 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaSeNet: A Learning-based Mobile Manipulator Base Pose Sequence Planning for Pickup Tasks
Jun 12, 2024



In many applications, a mobile manipulator robot is required to grasp a set of objects distributed in space. This may not be feasible from a single base pose and the robot must plan the sequence of base poses for grasping all objects, minimizing the total navigation and grasping time. This is a Combinatorial Optimization problem that can be solved using exact methods, which provide optimal solutions but are computationally expensive, or approximate methods, which offer computationally efficient but sub-optimal solutions. Recent studies have shown that learning-based methods can solve Combinatorial Optimization problems, providing near-optimal and computationally efficient solutions. In this work, we present BASENET - a learning-based approach to plan the sequence of base poses for the robot to grasp all the objects in the scene. We propose a Reinforcement Learning based solution that learns the base poses for grasping individual objects and the sequence in which the objects should be grasped to minimize the total navigation and grasping costs using Layered Learning. As the problem has a varying number of states and actions, we represent states and actions as a graph and use Graph Neural Networks for learning. We show that the proposed method can produce comparable solutions to exact and approximate methods with significantly less computation time.
Robotic Task Success Evaluation Under Multi-modal Non-Parametric Object Pose Uncertainty
Mar 16, 2024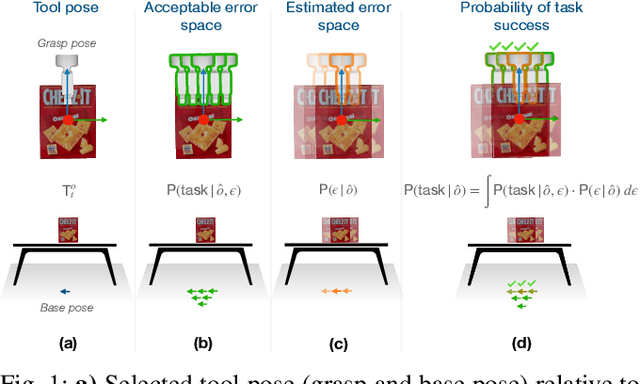
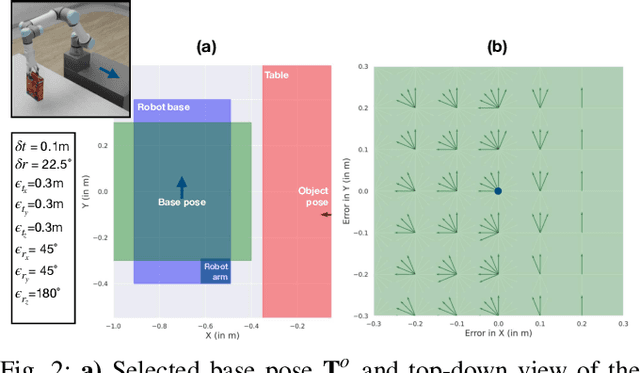
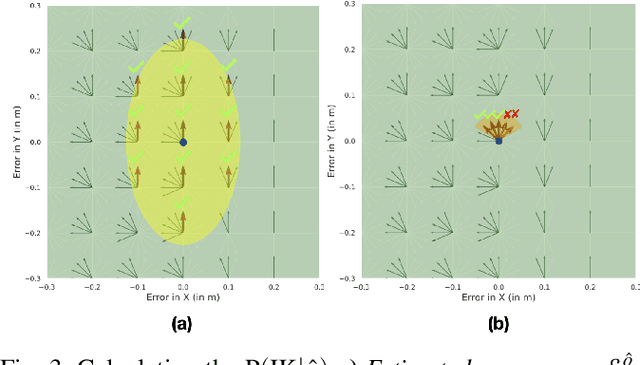

Accurate 6D object pose estimation is essential for various robotic tasks. Uncertain pose estimates can lead to task failures; however, a certain degree of error in the pose estimates is often acceptable. Hence, by quantifying errors in the object pose estimate and acceptable errors for task success, robots can make informed decisions. This is a challenging problem as both the object pose uncertainty and acceptable error for the robotic task are often multi-modal and cannot be parameterized with commonly used uni-modal distributions. In this paper, we introduce a framework for evaluating robotic task success under object pose uncertainty, representing both the estimated error space of the object pose and the acceptable error space for task success using multi-modal non-parametric probability distributions. The proposed framework pre-computes the acceptable error space for task success using dynamic simulations and subsequently integrates the pre-computed acceptable error space over the estimated error space of the object pose to predict the likelihood of the task success. We evaluated the proposed framework on two mobile manipulation tasks. Our results show that by representing the estimated and the acceptable error space using multi-modal non-parametric distributions, we achieve higher task success rates and fewer failures.
In search of inliers: 3d correspondence by local and global voting
Aug 23, 2017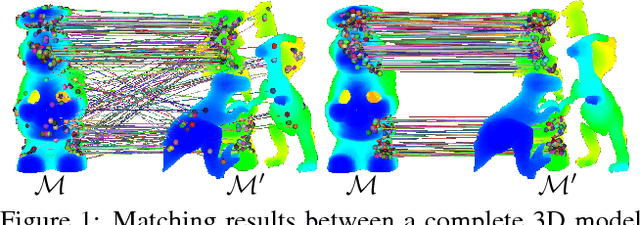
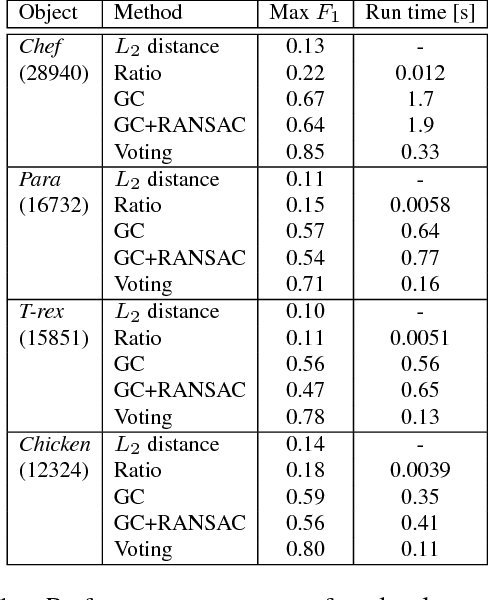
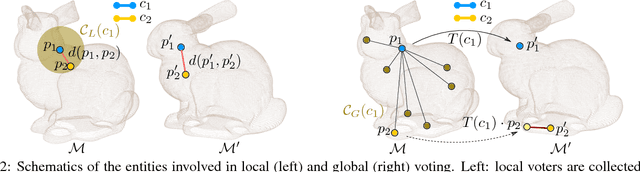
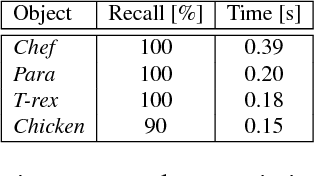
We present a method for finding correspondence between 3D models. From an initial set of feature correspondences, our method uses a fast voting scheme to separate the inliers from the outliers. The novelty of our method lies in the use of a combination of local and global constraints to determine if a vote should be cast. On a local scale, we use simple, low-level geometric invariants. On a global scale, we apply covariant constraints for finding compatible correspondences. We guide the sampling for collecting voters by downward dependencies on previous voting stages. All of this together results in an accurate matching procedure. We evaluate our algorithm by controlled and comparative testing on different datasets, giving superior performance compared to state of the art methods. In a final experiment, we apply our method for 3D object detection, showing potential use of our method within higher-level vision.
Pose Estimation using Local Structure-Specific Shape and Appearance Context
Aug 23, 2017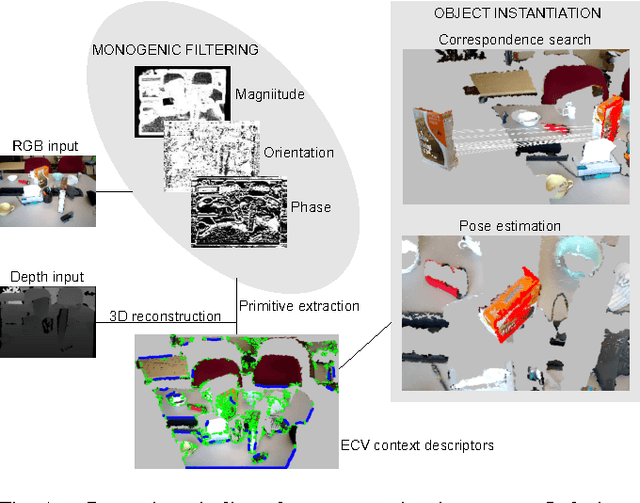

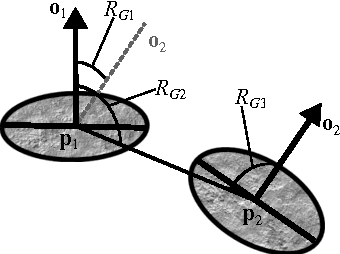
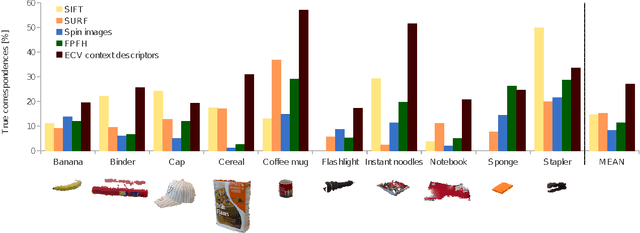
We address the problem of estimating the alignment pose between two models using structure-specific local descriptors. Our descriptors are generated using a combination of 2D image data and 3D contextual shape data, resulting in a set of semi-local descriptors containing rich appearance and shape information for both edge and texture structures. This is achieved by defining feature space relations which describe the neighborhood of a descriptor. By quantitative evaluations, we show that our descriptors provide high discriminative power compared to state of the art approaches. In addition, we show how to utilize this for the estimation of the alignment pose between two point sets. We present experiments both in controlled and real-life scenarios to validate our approach.