 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
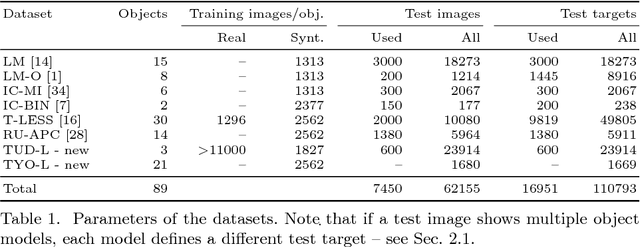

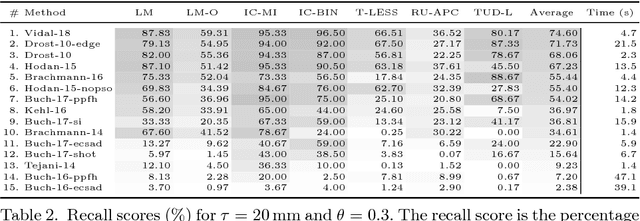
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-less Objects
Jan 19, 2017
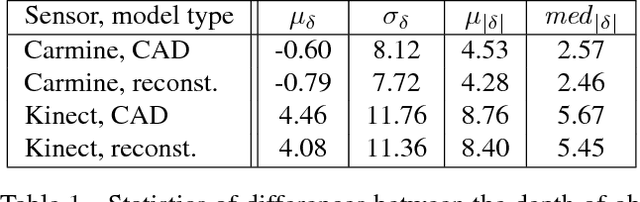


We introduce T-LESS, a new public dataset for estimating the 6D pose, i.e. translation and rotation, of texture-less rigid objects. The dataset features thirty industry-relevant objects with no significant texture and no discriminative color or reflectance properties. The objects exhibit symmetries and mutual similarities in shape and/or size. Compared to other datasets, a unique property is that some of the objects are parts of others. The dataset includes training and test images that were captured with three synchronized sensors, specifically a structured-light and a time-of-flight RGB-D sensor and a high-resolution RGB camera. There are approximately 39K training and 10K test images from each sensor. Additionally, two types of 3D models are provided for each object, i.e. a manually created CAD model and a semi-automatically reconstructed one. Training images depict individual objects against a black background. Test images originate from twenty test scenes having varying complexity, which increases from simple scenes with several isolated objects to very challenging ones with multiple instances of several objects and with a high amount of clutter and occlusion. The images were captured from a systematically sampled view sphere around the object/scene, and are annotated with accurate ground truth 6D poses of all modeled objects. Initial evaluation results indicate that the state of the art in 6D object pose estimation has ample room for improvement, especially in difficult cases with significant occlusion. The T-LESS dataset is available online at cmp.felk.cvut.cz/t-less.