 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
GenFlow: Generalizable Recurrent Flow for 6D Pose Refinement of Novel Objects
Mar 18, 2024Despite the progress of learning-based methods for 6D object pose estimation, the trade-off between accuracy and scalability for novel objects still exists. Specifically, previous methods for novel objects do not make good use of the target object's 3D shape information since they focus on generalization by processing the shape indirectly, making them less effective. We present GenFlow, an approach that enables both accuracy and generalization to novel objects with the guidance of the target object's shape. Our method predicts optical flow between the rendered image and the observed image and refines the 6D pose iteratively. It boosts the performance by a constraint of the 3D shape and the generalizable geometric knowledge learned from an end-to-end differentiable system. We further improve our model by designing a cascade network architecture to exploit the multi-scale correlations and coarse-to-fine refinement. GenFlow ranked first on the unseen object pose estimation benchmarks in both the RGB and RGB-D cases. It also achieves performance competitive with existing state-of-the-art methods for the seen object pose estimation without any fine-tuning.
Tracking Human-like Natural Motion Using Deep Recurrent Neural Networks
Apr 15, 2016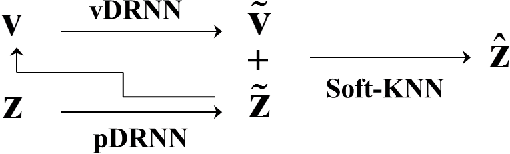
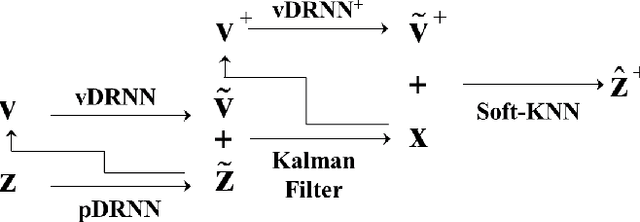

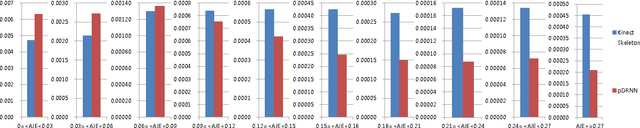
Kinect skeleton tracker is able to achieve considerable human body tracking performance in convenient and a low-cost manner. However, The tracker often captures unnatural human poses such as discontinuous and vibrated motions when self-occlusions occur. A majority of approaches tackle this problem by using multiple Kinect sensors in a workspace. Combination of the measurements from different sensors is then conducted in Kalman filter framework or optimization problem is formulated for sensor fusion. However, these methods usually require heuristics to measure reliability of measurements observed from each Kinect sensor. In this paper, we developed a method to improve Kinect skeleton using single Kinect sensor, in which supervised learning technique was employed to correct unnatural tracking motions. Specifically, deep recurrent neural networks were used for improving joint positions and velocities of Kinect skeleton, and three methods were proposed to integrate the refined positions and velocities for further enhancement. Moreover, we suggested a novel measure to evaluate naturalness of captured motions. We evaluated the proposed approach by comparison with the ground truth obtained using a commercial optical maker-based motion capture system.