 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective Robot Perception using Smoothed Predictions from Bayesian Neural Networks
Sep 27, 2021



This work focuses on improving uncertainty estimation in the field of object classification from RGB images and demonstrates its benefits in two robotic applications. We employ a (BNN), and evaluate two practical inference techniques to obtain better uncertainty estimates, namely Concrete Dropout (CDP) and Kronecker-factored Laplace Approximation (LAP). We show a performance increase using more reliable uncertainty estimates as unary potentials within a Conditional Random Field (CRF), which is able to incorporate contextual information as well. Furthermore, the obtained uncertainties are exploited to achieve domain adaptation in a semi-supervised manner, which requires less manual efforts in annotating data. We evaluate our approach on two public benchmark datasets that are relevant for robot perception tasks.
Unknown Object Segmentation from Stereo Images
Mar 11, 2021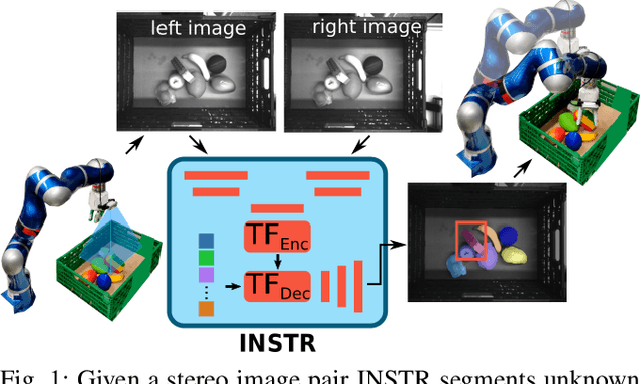


Although instance-aware perception is a key prerequisite for many autonomous robotic applications, most of the methods only partially solve the problem by focusing solely on known object categories. However, for robots interacting in dynamic and cluttered environments, this is not realistic and severely limits the range of potential applications. Therefore, we propose a novel object instance segmentation approach that does not require any semantic or geometric information of the objects beforehand. In contrast to existing works, we do not explicitly use depth data as input, but rely on the insight that slight viewpoint changes, which for example are provided by stereo image pairs, are often sufficient to determine object boundaries and thus to segment objects. Focusing on the versatility of stereo sensors, we employ a transformer-based architecture that maps directly from the pair of input images to the object instances. This has the major advantage that instead of a noisy, and potentially incomplete depth map as an input, on which the segmentation is computed, we use the original image pair to infer the object instances and a dense depth map. In experiments in several different application domains, we show that our Instance Stereo Transformer (INSTR) algorithm outperforms current state-of-the-art methods that are based on depth maps. Training code and pretrained models will be made available.
Multi-path Learning for Object Pose Estimation Across Domains
Aug 01, 2019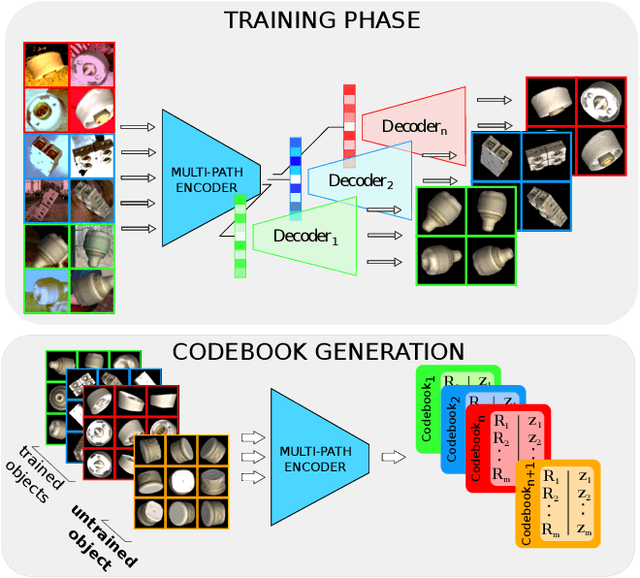

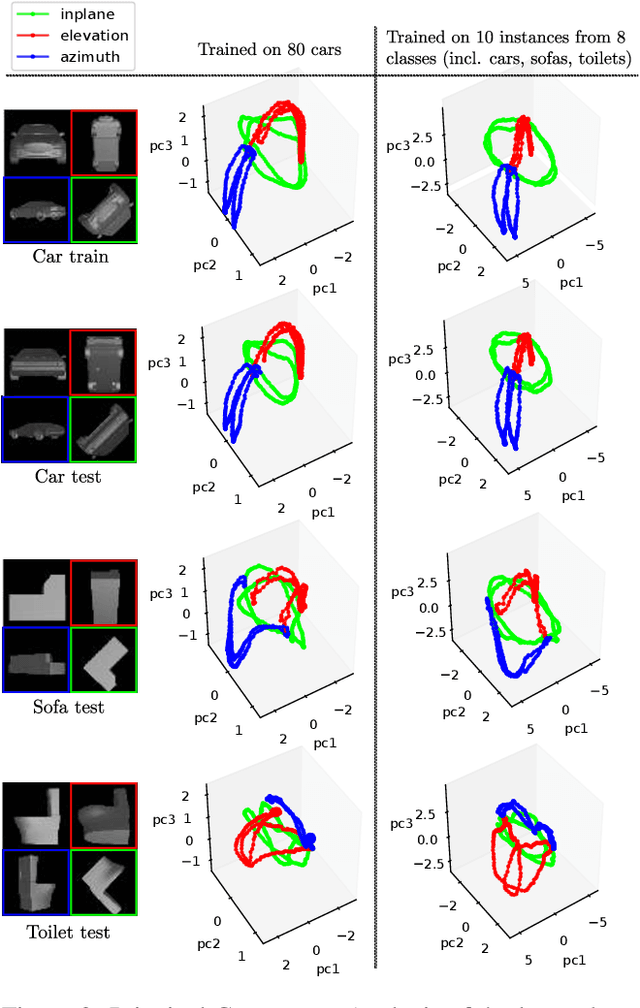
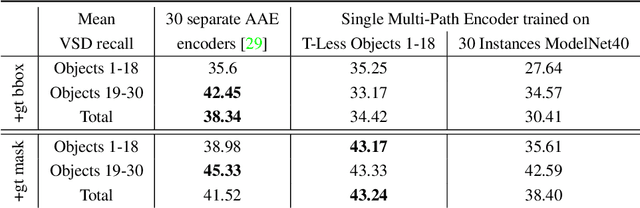
We introduce a scalable approach for object pose estimation trained on simulated RGB views of multiple 3D models together. We learn an encoding of object views that does not only describe the orientation of all objects seen during training, but can also relate views of untrained objects. Our single-encoder-multi-decoder network is trained using a technique we denote "multi-path learning": While the encoder is shared by all objects, each decoder only reconstructs views of a single object. Consequently, views of different instances do not need to be separated in the latent space and can share common features. The resulting encoder generalizes well from synthetic to real data and across various instances, categories, model types and datasets. We systematically investigate the learned encodings, their generalization capabilities and iterative refinement strategies on the ModelNet40 and T-LESS dataset. On T-LESS, we achieve state-of-the-art results with our 6D Object Detection pipeline, both in the RGB and depth domain, outperforming learning-free pipelines at much lower runtimes.
Implicit 3D Orientation Learning for 6D Object Detection from RGB Images
Feb 04, 2019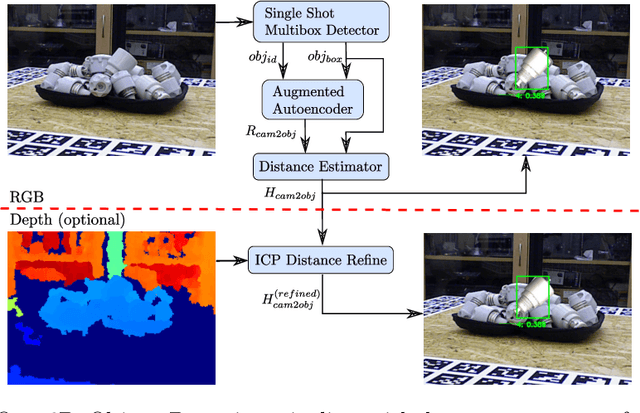



We propose a real-time RGB-based pipeline for object detection and 6D pose estimation. Our novel 3D orientation estimation is based on a variant of the Denoising Autoencoder that is trained on simulated views of a 3D model using Domain Randomization. This so-called Augmented Autoencoder has several advantages over existing methods: It does not require real, pose-annotated training data, generalizes to various test sensors and inherently handles object and view symmetries. Instead of learning an explicit mapping from input images to object poses, it provides an implicit representation of object orientations defined by samples in a latent space. Experiments on the T-LESS and LineMOD datasets show that our method outperforms similar model-based approaches and competes with state-of-the art approaches that require real pose-annotated images.
* Code available at: https://github.com/DLR-RM/AugmentedAutoencoder