 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Mar 14, 2024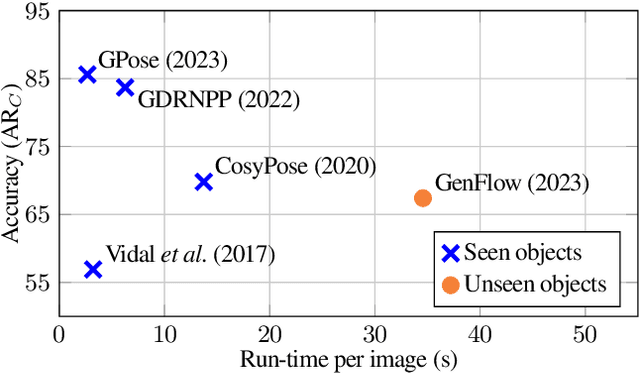


We present the evaluation methodology, datasets and results of the BOP Challenge 2023, the fifth in a series of public competitions organized to capture the state of the art in model-based 6D object pose estimation from an RGB/RGB-D image and related tasks. Besides the three tasks from 2022 (model-based 2D detection, 2D segmentation, and 6D localization of objects seen during training), the 2023 challenge introduced new variants of these tasks focused on objects unseen during training. In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models. The best 2023 method for 6D localization of unseen objects (GenFlow) notably reached the accuracy of the best 2020 method for seen objects (CosyPose), although being noticeably slower. The best 2023 method for seen objects (GPose) achieved a moderate accuracy improvement but a significant 43% run-time improvement compared to the best 2022 counterpart (GDRNPP). Since 2017, the accuracy of 6D localization of seen objects has improved by more than 50% (from 56.9 to 85.6 AR_C). The online evaluation system stays open and is available at: http://bop.felk.cvut.cz/.
BOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.
A Hybrid Approach for 6DoF Pose Estimation
Nov 11, 2020



We propose a method for 6DoF pose estimation of rigid objects that uses a state-of-the-art deep learning based instance detector to segment object instances in an RGB image, followed by a point-pair based voting method to recover the object's pose. We additionally use an automatic method selection that chooses the instance detector and the training set as that with the highest performance on the validation set. This hybrid approach leverages the best of learning and classic approaches, using CNNs to filter highly unstructured data and cut through the clutter, and a local geometric approach with proven convergence for robust pose estimation. The method is evaluated on the BOP core datasets where it significantly exceeds the baseline method and is the best fast method in the BOP 2020 Challenge.
BOP Challenge 2020 on 6D Object Localization
Oct 13, 2020

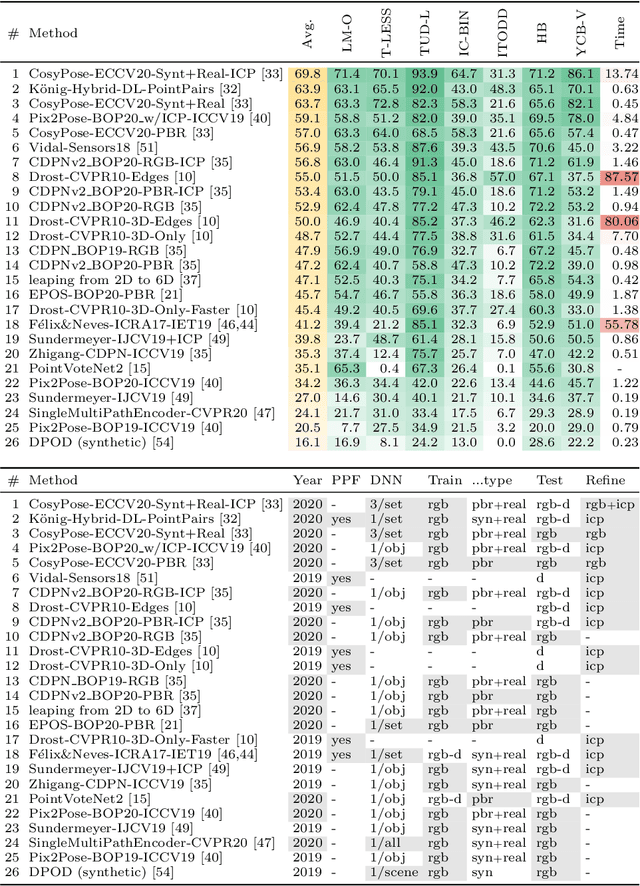
This paper presents the evaluation methodology, datasets, and results of the BOP Challenge 2020, the third in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB-D image. In 2020, to reduce the domain gap between synthetic training and real test RGB images, the participants were provided 350K photorealistic training images generated by BlenderProc4BOP, a new open-source and light-weight physically-based renderer (PBR) and procedural data generator. Methods based on deep neural networks have finally caught up with methods based on point pair features, which were dominating previous editions of the challenge. Although the top-performing methods rely on RGB-D image channels, strong results were achieved when only RGB channels were used at both training and test time - out of the 26 evaluated methods, the third method was trained on RGB channels of PBR and real images, while the fifth on RGB channels of PBR images only. Strong data augmentation was identified as a key component of the top-performing CosyPose method, and the photorealism of PBR images was demonstrated effective despite the augmentation. The online evaluation system stays open and is available on the project website: bop.felk.cvut.cz.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
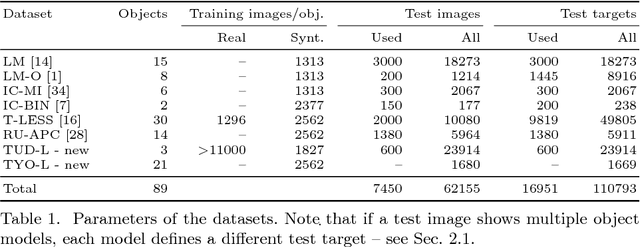

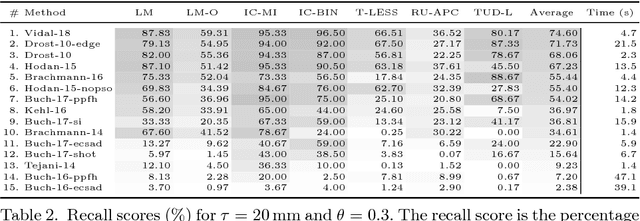
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
Acquire, Augment, Segment & Enjoy: Weakly Supervised Instance Segmentation of Supermarket Products
Jul 06, 2018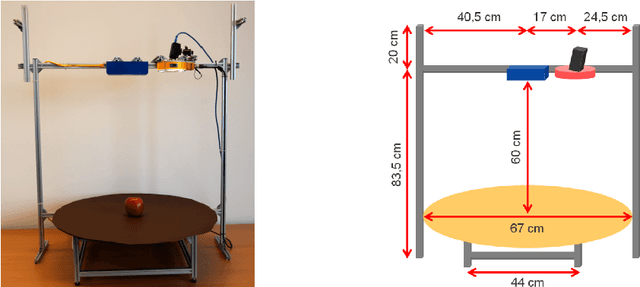
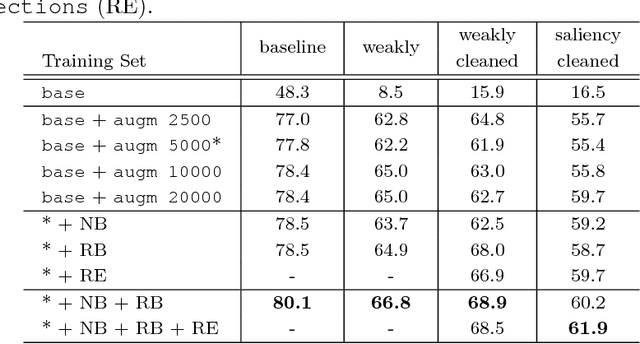
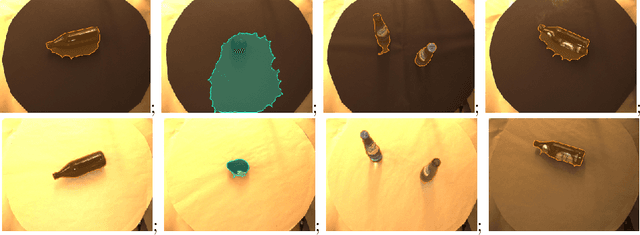

Grocery stores have thousands of products that are usually identified using barcodes with a human in the loop. For automated checkout systems, it is necessary to count and classify the groceries efficiently and robustly. One possibility is to use a deep learning algorithm for instance-aware semantic segmentation. Such methods achieve high accuracies but require a large amount of annotated training data. We propose a system to generate the training annotations in a weakly supervised manner, drastically reducing the labeling effort. We assume that for each training image, only the object class is known. The system automatically segments the corresponding object from the background. The obtained training data is augmented to simulate variations similar to those seen in real-world setups.