 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPNext++: What's Next for Tracking Any Point (TAP)?
Apr 12, 2026Tracking-Any-Point (TAP) models aim to track any point through a video which is a crucial task in AR/XR and robotics applications. The recently introduced TAPNext approach proposes an end-to-end, recurrent transformer architecture to track points frame-by-frame in a purely online fashion -- demonstrating competitive performance at minimal latency. However, we show that TAPNext struggles with longer video sequences and also frequently fails to re-detect query points that reappear after being occluded or leaving the frame. In this work, we present TAPNext++, a model that tracks points in sequences that are orders of magnitude longer while preserving the low memory and compute footprint of the architecture. We train the recurrent video transformer using several data-driven solutions, including training on long 1024-frame sequences enabled by sequence parallelism techniques. We highlight that re-detection performance is a blind spot in the current literature and introduce a new metric, Re-Detection Average Jaccard ($AJ_{RD}$), to explicitly evaluate tracking on re-appearing points. To improve re-detection of points, we introduce tailored geometric augmentations, such as periodic roll that simulates point re-entries, and supervising occluded points. We demonstrate that recurrent transformers can be substantially improved for point tracking and set a new state-of-the-art on multiple benchmarks. Model and code can be found at https://tap-next-plus-plus.github.io.
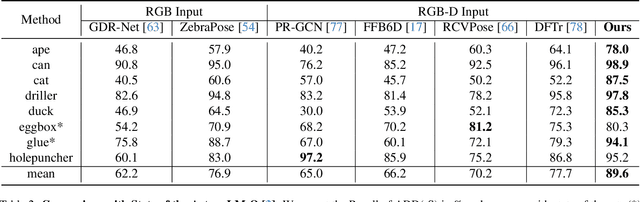
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
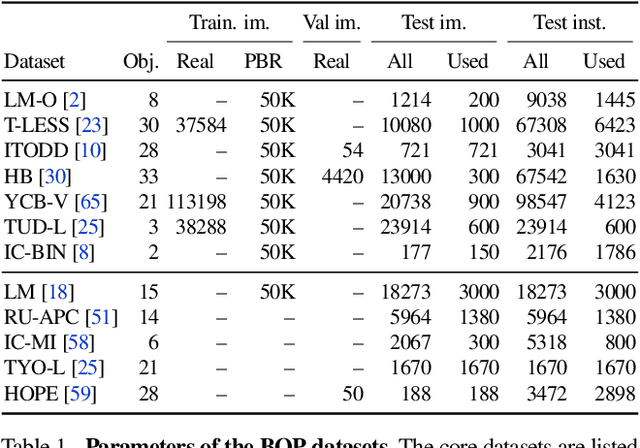
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
Towards Real-Time Open-Vocabulary Video Instance Segmentation
Dec 05, 2024In this paper, we address the challenge of performing open-vocabulary video instance segmentation (OV-VIS) in real-time. We analyze the computational bottlenecks of state-of-the-art foundation models that performs OV-VIS, and propose a new method, TROY-VIS, that significantly improves processing speed while maintaining high accuracy. We introduce three key techniques: (1) Decoupled Attention Feature Enhancer to speed up information interaction between different modalities and scales; (2) Flash Embedding Memory for obtaining fast text embeddings of object categories; and, (3) Kernel Interpolation for exploiting the temporal continuity in videos. Our experiments demonstrate that TROY-VIS achieves the best trade-off between accuracy and speed on two large-scale OV-VIS benchmarks, BURST and LV-VIS, running 20x faster than GLEE-Lite (25 FPS v.s. 1.25 FPS) with comparable or even better accuracy. These results demonstrate TROY-VIS's potential for real-time applications in dynamic environments such as mobile robotics and augmented reality. Code and model will be released at https://github.com/google-research/troyvis.
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Mar 14, 2024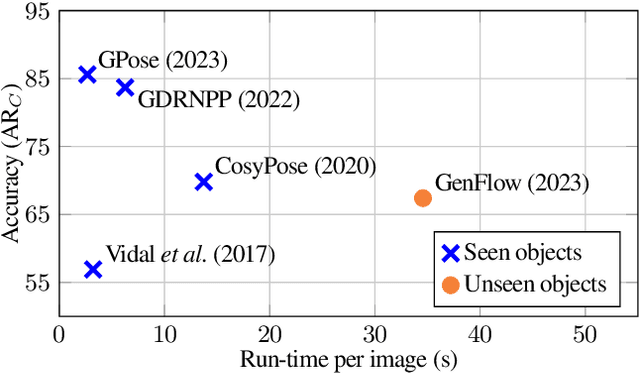


We present the evaluation methodology, datasets and results of the BOP Challenge 2023, the fifth in a series of public competitions organized to capture the state of the art in model-based 6D object pose estimation from an RGB/RGB-D image and related tasks. Besides the three tasks from 2022 (model-based 2D detection, 2D segmentation, and 6D localization of objects seen during training), the 2023 challenge introduced new variants of these tasks focused on objects unseen during training. In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models. The best 2023 method for 6D localization of unseen objects (GenFlow) notably reached the accuracy of the best 2020 method for seen objects (CosyPose), although being noticeably slower. The best 2023 method for seen objects (GPose) achieved a moderate accuracy improvement but a significant 43% run-time improvement compared to the best 2022 counterpart (GDRNPP). Since 2017, the accuracy of 6D localization of seen objects has improved by more than 50% (from 56.9 to 85.6 AR_C). The online evaluation system stays open and is available at: http://bop.felk.cvut.cz/.
HiPose: Hierarchical Binary Surface Encoding and Correspondence Pruning for RGB-D 6DoF Object Pose Estimation
Nov 21, 2023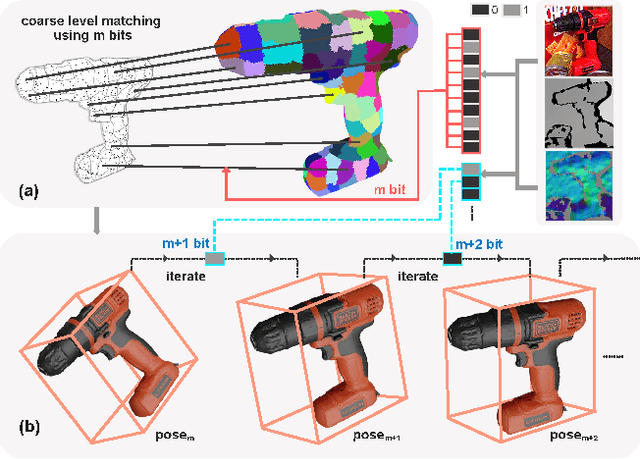

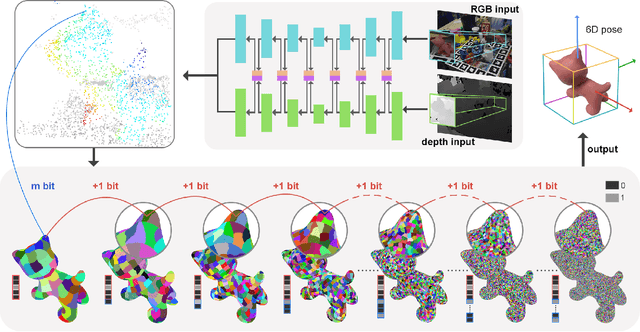
In this work, we present a novel dense-correspondence method for 6DoF object pose estimation from a single RGB-D image. While many existing data-driven methods achieve impressive performance, they tend to be time-consuming due to their reliance on rendering-based refinement approaches. To circumvent this limitation, we present HiPose, which establishes 3D-3D correspondences in a coarse-to-fine manner with a hierarchical binary surface encoding. Unlike previous dense-correspondence methods, we estimate the correspondence surface by employing point-to-surface matching and iteratively constricting the surface until it becomes a correspondence point while gradually removing outliers. Extensive experiments on public benchmarks LM-O, YCB-V, and T-Less demonstrate that our method surpasses all refinement-free methods and is even on par with expensive refinement-based approaches. Crucially, our approach is computationally efficient and enables real-time critical applications with high accuracy requirements. Code and models will be released.
6D Object Pose Estimation from Approximate 3D Models for Orbital Robotics
Mar 31, 2023



We present a novel technique to estimate the 6D pose of objects from single images where the 3D geometry of the object is only given approximately and not as a precise 3D model. To achieve this, we employ a dense 2D-to-3D correspondence predictor that regresses 3D model coordinates for every pixel. In addition to the 3D coordinates, our model also estimates the pixel-wise coordinate error to discard correspondences that are likely wrong. This allows us to generate multiple 6D pose hypotheses of the object, which we then refine iteratively using a highly efficient region-based approach. We also introduce a novel pixel-wise posterior formulation by which we can estimate the probability for each hypothesis and select the most likely one. As we show in experiments, our approach is capable of dealing with extreme visual conditions including overexposure, high contrast, or low signal-to-noise ratio. This makes it a powerful technique for the particularly challenging task of estimating the pose of tumbling satellites for in-orbit robotic applications. Our method achieves state-of-the-art performance on the SPEED+ dataset and has won the SPEC2021 post-mortem competition.
BOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.
A Multi-body Tracking Framework -- From Rigid Objects to Kinematic Structures
Aug 02, 2022
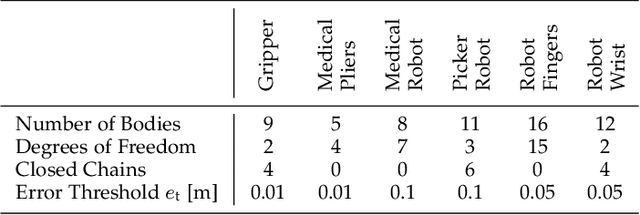
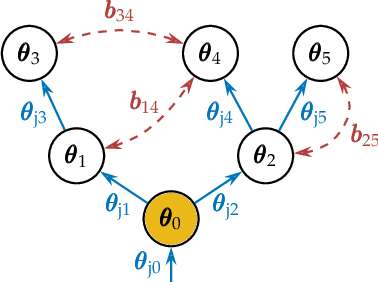
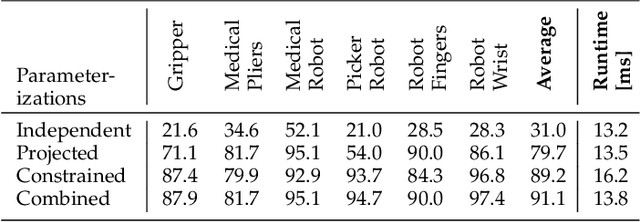
Kinematic structures are very common in the real world. They range from simple articulated objects to complex mechanical systems. However, despite their relevance, most model-based 3D tracking methods only consider rigid objects. To overcome this limitation, we propose a flexible framework that allows the extension of existing 6DoF algorithms to kinematic structures. Our approach focuses on methods that employ Newton-like optimization techniques, which are widely used in object tracking. The framework considers both tree-like and closed kinematic structures and allows a flexible configuration of joints and constraints. To project equations from individual rigid bodies to a multi-body system, Jacobians are used. For closed kinematic chains, a novel formulation that features Lagrange multipliers is developed. In a detailed mathematical proof, we show that our constraint formulation leads to an exact kinematic solution and converges in a single iteration. Based on the proposed framework, we extend ICG, which is a state-of-the-art rigid object tracking algorithm, to multi-body tracking. For the evaluation, we create a highly-realistic synthetic dataset that features a large number of sequences and various robots. Based on this dataset, we conduct a wide variety of experiments that demonstrate the excellent performance of the developed framework and our multi-body tracker.
Iterative Corresponding Geometry: Fusing Region and Depth for Highly Efficient 3D Tracking of Textureless Objects
Mar 10, 2022
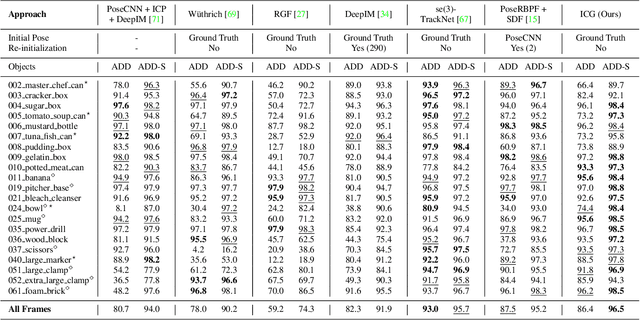
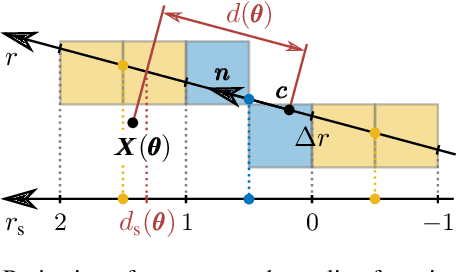
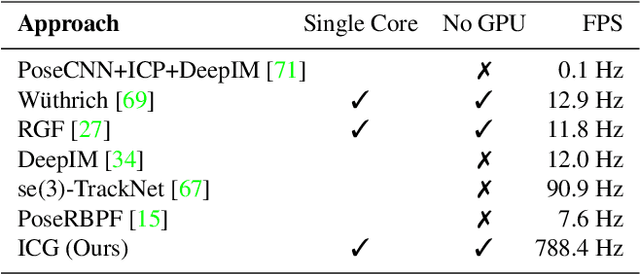
Tracking objects in 3D space and predicting their 6DoF pose is an essential task in computer vision. State-of-the-art approaches often rely on object texture to tackle this problem. However, while they achieve impressive results, many objects do not contain sufficient texture, violating the main underlying assumption. In the following, we thus propose ICG, a novel probabilistic tracker that fuses region and depth information and only requires the object geometry. Our method deploys correspondence lines and points to iteratively refine the pose. We also implement robust occlusion handling to improve performance in real-world settings. Experiments on the YCB-Video, OPT, and Choi datasets demonstrate that, even for textured objects, our approach outperforms the current state of the art with respect to accuracy and robustness. At the same time, ICG shows fast convergence and outstanding efficiency, requiring only 1.3 ms per frame on a single CPU core. Finally, we analyze the influence of individual components and discuss our performance compared to deep learning-based methods. The source code of our tracker is publicly available.
Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes
Mar 25, 2021
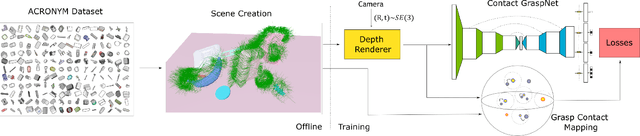
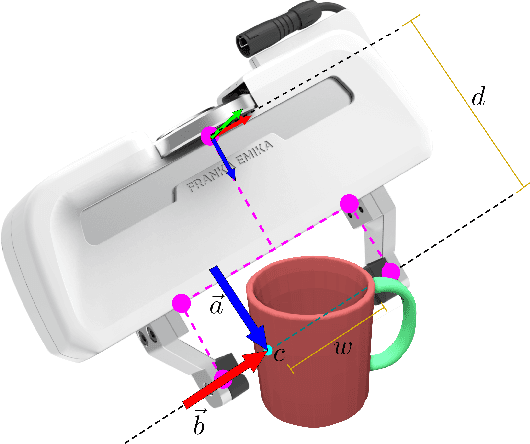
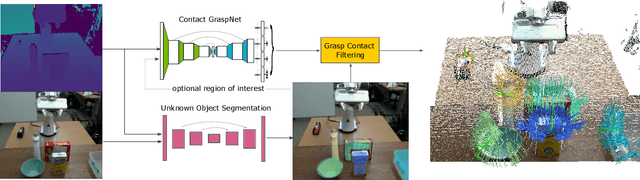
Grasping unseen objects in unconstrained, cluttered environments is an essential skill for autonomous robotic manipulation. Despite recent progress in full 6-DoF grasp learning, existing approaches often consist of complex sequential pipelines that possess several potential failure points and run-times unsuitable for closed-loop grasping. Therefore, we propose an end-to-end network that efficiently generates a distribution of 6-DoF parallel-jaw grasps directly from a depth recording of a scene. Our novel grasp representation treats 3D points of the recorded point cloud as potential grasp contacts. By rooting the full 6-DoF grasp pose and width in the observed point cloud, we can reduce the dimensionality of our grasp representation to 4-DoF which greatly facilitates the learning process. Our class-agnostic approach is trained on 17 million simulated grasps and generalizes well to real world sensor data. In a robotic grasping study of unseen objects in structured clutter we achieve over 90% success rate, cutting the failure rate in half compared to a recent state-of-the-art method.