 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
May 26, 2026Terrain understanding is fundamental for mobile robots operating in unstructured outdoor environments. Existing vision-based traversability estimation methods rely on robot-specific annotations or semantic class mappings, limiting transferability across platforms and requiring costly re-annotation when robot capabilities change, while standard semantic segmentation methods only focus on specific predefined classes, which do not capture the variety of terrains. In this work, we propose a transformer-based architecture that jointly performs class-specific semantic segmentation and class-agnostic terrain segmentation within a unified network, called Trinity. Terrain regions are segmented based solely on visual appearance, without predefined semantic labels or robot-dependent traversability scores. This formulation enables the learning of robot-agnostic visual terrain priors that can be combined with robot-specific experience for downstream tasks such as traversability estimation, visual odometry, and mission planning. To enable large-scale training with diverse terrain appearances, we extend the OAISYS simulator and introduce RUGDSynth, a synthetic dataset inspired by RUGD with class-agnostic terrain samples. Furthermore, we present the EXTerra Dataset, providing real-world images annotated with both class-specific and class-agnostic terrain labels. Experiments demonstrate the feasibility of the proposed task and the effectiveness of our joint segmentation approach in complex outdoor environments. Code and datasets will be released with this publication (after review).
Markerless Robot Detection and 6D Pose Estimation for Multi-Agent SLAM
Feb 18, 2026The capability of multi-robot SLAM approaches to merge localization history and maps from different observers is often challenged by the difficulty in establishing data association. Loop closure detection between perceptual inputs of different robotic agents is easily compromised in the context of perceptual aliasing, or when perspectives differ significantly. For this reason, direct mutual observation among robots is a powerful way to connect partial SLAM graphs, but often relies on the presence of calibrated arrays of fiducial markers (e.g., AprilTag arrays), which severely limits the range of observations and frequently fails under sharp lighting conditions, e.g., reflections or overexposure. In this work, we propose a novel solution to this problem leveraging recent advances in Deep-Learning-based 6D pose estimation. We feature markerless pose estimation as part of a decentralized multi-robot SLAM system and demonstrate the benefit to the relative localization accuracy among the robotic team. The solution is validated experimentally on data recorded in a test field campaign on a planetary analogous environment.
Conditional Latent Diffusion Models for Zero-Shot Instance Segmentation
Aug 06, 2025This paper presents OC-DiT, a novel class of diffusion models designed for object-centric prediction, and applies it to zero-shot instance segmentation. We propose a conditional latent diffusion framework that generates instance masks by conditioning the generative process on object templates and image features within the diffusion model's latent space. This allows our model to effectively disentangle object instances through the diffusion process, which is guided by visual object descriptors and localized image cues. Specifically, we introduce two model variants: a coarse model for generating initial object instance proposals, and a refinement model that refines all proposals in parallel. We train these models on a newly created, large-scale synthetic dataset comprising thousands of high-quality object meshes. Remarkably, our model achieves state-of-the-art performance on multiple challenging real-world benchmarks, without requiring any retraining on target data. Through comprehensive ablation studies, we demonstrate the potential of diffusion models for instance segmentation tasks.
Unknown Object Grasping for Assistive Robotics
Apr 23, 2024
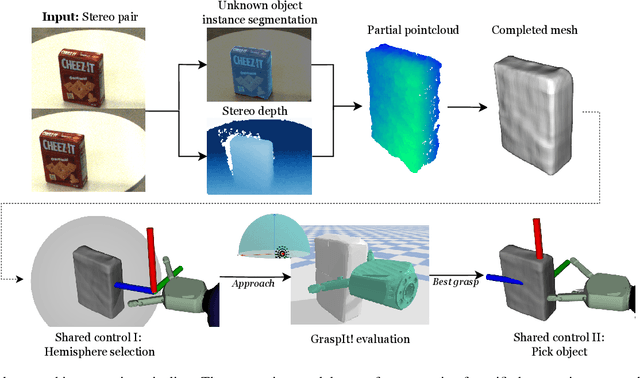
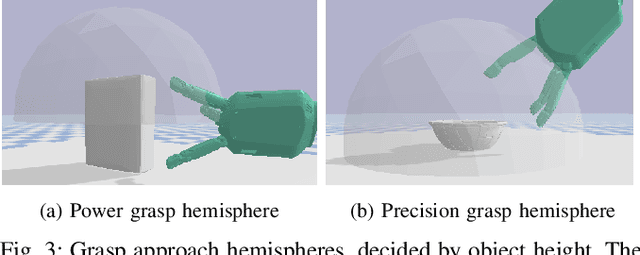
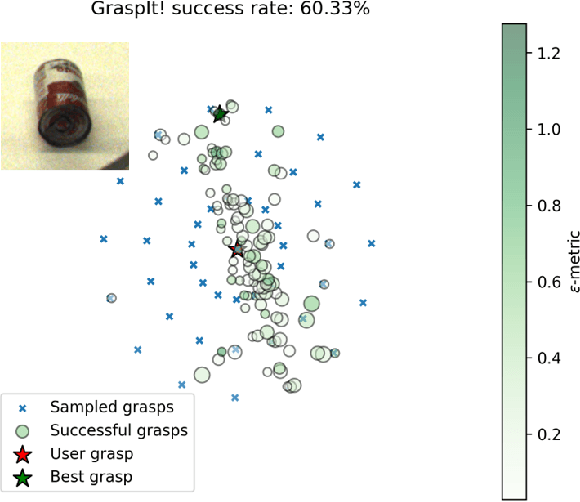
We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.
A Multi-body Tracking Framework -- From Rigid Objects to Kinematic Structures
Aug 02, 2022
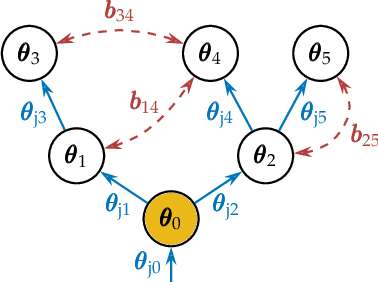
Kinematic structures are very common in the real world. They range from simple articulated objects to complex mechanical systems. However, despite their relevance, most model-based 3D tracking methods only consider rigid objects. To overcome this limitation, we propose a flexible framework that allows the extension of existing 6DoF algorithms to kinematic structures. Our approach focuses on methods that employ Newton-like optimization techniques, which are widely used in object tracking. The framework considers both tree-like and closed kinematic structures and allows a flexible configuration of joints and constraints. To project equations from individual rigid bodies to a multi-body system, Jacobians are used. For closed kinematic chains, a novel formulation that features Lagrange multipliers is developed. In a detailed mathematical proof, we show that our constraint formulation leads to an exact kinematic solution and converges in a single iteration. Based on the proposed framework, we extend ICG, which is a state-of-the-art rigid object tracking algorithm, to multi-body tracking. For the evaluation, we create a highly-realistic synthetic dataset that features a large number of sequences and various robots. Based on this dataset, we conduct a wide variety of experiments that demonstrate the excellent performance of the developed framework and our multi-body tracker.
Unknown Object Segmentation from Stereo Images
Mar 11, 2021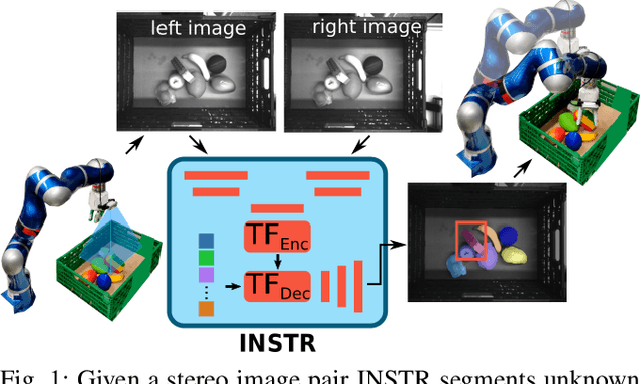


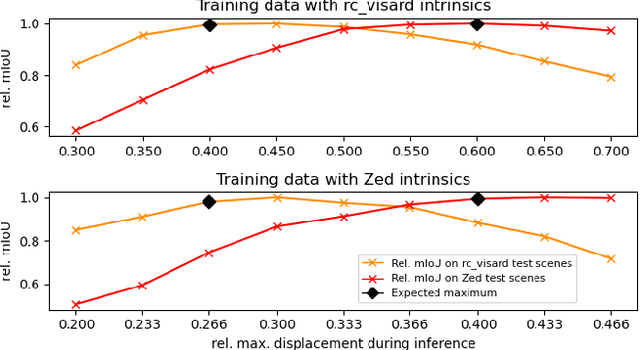
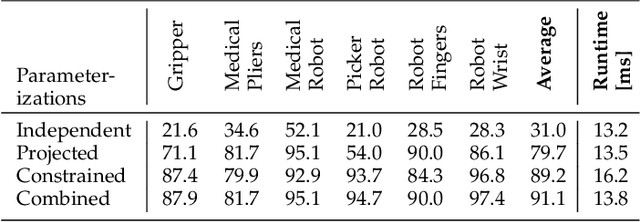
Although instance-aware perception is a key prerequisite for many autonomous robotic applications, most of the methods only partially solve the problem by focusing solely on known object categories. However, for robots interacting in dynamic and cluttered environments, this is not realistic and severely limits the range of potential applications. Therefore, we propose a novel object instance segmentation approach that does not require any semantic or geometric information of the objects beforehand. In contrast to existing works, we do not explicitly use depth data as input, but rely on the insight that slight viewpoint changes, which for example are provided by stereo image pairs, are often sufficient to determine object boundaries and thus to segment objects. Focusing on the versatility of stereo sensors, we employ a transformer-based architecture that maps directly from the pair of input images to the object instances. This has the major advantage that instead of a noisy, and potentially incomplete depth map as an input, on which the segmentation is computed, we use the original image pair to infer the object instances and a dense depth map. In experiments in several different application domains, we show that our Instance Stereo Transformer (INSTR) algorithm outperforms current state-of-the-art methods that are based on depth maps. Training code and pretrained models will be made available.
"What's This?" -- Learning to Segment Unknown Objects from Manipulation Sequences
Nov 06, 2020
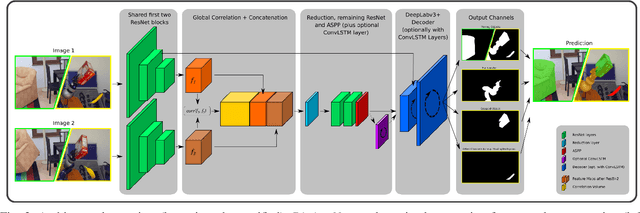


We present a novel framework for self-supervised grasped object segmentation with a robotic manipulator. Our method successively learns an agnostic foreground segmentation followed by a distinction between manipulator and object solely by observing the motion between consecutive RGB frames. In contrast to previous approaches, we propose a single, end-to-end trainable architecture which jointly incorporates motion cues and semantic knowledge. Furthermore, while the motion of the manipulator and the object are substantial cues for our algorithm, we present means to robustly deal with distraction objects moving in the background, as well as with completely static scenes. Our method neither depends on any visual registration of a kinematic robot or 3D object models, nor on precise hand-eye calibration or any additional sensor data. By extensive experimental evaluation we demonstrate the superiority of our framework and provide detailed insights on its capability of dealing with the aforementioned extreme cases of motion. We also show that training a semantic segmentation network with the automatically labeled data achieves results on par with manually annotated training data. Code and pretrained models will be made publicly available.
Self-Supervised Object-in-Gripper Segmentation from Robotic Motions
Mar 03, 2020
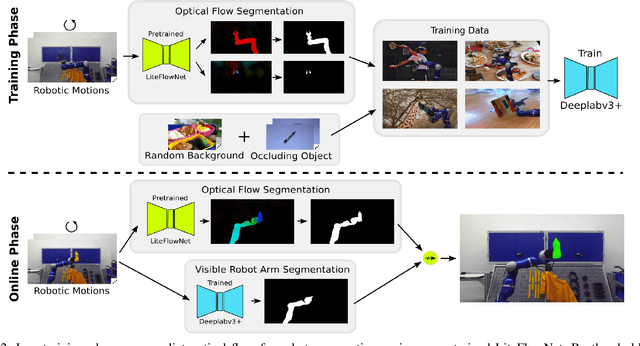

We present a novel technique to automatically generate annotated data for important robotic perception tasks such as object segmentation and 3D object reconstruction using a robot manipulator. Our self-supervised method can segment unknown objects from a robotic gripper in RGB video sequences by exploiting motion and temporal cues. The key aspect of our approach in contrast to existing systems is its independence of any hardware specifics such as extrinsic and intrinsic camera calibration and a robot model. We achieve this using a two-step process: First, we learn to predict segmentation masks for our given manipulator using optical flow estimation. Then, these masks are used in combination with motion cues to automatically distinguish between the manipulator, the background, and the unknown, grasped object. We perform a thorough comparison with alternative baselines and approaches in the literature. The obtained object views and masks are suitable training data for segmentation networks that generalize to novel environments and also allow for watertight 3D object reconstruction.