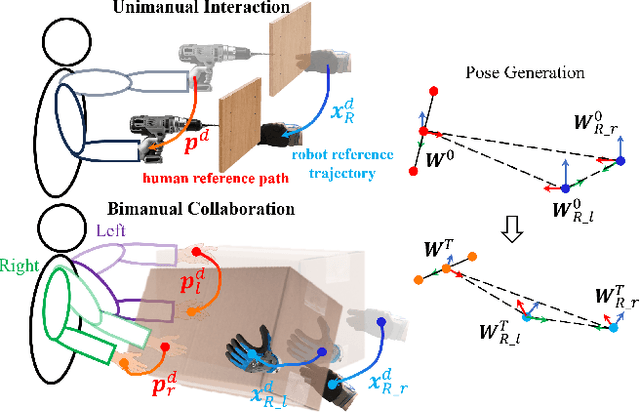
Industrial human-robot collaboration requires motion planning that is collision-free, responsive, and ergonomically safe to reduce fatigue and musculoskeletal risk. We propose the Configuration Space Ergonomic Field (CSEF), a continuous and differentiable field over the human joint space that quantifies ergonomic quality and provides gradients for real-time ergonomics-aware planning. An efficient algorithm constructs CSEF from established metrics with joint-wise weighting and task conditioning, and we integrate it into a gradient-based planner compatible with impedance-controlled robots. In a 2-DoF benchmark, CSEF-based planning achieves higher success rates, lower ergonomic cost, and faster computation than a task-space ergonomic planner. Hardware experiments with a dual-arm robot in unimanual guidance, collaborative drilling, and bimanual cocarrying show faster ergonomic cost reduction, closer tracking to optimized joint targets, and lower muscle activation than a point-to-point baseline. CSEF-based planning method reduces average ergonomic scores by up to 10.31% for collaborative drilling tasks and 5.60% for bimanual co-carrying tasks while decreasing activation in key muscle groups, indicating practical benefits for real-world deployment.
Neural Image Abstraction Using Long Smoothing B-Splines
Nov 07, 2025We integrate smoothing B-splines into a standard differentiable vector graphics (DiffVG) pipeline through linear mapping, and show how this can be used to generate smooth and arbitrarily long paths within image-based deep learning systems. We take advantage of derivative-based smoothing costs for parametric control of fidelity vs. simplicity tradeoffs, while also enabling stylization control in geometric and image spaces. The proposed pipeline is compatible with recent vector graphics generation and vectorization methods. We demonstrate the versatility of our approach with four applications aimed at the generation of stylized vector graphics: stylized space-filling path generation, stroke-based image abstraction, closed-area image abstraction, and stylized text generation.
Cooperative Task Spaces for Multi-Arm Manipulation Control based on Similarity Transformations
Oct 30, 2025Many tasks in human environments require collaborative behavior between multiple kinematic chains, either to provide additional support for carrying big and bulky objects or to enable the dexterity that is required for in-hand manipulation. Since these complex systems often have a very high number of degrees of freedom coordinating their movements is notoriously difficult to model. In this article, we present the derivation of the theoretical foundations for cooperative task spaces of multi-arm robotic systems based on geometric primitives defined using conformal geometric algebra. Based on the similarity transformations of these cooperative geometric primitives, we derive an abstraction of complex robotic systems that enables representing these systems in a way that directly corresponds to single-arm systems. By deriving the associated analytic and geometric Jacobian matrices, we then show the straightforward integration of our approach into classical control techniques rooted in operational space control. We demonstrate this using bimanual manipulators, humanoids and multi-fingered hands in optimal control experiments for reaching desired geometric primitives and in teleoperation experiments using differential kinematics control. We then discuss how the geometric primitives naturally embed nullspace structures into the controllers that can be exploited for introducing secondary control objectives. This work, represents the theoretical foundations of this cooperative manipulation control framework, and thus the experiments are presented in an abstract way, while giving pointers towards potential future applications.
ManiDP: Manipulability-Aware Diffusion Policy for Posture-Dependent Bimanual Manipulation
Oct 27, 2025Recent work has demonstrated the potential of diffusion models in robot bimanual skill learning. However, existing methods ignore the learning of posture-dependent task features, which are crucial for adapting dual-arm configurations to meet specific force and velocity requirements in dexterous bimanual manipulation. To address this limitation, we propose Manipulability-Aware Diffusion Policy (ManiDP), a novel imitation learning method that not only generates plausible bimanual trajectories, but also optimizes dual-arm configurations to better satisfy posture-dependent task requirements. ManiDP achieves this by extracting bimanual manipulability from expert demonstrations and encoding the encapsulated posture features using Riemannian-based probabilistic models. These encoded posture features are then incorporated into a conditional diffusion process to guide the generation of task-compatible bimanual motion sequences. We evaluate ManiDP on six real-world bimanual tasks, where the experimental results demonstrate a 39.33$\%$ increase in average manipulation success rate and a 0.45 improvement in task compatibility compared to baseline methods. This work highlights the importance of integrating posture-relevant robotic priors into bimanual skill diffusion to enable human-like adaptability and dexterity.