 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKi-Pode: Keypoint-based Implicit Pose Distribution Estimation of Rigid Objects
Sep 20, 2022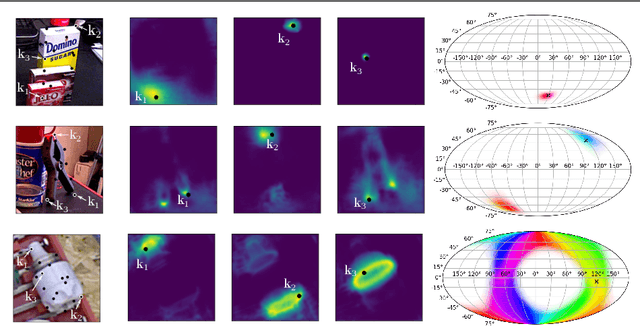
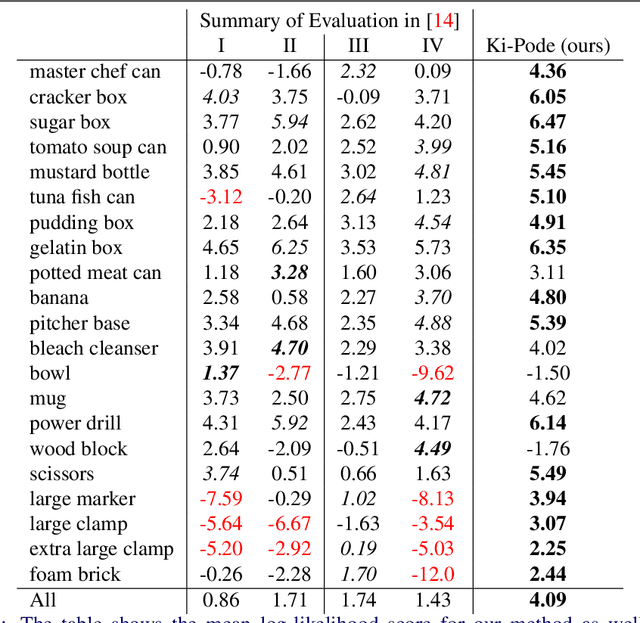


The estimation of 6D poses of rigid objects is a fundamental problem in computer vision. Traditionally pose estimation is concerned with the determination of a single best estimate. However, a single estimate is unable to express visual ambiguity, which in many cases is unavoidable due to object symmetries or occlusion of identifying features. Inability to account for ambiguities in pose can lead to failure in subsequent methods, which is unacceptable when the cost of failure is high. Estimates of full pose distributions are, contrary to single estimates, well suited for expressing uncertainty on pose. Motivated by this, we propose a novel pose distribution estimation method. An implicit formulation of the probability distribution over object pose is derived from an intermediary representation of an object as a set of keypoints. This ensures that the pose distribution estimates have a high level of interpretability. Furthermore, our method is based on conservative approximations, which leads to reliable estimates. The method has been evaluated on the task of rotation distribution estimation on the YCB-V and T-LESS datasets and performs reliably on all objects.
Self-supervised deep visual servoing for high precision peg-in-hole insertion
Jun 17, 2022



Many industrial assembly tasks involve peg-in-hole like insertions with sub-millimeter tolerances which are challenging, even in highly calibrated robot cells. Visual servoing can be employed to increase the robustness towards uncertainties in the system, however, state of the art methods either rely on accurate 3D models for synthetic renderings or manual involvement in acquisition of training data. We present a novel self-supervised visual servoing method for high precision peg-in-hole insertion, which is fully automated and does not rely on synthetic data. We demonstrate its applicability for insertion of electronic components into a printed circuit board with tight tolerances. We show that peg-in-hole insertion can be drastically sped up by preceding a robust but slow force-based insertion strategy with our proposed visual servoing method, the configuration of which is fully autonomous.
A Flexible and Robust Vision Trap for Automated Part Feeder Design
Jun 01, 2022



Fast, robust, and flexible part feeding is essential for enabling automation of low volume, high variance assembly tasks. An actuated vision-based solution on a traditional vibratory feeder, referred to here as a vision trap, should in principle be able to meet these demands for a wide range of parts. However, in practice, the flexibility of such a trap is limited as an expert is needed to both identify manageable tasks and to configure the vision system. We propose a novel approach to vision trap design in which the identification of manageable tasks is automatic and the configuration of these tasks can be delegated to an automated feeder design system. We show that the trap's capabilities can be formalized in such a way that it integrates seamlessly into the ecosystem of automated feeder design. Our results on six canonical parts show great promise for autonomous configuration of feeder systems.
ParaPose: Parameter and Domain Randomization Optimization for Pose Estimation using Synthetic Data
Mar 02, 2022
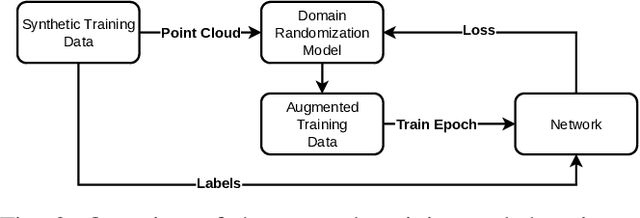
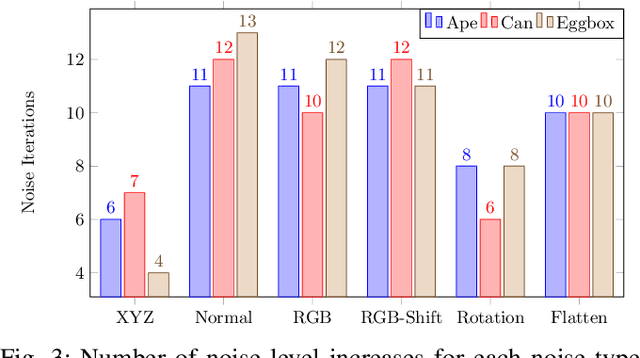
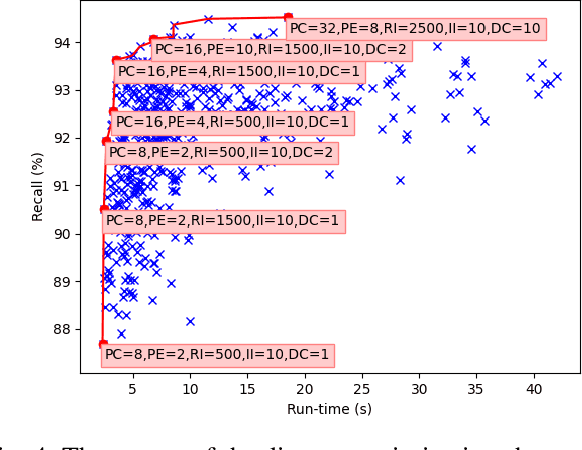
Pose estimation is the task of determining the 6D position of an object in a scene. Pose estimation aid the abilities and flexibility of robotic set-ups. However, the system must be configured towards the use case to perform adequately. This configuration is time-consuming and limits the usability of pose estimation and, thereby, robotic systems. Deep learning is a method to overcome this configuration procedure by learning parameters directly from the dataset. However, obtaining this training data can also be very time-consuming. The use of synthetic training data avoids this data collection problem, but a configuration of the training procedure is necessary to overcome the domain gap problem. Additionally, the pose estimation parameters also need to be configured. This configuration is jokingly known as grad student descent as parameters are manually adjusted until satisfactory results are obtained. This paper presents a method for automatic configuration using only synthetic data. This is accomplished by learning the domain randomization during network training, and then using the domain randomization to optimize the pose estimation parameters. The developed approach shows state-of-the-art performance of 82.0 % recall on the challenging OCCLUSION dataset, outperforming all previous methods with a large margin. These results prove the validity of automatic set-up of pose estimation using purely synthetic data.
SurfEmb: Dense and Continuous Correspondence Distributions for Object Pose Estimation with Learnt Surface Embeddings
Nov 26, 2021



We present an approach to learn dense, continuous 2D-3D correspondence distributions over the surface of objects from data with no prior knowledge of visual ambiguities like symmetry. We also present a new method for 6D pose estimation of rigid objects using the learnt distributions to sample, score and refine pose hypotheses. The correspondence distributions are learnt with a contrastive loss, represented in object-specific latent spaces by an encoder-decoder query model and a small fully connected key model. Our method is unsupervised with respect to visual ambiguities, yet we show that the query- and key models learn to represent accurate multi-modal surface distributions. Our pose estimation method improves the state-of-the-art significantly on the comprehensive BOP Challenge, trained purely on synthetic data, even compared with methods trained on real data. The project site is at https://surfemb.github.io/ .
Bridging the Performance Gap Between Pose Estimation Networks Trained on Real And Synthetic Data Using Domain Randomization
Nov 17, 2020

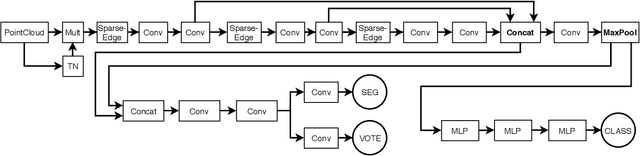
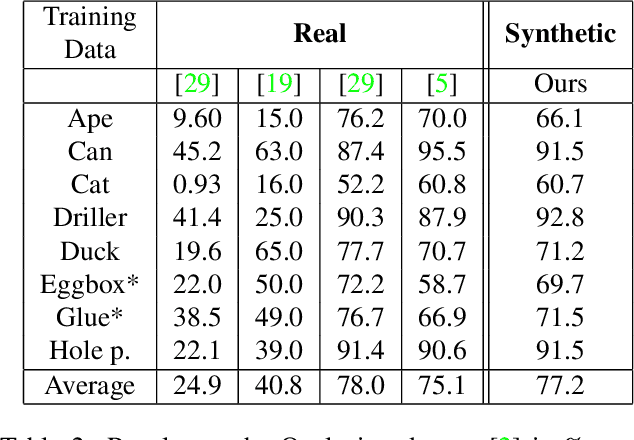
Since the introduction of deep learning methods, pose estimation performance has increased drastically. Usually, large amounts of manually annotated training data are required for these networks to perform. While training on synthetic data can avoid the manual annotation, this introduces another obstacle. There is currently a large performance gap between methods trained on real and synthetic data. This paper introduces a new method, which bridges the gap between real and synthetically trained networks. As opposed to other methods, the network utilizes 3D point clouds. This allows both for domain randomization in 3D and to use neighboring geometric information during inference. Experiments on three large pose estimation benchmarks show that the presented method outperforms previous methods trained on synthetic data and achieves comparable-and sometimes superior-results to existing methods trained on real data.
Fast robust peg-in-hole insertion with continuous visual servoing
Nov 12, 2020

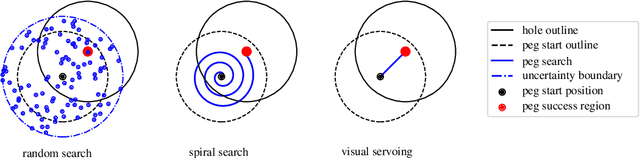

This paper demonstrates a visual servoing method which is robust towards uncertainties related to system calibration and grasping, while significantly reducing the peg-in-hole time compared to classical methods and recent attempts based on deep learning. The proposed visual servoing method is based on peg and hole point estimates from a deep neural network in a multi-cam setup, where the model is trained on purely synthetic data. Empirical results show that the learnt model generalizes to the real world, allowing for higher success rates and lower cycle times than existing approaches.
PointPoseNet: Accurate Object Detection and 6 DoF Pose Estimation in Point Clouds
Dec 19, 2019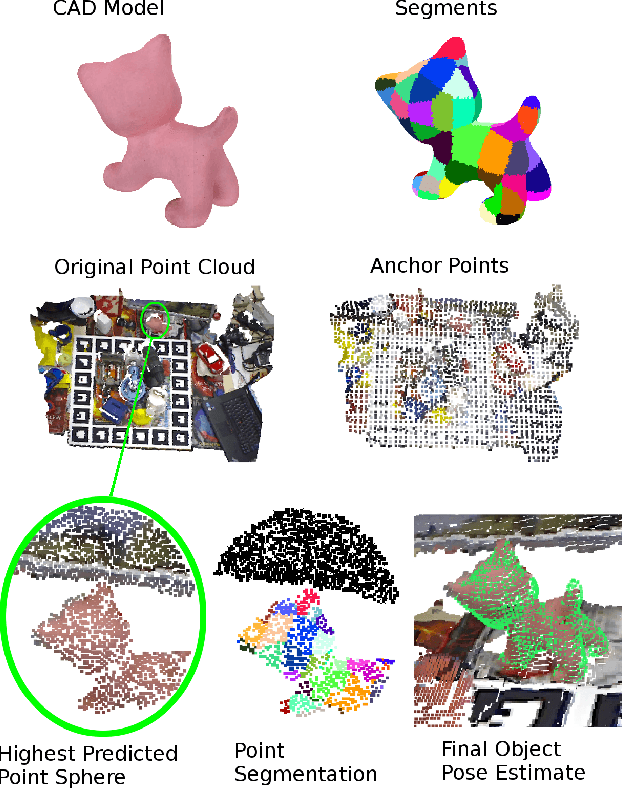
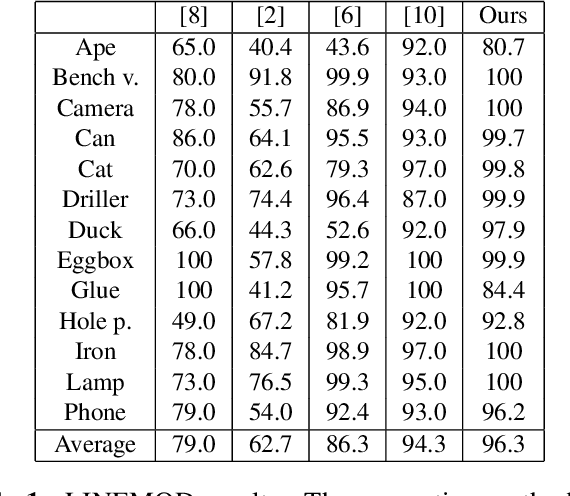
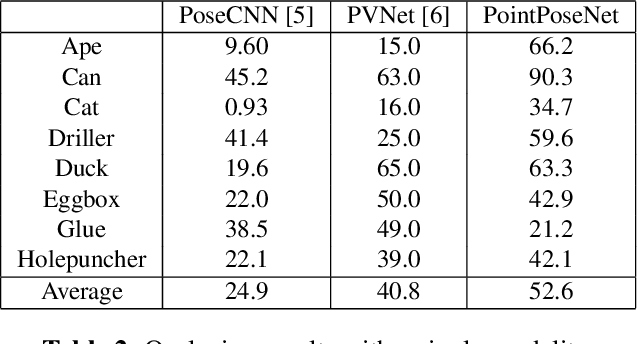
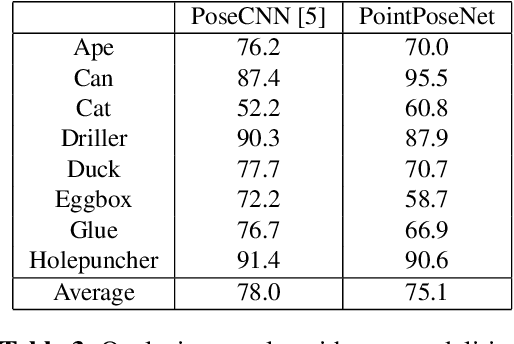
We present a learning-based method for 6 DoF pose estimation of rigid objects in point cloud data. Many recent learning-based approaches use primarily RGB information for detecting objects, in some cases with an added refinement step using depth data. Our method consumes unordered point sets with/without RGB information, from initial detection to the final transformation estimation stage. This allows us to achieve accurate pose estimates, in some cases surpassing state of the art methods trained on the same data.
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
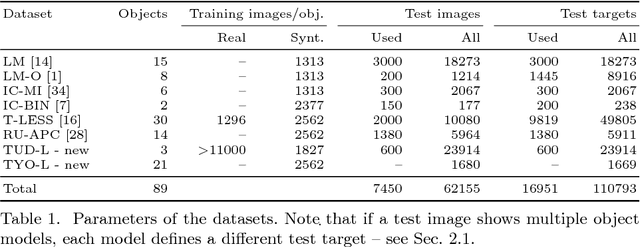

We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
Rotational Subgroup Voting and Pose Clustering for Robust 3D Object Recognition
Sep 07, 2017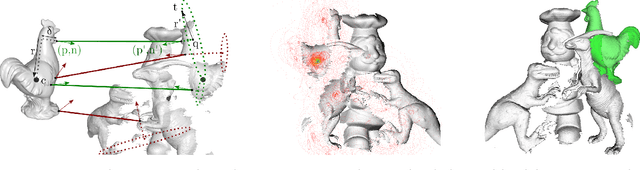
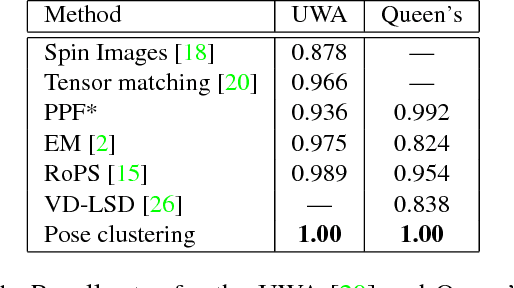
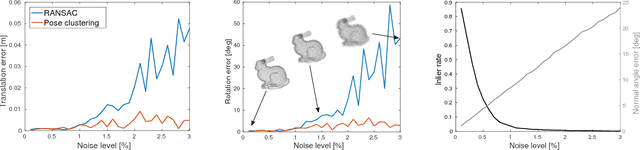
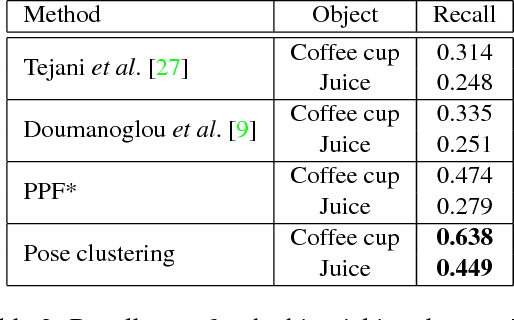
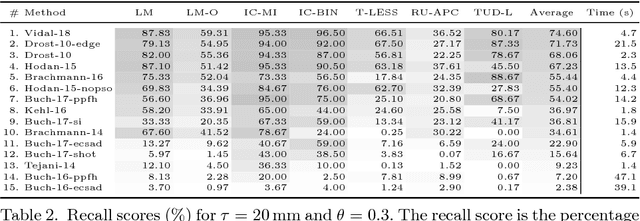
It is possible to associate a highly constrained subset of relative 6 DoF poses between two 3D shapes, as long as the local surface orientation, the normal vector, is available at every surface point. Local shape features can be used to find putative point correspondences between the models due to their ability to handle noisy and incomplete data. However, this correspondence set is usually contaminated by outliers in practical scenarios, which has led to many past contributions based on robust detectors such as the Hough transform or RANSAC. The key insight of our work is that a single correspondence between oriented points on the two models is constrained to cast votes in a 1 DoF rotational subgroup of the full group of poses, SE(3). Kernel density estimation allows combining the set of votes efficiently to determine a full 6 DoF candidate pose between the models. This modal pose with the highest density is stable under challenging conditions, such as noise, clutter, and occlusions, and provides the output estimate of our method. We first analyze the robustness of our method in relation to noise and show that it handles high outlier rates much better than RANSAC for the task of 6 DoF pose estimation. We then apply our method to four state of the art data sets for 3D object recognition that contain occluded and cluttered scenes. Our method achieves perfect recall on two LIDAR data sets and outperforms competing methods on two RGB-D data sets, thus setting a new standard for general 3D object recognition using point cloud data.
* Accepted for International Conference on Computer Vision (ICCV), 2017