 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-the-shelf bin picking workcell with visual pose estimation: A case study on the world robot summit 2018 kitting task
Sep 28, 2023
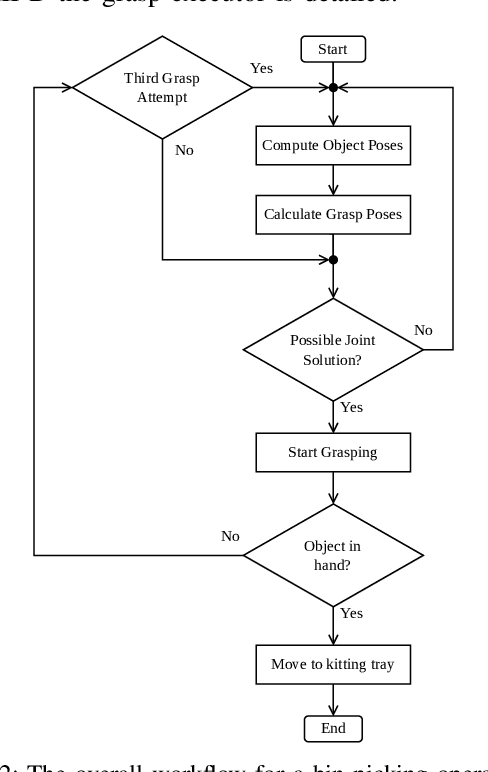
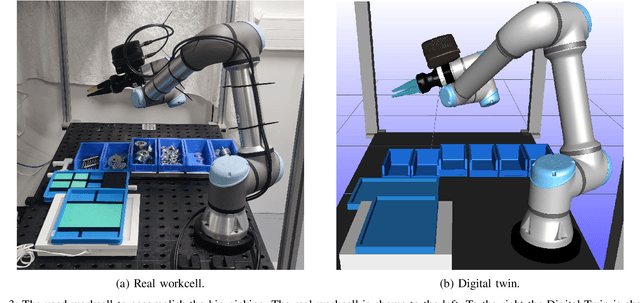

The World Robot Summit 2018 Assembly Challenge included four different tasks. The kitting task, which required bin-picking, was the task in which the fewest points were obtained. However, bin-picking is a vital skill that can significantly increase the flexibility of robotic set-ups, and is, therefore, an important research field. In recent years advancements have been made in sensor technology and pose estimation algorithms. These advancements allow for better performance when performing visual pose estimation. This paper shows that by utilizing new vision sensors and pose estimation algorithms pose estimation in bins can be performed successfully. We also implement a workcell for bin picking along with a force based grasping approach to perform the complete bin picking. Our set-up is tested on the World Robot Summit 2018 Assembly Challenge and successfully obtains a higher score compared with all teams at the competition. This demonstrate that current technology can perform bin-picking at a much higher level compared with previous results.
In-Hand Pose Estimation and Pin Inspection for Insertion of Through-Hole Components
Aug 02, 2022


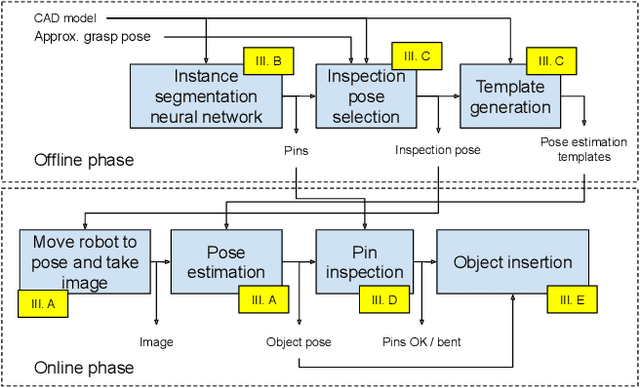
The insertion of through-hole components is a difficult task. As the tolerances of the holes are very small, minor errors in the insertion will result in failures. These failures can damage components and will require manual intervention for recovery. Errors can occur both from imprecise object grasps and bent pins. Therefore, it is important that a system can accurately determine the object's position and reject components with bent pins. By utilizing the constraints inherent in the object grasp a method using template matching is able to obtain very precise pose estimates. Methods for pin-checking are also implemented, compared, and a successful method is shown. The set-up is performed automatically, with two novel contributions. A deep learning segmentation of the pins is performed and the inspection pose is found by simulation. From the inspection pose and the segmented pins, the templates for pose estimation and pin check are then generated. To train the deep learning method a dataset of segmented through-hole components is created. The network shows a 97.3 % accuracy on the test set. The pin-segmentation network is also tested on the insertion CAD models and successfully segment the pins. The complete system is tested on three different objects, and experiments show that the system is able to insert all objects successfully. Both by correcting in-hand grasp errors and rejecting objects with bent pins.
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
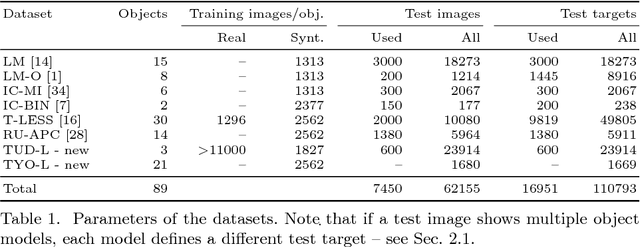

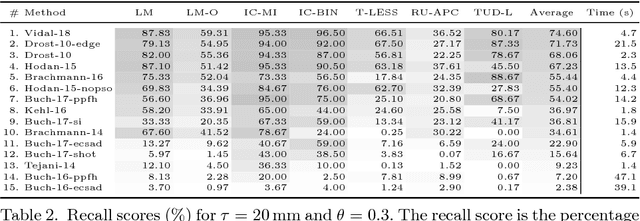
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
Rotational Subgroup Voting and Pose Clustering for Robust 3D Object Recognition
Sep 07, 2017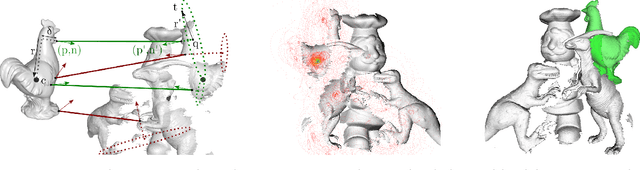
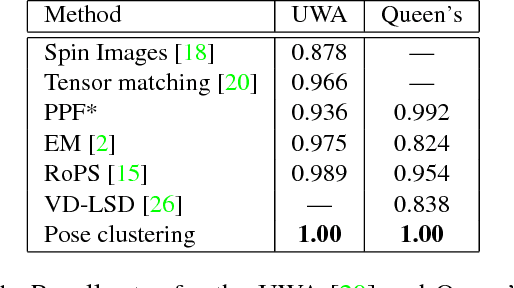
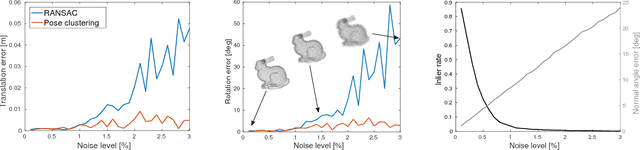
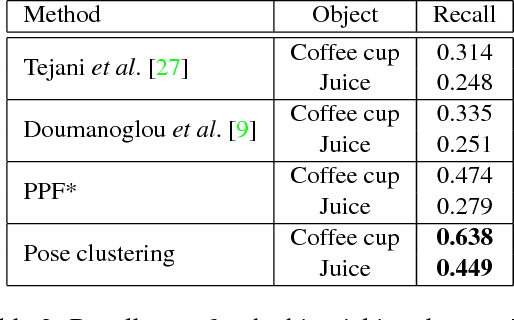
It is possible to associate a highly constrained subset of relative 6 DoF poses between two 3D shapes, as long as the local surface orientation, the normal vector, is available at every surface point. Local shape features can be used to find putative point correspondences between the models due to their ability to handle noisy and incomplete data. However, this correspondence set is usually contaminated by outliers in practical scenarios, which has led to many past contributions based on robust detectors such as the Hough transform or RANSAC. The key insight of our work is that a single correspondence between oriented points on the two models is constrained to cast votes in a 1 DoF rotational subgroup of the full group of poses, SE(3). Kernel density estimation allows combining the set of votes efficiently to determine a full 6 DoF candidate pose between the models. This modal pose with the highest density is stable under challenging conditions, such as noise, clutter, and occlusions, and provides the output estimate of our method. We first analyze the robustness of our method in relation to noise and show that it handles high outlier rates much better than RANSAC for the task of 6 DoF pose estimation. We then apply our method to four state of the art data sets for 3D object recognition that contain occluded and cluttered scenes. Our method achieves perfect recall on two LIDAR data sets and outperforms competing methods on two RGB-D data sets, thus setting a new standard for general 3D object recognition using point cloud data.
* Accepted for International Conference on Computer Vision (ICCV), 2017
Pose Estimation using Local Structure-Specific Shape and Appearance Context
Aug 23, 2017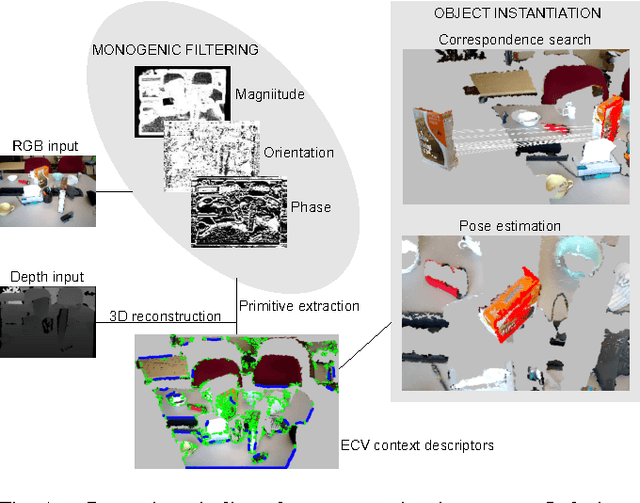

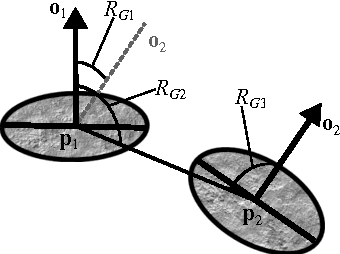
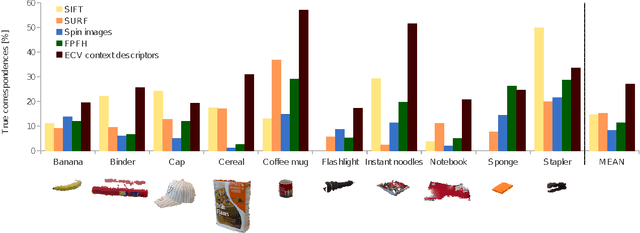
We address the problem of estimating the alignment pose between two models using structure-specific local descriptors. Our descriptors are generated using a combination of 2D image data and 3D contextual shape data, resulting in a set of semi-local descriptors containing rich appearance and shape information for both edge and texture structures. This is achieved by defining feature space relations which describe the neighborhood of a descriptor. By quantitative evaluations, we show that our descriptors provide high discriminative power compared to state of the art approaches. In addition, we show how to utilize this for the estimation of the alignment pose between two point sets. We present experiments both in controlled and real-life scenarios to validate our approach.
Towards Declarative Safety Rules for Perception Specification Architectures
Jan 12, 2016


Agriculture has a high number of fatalities compared to other blue collar fields, additionally population decreasing in rural areas is resulting in decreased work force. These issues have resulted in increased focus on improving efficiency of and introducing autonomy in agriculture. Field robots are an increasingly promising branch of robotics targeted at full automation in agriculture. The safety aspect however is rely addressed in connection with safety standards, which limits the real-world applicability. In this paper we present an analysis of a vision pipeline in connection with functional-safety standards, in order to propose solutions for how to ascertain that the system operates as required. Based on the analysis we demonstrate a simple mechanism for verifying that a vision pipeline is functioning correctly, thus improving the safety in the overall system.
Towards Error Handling in a DSL for Robot Assembly Tasks
Dec 15, 2014This work-in-progress paper presents our work with a domain specific language (DSL) for tackling the issue of programming robots for small-sized batch production. We observe that as the complexity of assembly increases so does the likelihood of errors, and these errors need to be addressed. Nevertheless, it is essential that programming and setting up the assembly remains fast, allows quick changeovers, easy adjustments and reconfigurations. In this paper we present an initial design and implementation of extending an existing DSL for assembly operations with error specification, error handling and advanced move commands incorporating error tolerance. The DSL is used as part of a framework that aims at tackling uncertainties through a probabilistic approach.