 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCHands: PCA-based Hand Pose Synergy Representation on Manipulators with N-DoF
Aug 11, 2025We consider the problem of learning a common representation for dexterous manipulation across manipulators of different morphologies. To this end, we propose PCHands, a novel approach for extracting hand postural synergies from a large set of manipulators. We define a simplified and unified description format based on anchor positions for manipulators ranging from 2-finger grippers to 5-finger anthropomorphic hands. This enables learning a variable-length latent representation of the manipulator configuration and the alignment of the end-effector frame of all manipulators. We show that it is possible to extract principal components from this latent representation that is universal across manipulators of different structures and degrees of freedom. To evaluate PCHands, we use this compact representation to encode observation and action spaces of control policies for dexterous manipulation tasks learned with RL. In terms of learning efficiency and consistency, the proposed representation outperforms a baseline that learns the same tasks in joint space. We additionally show that PCHands performs robustly in RL from demonstration, when demonstrations are provided from a different manipulator. We further support our results with real-world experiments that involve a 2-finger gripper and a 4-finger anthropomorphic hand. Code and additional material are available at https://hsp-iit.github.io/PCHands/.
Learning Stable Robot Grasping with Transformer-based Tactile Control Policies
Jul 30, 2024Measuring grasp stability is an important skill for dexterous robot manipulation tasks, which can be inferred from haptic information with a tactile sensor. Control policies have to detect rotational displacement and slippage from tactile feedback, and determine a re-grasp strategy in term of location and force. Classic stable grasp task only trains control policies to solve for re-grasp location with objects of fixed center of gravity. In this work, we propose a revamped version of stable grasp task that optimises both re-grasp location and gripping force for objects with unknown and moving center of gravity. We tackle this task with a model-free, end-to-end Transformer-based reinforcement learning framework. We show that our approach is able to solve both objectives after training in both simulation and in a real-world setup with zero-shot transfer. We also provide performance analysis of different models to understand the dynamics of optimizing two opposing objectives.
Hierarchical Point Cloud Encoding and Decoding with Lightweight Self-Attention based Model
Feb 13, 2022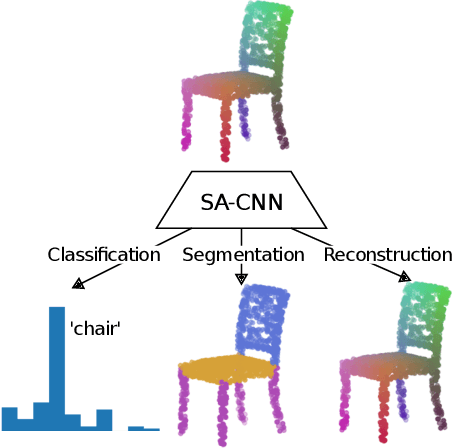
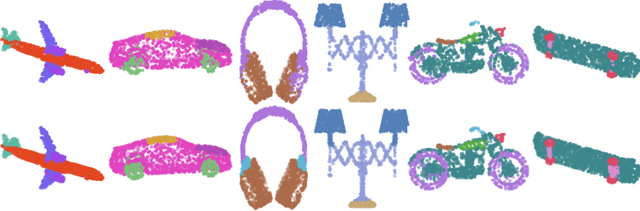

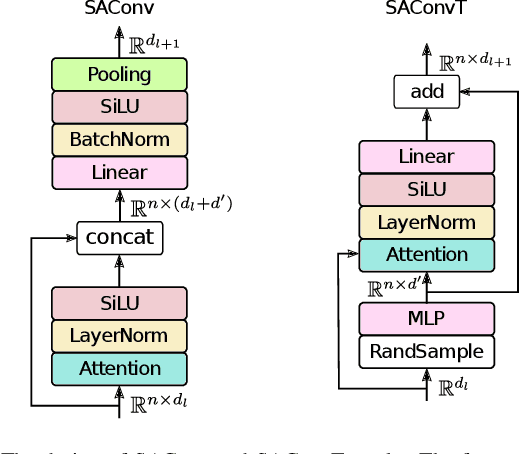
In this paper we present SA-CNN, a hierarchical and lightweight self-attention based encoding and decoding architecture for representation learning of point cloud data. The proposed SA-CNN introduces convolution and transposed convolution stacks to capture and generate contextual information among unordered 3D points. Following conventional hierarchical pipeline, the encoding process extracts feature in local-to-global manner, while the decoding process generates feature and point cloud in coarse-to-fine, multi-resolution stages. We demonstrate that SA-CNN is capable of a wide range of applications, namely classification, part segmentation, reconstruction, shape retrieval, and unsupervised classification. While achieving the state-of-the-art or comparable performance in the benchmarks, SA-CNN maintains its model complexity several order of magnitude lower than the others. In term of qualitative results, we visualize the multi-stage point cloud reconstructions and latent walks on rigid objects as well as deformable non-rigid human and robot models.
End-to-end Reinforcement Learning of Robotic Manipulation with Robust Keypoints Representation
Feb 12, 2022



We present an end-to-end Reinforcement Learning(RL) framework for robotic manipulation tasks, using a robust and efficient keypoints representation. The proposed method learns keypoints from camera images as the state representation, through a self-supervised autoencoder architecture. The keypoints encode the geometric information, as well as the relationship of the tool and target in a compact representation to ensure efficient and robust learning. After keypoints learning, the RL step then learns the robot motion from the extracted keypoints state representation. The keypoints and RL learning processes are entirely done in the simulated environment. We demonstrate the effectiveness of the proposed method on robotic manipulation tasks including grasping and pushing, in different scenarios. We also investigate the generalization capability of the trained model. In addition to the robust keypoints representation, we further apply domain randomization and adversarial training examples to achieve zero-shot sim-to-real transfer in real-world robotic manipulation tasks.
KOVIS: Keypoint-based Visual Servoing with Zero-Shot Sim-to-Real Transfer for Robotics Manipulation
Jul 28, 2020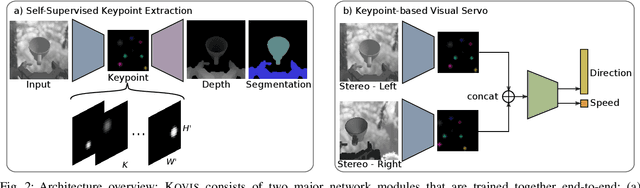
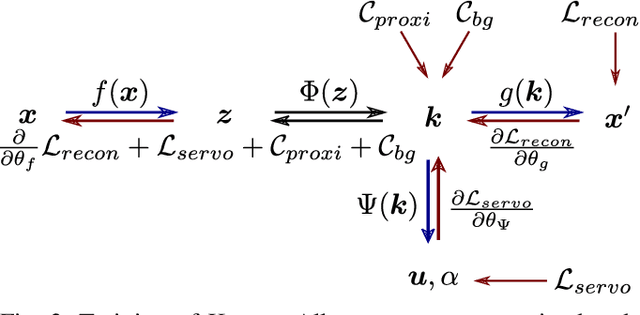
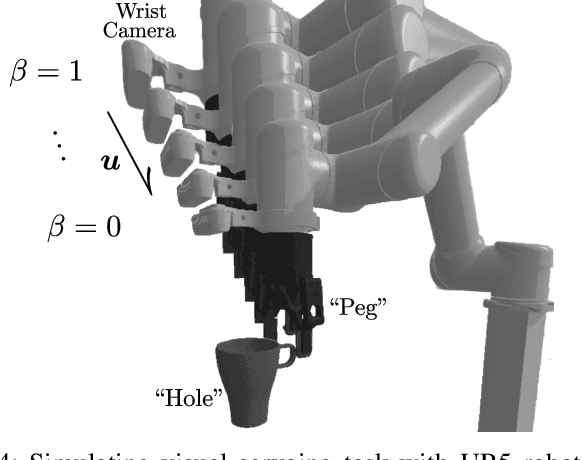
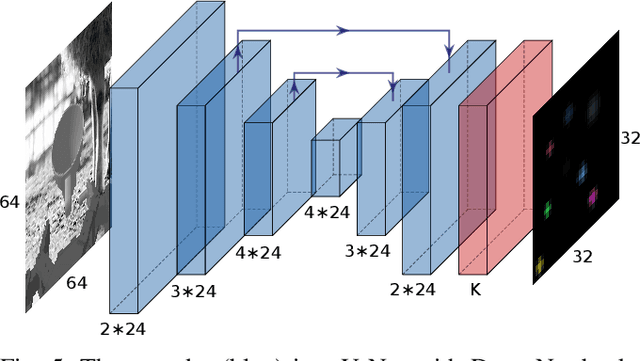
We present KOVIS, a novel learning-based, calibration-free visual servoing method for fine robotic manipulation tasks with eye-in-hand stereo camera system. We train the deep neural network only in the simulated environment; and the trained model could be directly used for real-world visual servoing tasks. KOVIS consists of two networks. The first keypoint network learns the keypoint representation from the image using with an autoencoder. Then the visual servoing network learns the motion based on keypoints extracted from the camera image. The two networks are trained end-to-end in the simulated environment by self-supervised learning without manual data labeling. After training with data augmentation, domain randomization, and adversarial examples, we are able to achieve zero-shot sim-to-real transfer to real-world robotic manipulation tasks. We demonstrate the effectiveness of the proposed method in both simulated environment and real-world experiment with different robotic manipulation tasks, including grasping, peg-in-hole insertion with 4mm clearance, and M13 screw insertion. The demo video is available at http://youtu.be/gfBJBR2tDzA
Multi-path Learning for Object Pose Estimation Across Domains
Aug 01, 2019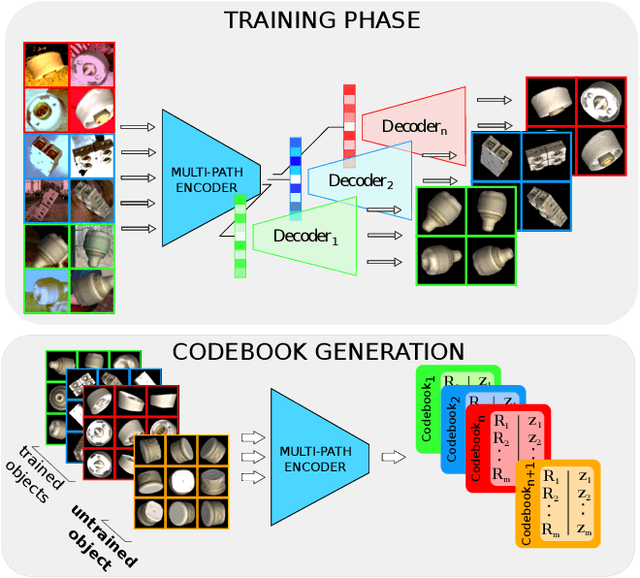

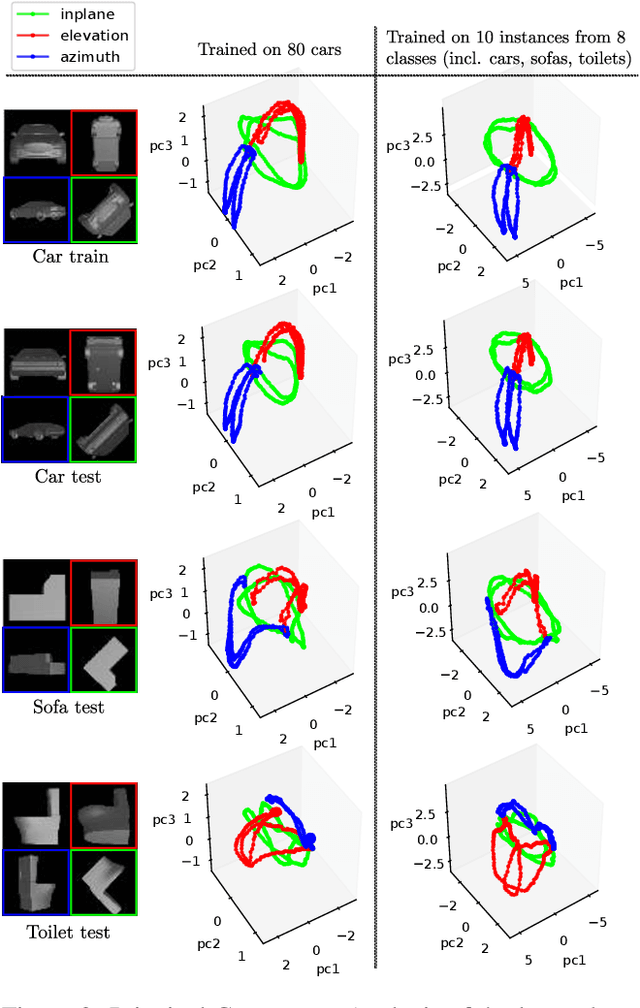
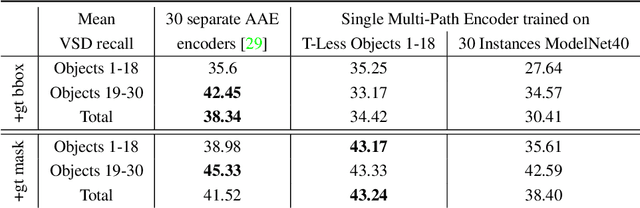
We introduce a scalable approach for object pose estimation trained on simulated RGB views of multiple 3D models together. We learn an encoding of object views that does not only describe the orientation of all objects seen during training, but can also relate views of untrained objects. Our single-encoder-multi-decoder network is trained using a technique we denote "multi-path learning": While the encoder is shared by all objects, each decoder only reconstructs views of a single object. Consequently, views of different instances do not need to be separated in the latent space and can share common features. The resulting encoder generalizes well from synthetic to real data and across various instances, categories, model types and datasets. We systematically investigate the learned encodings, their generalization capabilities and iterative refinement strategies on the ModelNet40 and T-LESS dataset. On T-LESS, we achieve state-of-the-art results with our 6D Object Detection pipeline, both in the RGB and depth domain, outperforming learning-free pipelines at much lower runtimes.
Team NimbRo at MBZIRC 2017: Autonomous Valve Stem Turning using a Wrench
Oct 06, 2018
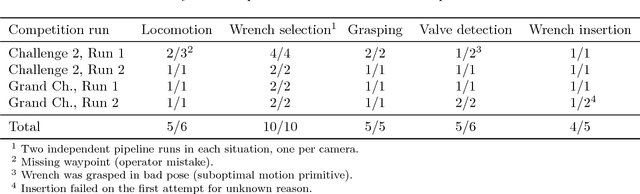


The Mohamed Bin Zayed International Robotics Challenge (MBZIRC) 2017 has defined ambitious new benchmarks to advance the state-of-the-art in autonomous operation of ground-based and flying robots. In this article, we describe our winning entry to MBZIRC Challenge 2: the mobile manipulation robot Mario. It is capable of autonomously solving a valve manipulation task using a wrench tool detected, grasped, and finally employed to turn a valve stem. Mario's omnidirectional base allows both fast locomotion and precise close approach to the manipulation panel. We describe an efficient detector for medium-sized objects in 3D laser scans and apply it to detect the manipulation panel. An object detection architecture based on deep neural networks is used to find and select the correct tool from grayscale images. Parametrized motion primitives are adapted online to percepts of the tool and valve stem in order to turn the stem. We report in detail on our winning performance at the challenge and discuss lessons learned.