 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Performance Gap Between Pose Estimation Networks Trained on Real And Synthetic Data Using Domain Randomization
Paper and Code
Nov 17, 2020

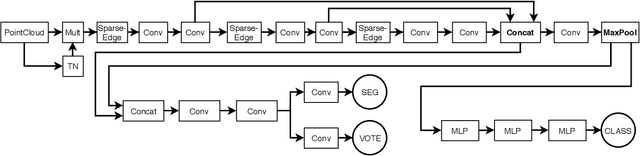
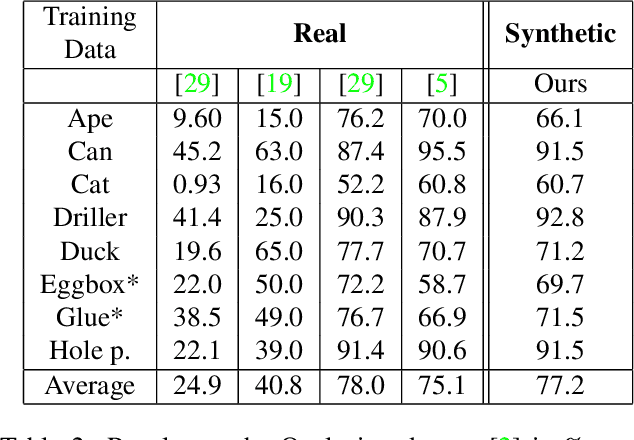
Since the introduction of deep learning methods, pose estimation performance has increased drastically. Usually, large amounts of manually annotated training data are required for these networks to perform. While training on synthetic data can avoid the manual annotation, this introduces another obstacle. There is currently a large performance gap between methods trained on real and synthetic data. This paper introduces a new method, which bridges the gap between real and synthetically trained networks. As opposed to other methods, the network utilizes 3D point clouds. This allows both for domain randomization in 3D and to use neighboring geometric information during inference. Experiments on three large pose estimation benchmarks show that the presented method outperforms previous methods trained on synthetic data and achieves comparable-and sometimes superior-results to existing methods trained on real data.