 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASP: Language-Driven Robot Skill Selection and Composition using Task-Parameterized Learning
Jun 06, 2026Enabling robots to understand and execute tasks from natural language commands while maintaining data efficiency remains challenging. Foundation models such as vision-language-action (VLA) and vision-language models (VLMs) provide intuitive interaction channels but require extensive data; task-parameterized imitation learning achieves data efficiency but lacks natural language grounding. This work bridges this gap through a modular architecture combining task-parameterized kernelized movement primitives (TP-KMPs) with pretrained VLMs. During learning, skills are acquired from 2 to 5 kinesthetic demonstrations, and the VLM generates skill schemas describing each skill's parameters and preconditions. During execution, the VLM interprets commands to select skills, reason about parameter bindings, and create novel behaviors through covariance-weighted composition. When no skill or composition suffices, the system identifies capability gaps and requests targeted demonstrations, all without fine-tuning. Validation on a 7-DoF manipulator shows success rates of 73.3%-100% in scenarios requiring skill selection, composition, and active learning.
Passive Variable Impedance For Shared Control
Apr 22, 2026Shared Control methods often use impedance control to track target poses in a robotic manipulator. The guidance behavior of such controllers is shaped by the used stiffness gains, which can be varying over time to achieve an adaptive guiding. When multiple target poses are tracked at the same time with varying importance, the corresponding output wrenches have to be arbitrated with weightings changing over time. In this work, we study the stabilization of both variable stiffness in impedance control as well as the arbitration of different controllers through a scaled addition of their output wrenches, reformulating both into a holistic framework. We identify passivity violations in the closed loop system and provide methods to passivate the system. The resulting approach can be used to stabilize standard impedance controllers, allowing for the development of novel and flexible shared control methods. We do not constrain the design of stiffness matrices or arbitration factors; both can be matrix-valued including off-diagonal elements and change arbitrarily over time. The proposed methods are furthermore validated in simulation as well as in real robot experiments on different systems, proving their effectiveness and showcasing different behaviors which can be utilized depending on the requirements of the shared control approach.
MOMO: A framework for seamless physical, verbal, and graphical robot skill learning and adaptation
Apr 22, 2026Industrial robot applications require increasingly flexible systems that non-expert users can easily adapt for varying tasks and environments. However, different adaptations benefit from different interaction modalities. We present an interactive framework that enables robot skill adaptation through three complementary modalities: kinesthetic touch for precise spatial corrections, natural language for high-level semantic modifications, and a graphical web interface for visualizing geometric relations and trajectories, inspecting and adjusting parameters, and editing via-points by drag-and-drop. The framework integrates five components: energy-based human-intention detection, a tool-based LLM architecture (where the LLM selects and parameterizes predefined functions rather than generating code) for safe natural language adaptation, Kernelized Movement Primitives (KMPs) for motion encoding, probabilistic Virtual Fixtures for guided demonstration recording, and ergodic control for surface finishing. We demonstrate that this tool-based LLM architecture generalizes skill adaptation from KMPs to ergodic control, enabling voice-commanded surface finishing. Validation on a 7-DoF torque-controlled robot at the Automatica 2025 trade fair demonstrates the practical applicability of our approach in industrial settings.
IROSA: Interactive Robot Skill Adaptation using Natural Language
Mar 04, 2026Foundation models have demonstrated impressive capabilities across diverse domains, while imitation learning provides principled methods for robot skill adaptation from limited data. Combining these approaches holds significant promise for direct application to robotics, yet this combination has received limited attention, particularly for industrial deployment. We present a novel framework that enables open-vocabulary skill adaptation through a tool-based architecture, maintaining a protective abstraction layer between the language model and robot hardware. Our approach leverages pre-trained LLMs to select and parameterize specific tools for adapting robot skills without requiring fine-tuning or direct model-to-robot interaction. We demonstrate the framework on a 7-DoF torque-controlled robot performing an industrial bearing ring insertion task, showing successful skill adaptation through natural language commands for speed adjustment, trajectory correction, and obstacle avoidance while maintaining safety, transparency, and interpretability.
Are Foundation Models the Route to Full-Stack Transfer in Robotics?
Feb 25, 2026In humans and robots alike, transfer learning occurs at different levels of abstraction, from high-level linguistic transfer to low-level transfer of motor skills. In this article, we provide an overview of the impact that foundation models and transformer networks have had on these different levels, bringing robots closer than ever to "full-stack transfer". Considering LLMs, VLMs and VLAs from a robotic transfer learning perspective allows us to highlight recurring concepts for transfer, beyond specific implementations. We also consider the challenges of data collection and transfer benchmarks for robotics in the age of foundation models. Are foundation models the route to full-stack transfer in robotics? Our expectation is that they will certainly stay on this route as a key technology.
Model Reconciliation through Explainability and Collaborative Recovery in Assistive Robotics
Jan 10, 2026Whenever humans and robots work together, it is essential that unexpected robot behavior can be explained to the user. Especially in applications such as shared control the user and the robot must share the same model of the objects in the world, and the actions that can be performed on these objects. In this paper, we achieve this with a so-called model reconciliation framework. We leverage a Large Language Model to predict and explain the difference between the robot's and the human's mental models, without the need of a formal mental model of the user. Furthermore, our framework aims to solve the model divergence after the explanation by allowing the human to correct the robot. We provide an implementation in an assistive robotics domain, where we conduct a set of experiments with a real wheelchair-based mobile manipulator and its digital twin.
A Unified Framework for Probabilistic Dynamic-, Trajectory- and Vision-based Virtual Fixtures
Jun 11, 2025Probabilistic Virtual Fixtures (VFs) enable the adaptive selection of the most suitable haptic feedback for each phase of a task, based on learned or perceived uncertainty. While keeping the human in the loop remains essential, for instance, to ensure high precision, partial automation of certain task phases is critical for productivity. We present a unified framework for probabilistic VFs that seamlessly switches between manual fixtures, semi-automated fixtures (with the human handling precise tasks), and full autonomy. We introduce a novel probabilistic Dynamical System-based VF for coarse guidance, enabling the robot to autonomously complete certain task phases while keeping the human operator in the loop. For tasks requiring precise guidance, we extend probabilistic position-based trajectory fixtures with automation allowing for seamless human interaction as well as geometry-awareness and optimal impedance gains. For manual tasks requiring very precise guidance, we also extend visual servoing fixtures with the same geometry-awareness and impedance behaviour. We validate our approach experimentally on different robots, showcasing multiple operation modes and the ease of programming fixtures.
State- and context-dependent robotic manipulation and grasping via uncertainty-aware imitation learning
Oct 31, 2024
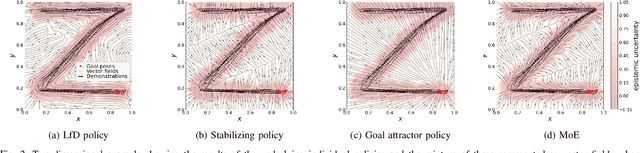

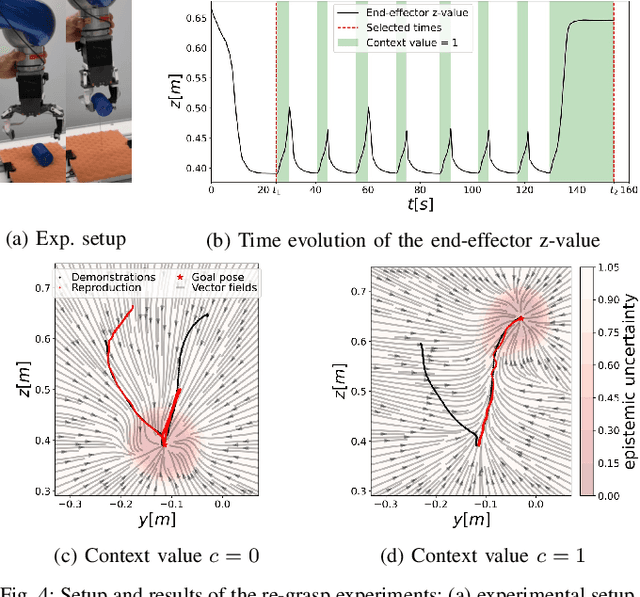
Generating context-adaptive manipulation and grasping actions is a challenging problem in robotics. Classical planning and control algorithms tend to be inflexible with regard to parameterization by external variables such as object shapes. In contrast, Learning from Demonstration (LfD) approaches, due to their nature as function approximators, allow for introducing external variables to modulate policies in response to the environment. In this paper, we utilize this property by introducing an LfD approach to acquire context-dependent grasping and manipulation strategies. We treat the problem as a kernel-based function approximation, where the kernel inputs include generic context variables describing task-dependent parameters such as the object shape. We build on existing work on policy fusion with uncertainty quantification to propose a state-dependent approach that automatically returns to demonstrations, avoiding unpredictable behavior while smoothly adapting to context changes. The approach is evaluated against the LASA handwriting dataset and on a real 7-DoF robot in two scenarios: adaptation to slippage while grasping and manipulating a deformable food item.
Interactive incremental learning of generalizable skills with local trajectory modulation
Sep 09, 2024The problem of generalization in learning from demonstration (LfD) has received considerable attention over the years, particularly within the context of movement primitives, where a number of approaches have emerged. Recently, two important approaches have gained recognition. While one leverages via-points to adapt skills locally by modulating demonstrated trajectories, another relies on so-called task-parameterized models that encode movements with respect to different coordinate systems, using a product of probabilities for generalization. While the former are well-suited to precise, local modulations, the latter aim at generalizing over large regions of the workspace and often involve multiple objects. Addressing the quality of generalization by leveraging both approaches simultaneously has received little attention. In this work, we propose an interactive imitation learning framework that simultaneously leverages local and global modulations of trajectory distributions. Building on the kernelized movement primitives (KMP) framework, we introduce novel mechanisms for skill modulation from direct human corrective feedback. Our approach particularly exploits the concept of via-points to incrementally and interactively 1) improve the model accuracy locally, 2) add new objects to the task during execution and 3) extend the skill into regions where demonstrations were not provided. We evaluate our method on a bearing ring-loading task using a torque-controlled, 7-DoF, DLR SARA robot.
Unknown Object Grasping for Assistive Robotics
Apr 23, 2024
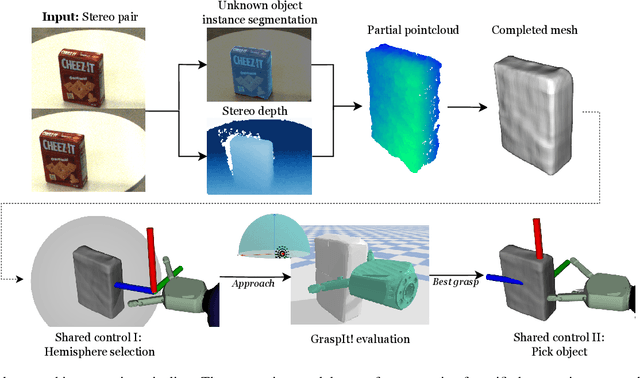
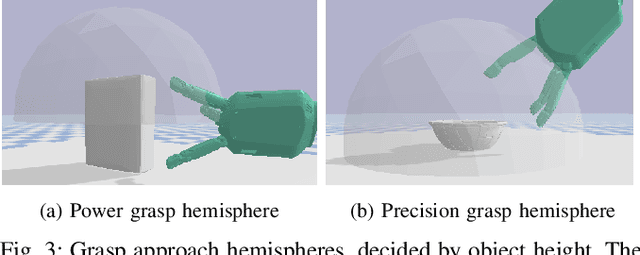
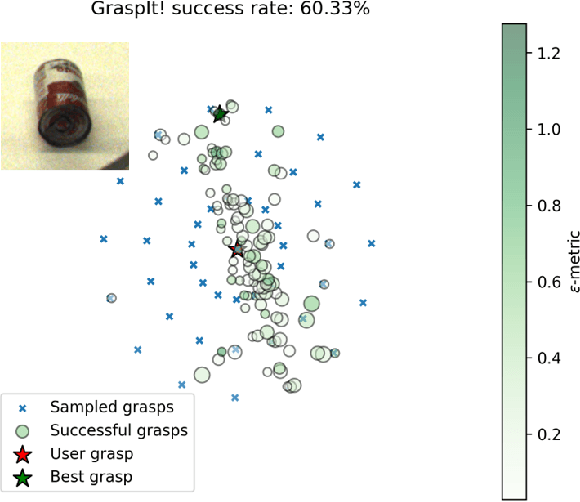
We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.