 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatEXAONEPath: An Expert-level Multimodal Large Language Model for Histopathology Using Whole Slide Images
Apr 17, 2025Recent studies have made significant progress in developing large language models (LLMs) in the medical domain, which can answer expert-level questions and demonstrate the potential to assist clinicians in real-world clinical scenarios. Studies have also witnessed the importance of integrating various modalities with the existing LLMs for a better understanding of complex clinical contexts, which are innately multi-faceted by nature. Although studies have demonstrated the ability of multimodal LLMs in histopathology to answer questions from given images, they lack in understanding of thorough clinical context due to the patch-level data with limited information from public datasets. Thus, developing WSI-level MLLMs is significant in terms of the scalability and applicability of MLLMs in histopathology. In this study, we introduce an expert-level MLLM for histopathology using WSIs, dubbed as ChatEXAONEPath. We present a retrieval-based data generation pipeline using 10,094 pairs of WSIs and histopathology reports from The Cancer Genome Atlas (TCGA). We also showcase an AI-based evaluation protocol for a comprehensive understanding of the medical context from given multimodal information and evaluate generated answers compared to the original histopathology reports. We demonstrate the ability of diagnosing the given histopathology images using ChatEXAONEPath with the acceptance rate of 62.9% from 1,134 pairs of WSIs and reports. Our proposed model can understand pan-cancer WSIs and clinical context from various cancer types. We argue that our proposed model has the potential to assist clinicians by comprehensively understanding complex morphology of WSIs for cancer diagnosis through the integration of multiple modalities.
X2CT-CLIP: Enable Multi-Abnormality Detection in Computed Tomography from Chest Radiography via Tri-Modal Contrastive Learning
Mar 04, 2025

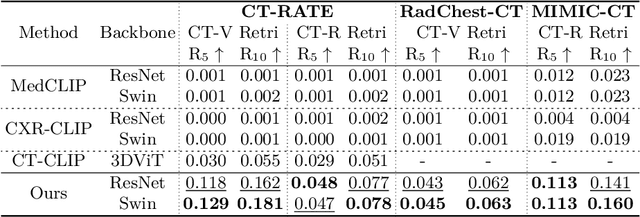

Computed tomography (CT) is a key imaging modality for diagnosis, yet its clinical utility is marred by high radiation exposure and long turnaround times, restricting its use for larger-scale screening. Although chest radiography (CXR) is more accessible and safer, existing CXR foundation models focus primarily on detecting diseases that are readily visible on the CXR. Recently, works have explored training disease classification models on simulated CXRs, but they remain limited to recognizing a single disease type from CT. CT foundation models have also emerged with significantly improved detection of pathologies in CT. However, the generalized application of CT-derived labels on CXR has remained illusive. In this study, we propose X2CT-CLIP, a tri-modal knowledge transfer learning framework that bridges the modality gap between CT and CXR while reducing the computational burden of model training. Our approach is the first work to enable multi-abnormality classification in CT, using CXR, by transferring knowledge from 3D CT volumes and associated radiology reports to a CXR encoder via a carefully designed tri-modal alignment mechanism in latent space. Extensive evaluations on three multi-label CT datasets demonstrate that our method outperforms state-of-the-art baselines in cross-modal retrieval, few-shot adaptation, and external validation. These results highlight the potential of CXR, enriched with knowledge derived from CT, as a viable efficient alternative for disease detection in resource-limited settings.
Multi-Task Learning for Integrated Automated Contouring and Voxel-Based Dose Prediction in Radiotherapy
Nov 27, 2024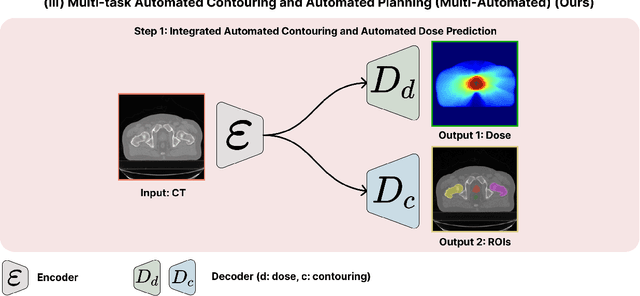
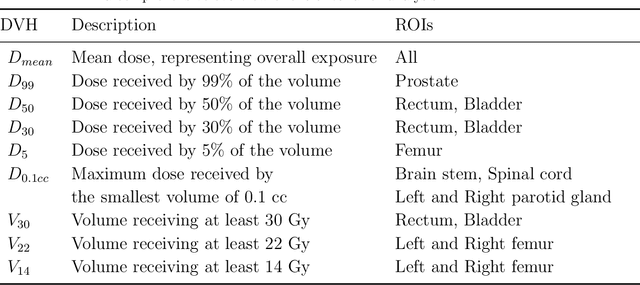
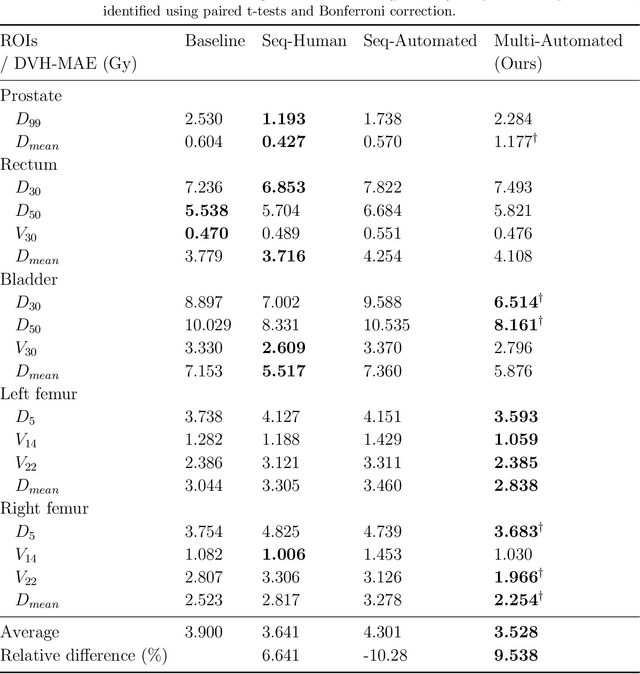
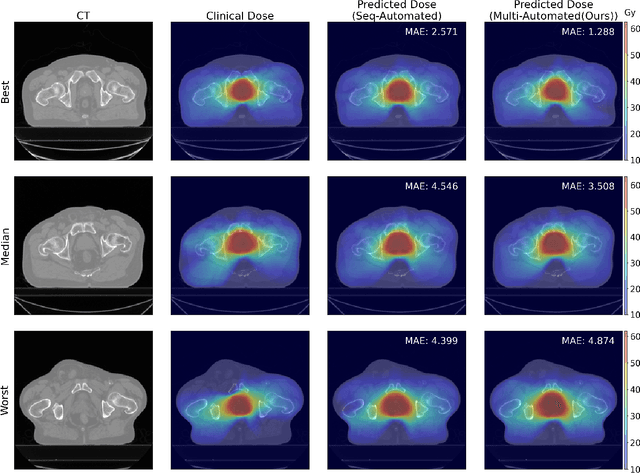
Deep learning-based automated contouring and treatment planning has been proven to improve the efficiency and accuracy of radiotherapy. However, conventional radiotherapy treatment planning process has the automated contouring and treatment planning as separate tasks. Moreover in deep learning (DL), the contouring and dose prediction tasks for automated treatment planning are done independently. In this study, we applied the multi-task learning (MTL) approach in order to seamlessly integrate automated contouring and voxel-based dose prediction tasks, as MTL can leverage common information between the two tasks and be able able to increase the efficiency of the automated tasks. We developed our MTL framework using the two datasets: in-house prostate cancer dataset and the publicly available head and neck cancer dataset, OpenKBP. Compared to the sequential DL contouring and treatment planning tasks, our proposed method using MTL improved the mean absolute difference of dose volume histogram metrics of prostate and head and neck sites by 19.82% and 16.33%, respectively. Our MTL model for automated contouring and dose prediction tasks demonstrated enhanced dose prediction performance while maintaining or sometimes even improving the contouring accuracy. Compared to the baseline automated contouring model with the dice score coefficients of 0.818 for prostate and 0.674 for head and neck datasets, our MTL approach achieved average scores of 0.824 and 0.716 for these datasets, respectively. Our study highlights the potential of the proposed automated contouring and planning using MTL to support the development of efficient and accurate automated treatment planning for radiotherapy.
MEDBind: Unifying Language and Multimodal Medical Data Embeddings
Mar 20, 2024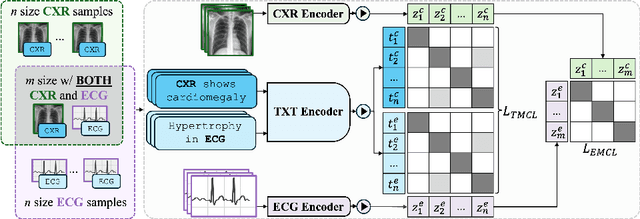

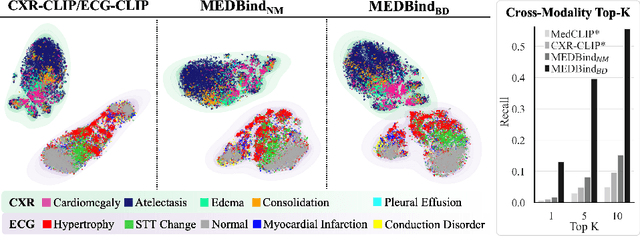
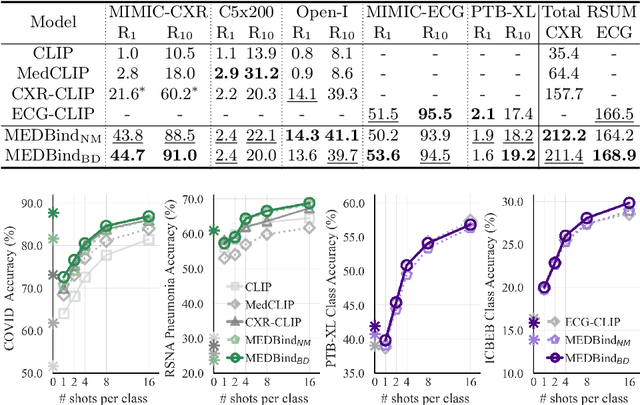
Medical vision-language pretraining models (VLPM) have achieved remarkable progress in fusing chest X-rays (CXR) with clinical texts, introducing image-text data binding approaches that enable zero-shot learning and downstream clinical tasks. However, the current landscape lacks the holistic integration of additional medical modalities, such as electrocardiograms (ECG). We present MEDBind (Medical Electronic patient recorD), which learns joint embeddings across CXR, ECG, and medical text. Using text data as the central anchor, MEDBind features tri-modality binding, delivering competitive performance in top-K retrieval, zero-shot, and few-shot benchmarks against established VLPM, and the ability for CXR-to-ECG zero-shot classification and retrieval. This seamless integration is achieved through combination of contrastive loss on modality-text pairs with our proposed contrastive loss function, Edge-Modality Contrastive Loss, fostering a cohesive embedding space for CXR, ECG, and text. Finally, we demonstrate that MEDBind can improve downstream tasks by directly integrating CXR and ECG embeddings into a large-language model for multimodal prompt tuning.
GenFlow: Generalizable Recurrent Flow for 6D Pose Refinement of Novel Objects
Mar 18, 2024Despite the progress of learning-based methods for 6D object pose estimation, the trade-off between accuracy and scalability for novel objects still exists. Specifically, previous methods for novel objects do not make good use of the target object's 3D shape information since they focus on generalization by processing the shape indirectly, making them less effective. We present GenFlow, an approach that enables both accuracy and generalization to novel objects with the guidance of the target object's shape. Our method predicts optical flow between the rendered image and the observed image and refines the 6D pose iteratively. It boosts the performance by a constraint of the 3D shape and the generalizable geometric knowledge learned from an end-to-end differentiable system. We further improve our model by designing a cascade network architecture to exploit the multi-scale correlations and coarse-to-fine refinement. GenFlow ranked first on the unseen object pose estimation benchmarks in both the RGB and RGB-D cases. It also achieves performance competitive with existing state-of-the-art methods for the seen object pose estimation without any fine-tuning.
Conversion of single-energy computed tomography to parametric maps of dual-energy computed tomography using convolutional neural network
Sep 26, 2023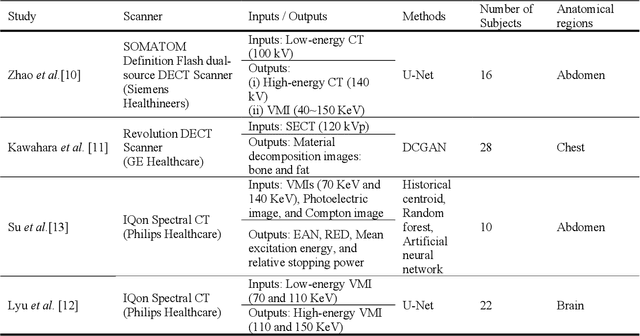
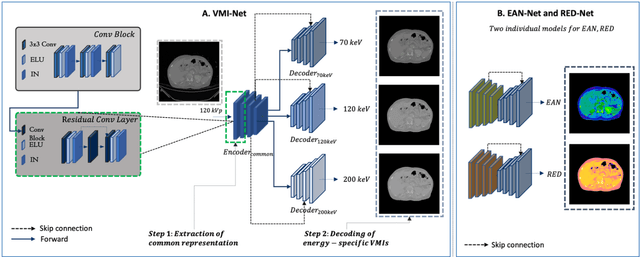

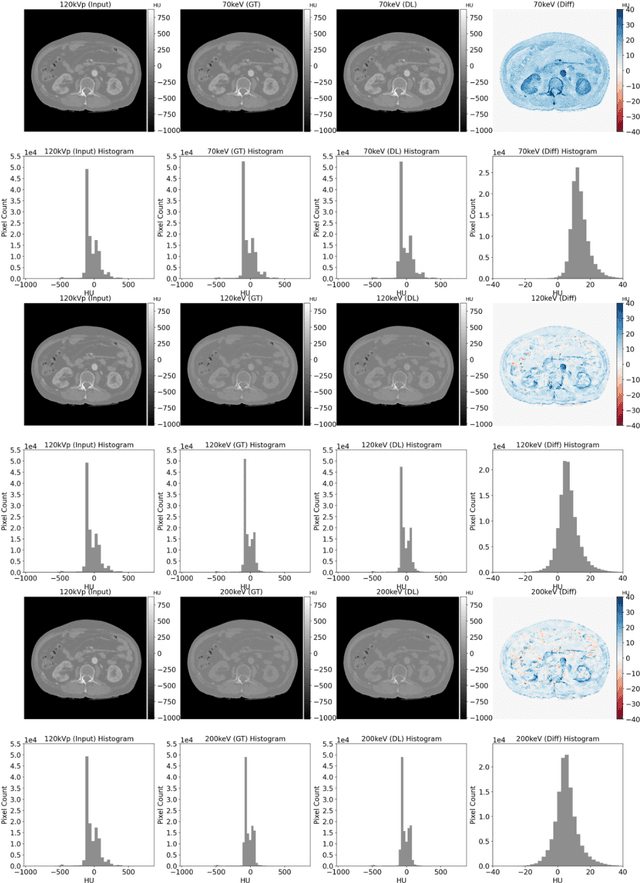
Objectives: We propose a deep learning (DL) multi-task learning framework using convolutional neural network (CNN) for a direct conversion of single-energy CT (SECT) to three different parametric maps of dual-energy CT (DECT): Virtual-monochromatic image (VMI), effective atomic number (EAN), and relative electron density (RED). Methods: We propose VMI-Net for conversion of SECT to 70, 120, and 200 keV VMIs. In addition, EAN-Net and RED-Net were also developed to convert SECT to EAN and RED. We trained and validated our model using 67 patients collected between 2019 and 2020. SECT images with 120 kVp acquired by the DECT (IQon spectral CT, Philips) were used as input, while the VMIs, EAN, and RED acquired by the same device were used as target. The performance of the DL framework was evaluated by absolute difference (AD) and relative difference (RD). Results: The VMI-Net converted 120 kVp SECT to the VMIs with AD of 9.02 Hounsfield Unit, and RD of 0.41% compared to the ground truth VMIs. The ADs of the converted EAN and RED were 0.29 and 0.96, respectively, while the RDs were 1.99% and 0.50% for the converted EAN and RED, respectively. Conclusions: SECT images were directly converted to the three parametric maps of DECT (i.e., VMIs, EAN, and RED). By using this model, one can generate the parametric information from SECT images without DECT device. Our model can help investigate the parametric information from SECT retrospectively. Advances in knowledge: Deep learning framework enables converting SECT to various high-quality parametric maps of DECT.
Cross-Task Attention Network: Improving Multi-Task Learning for Medical Imaging Applications
Sep 07, 2023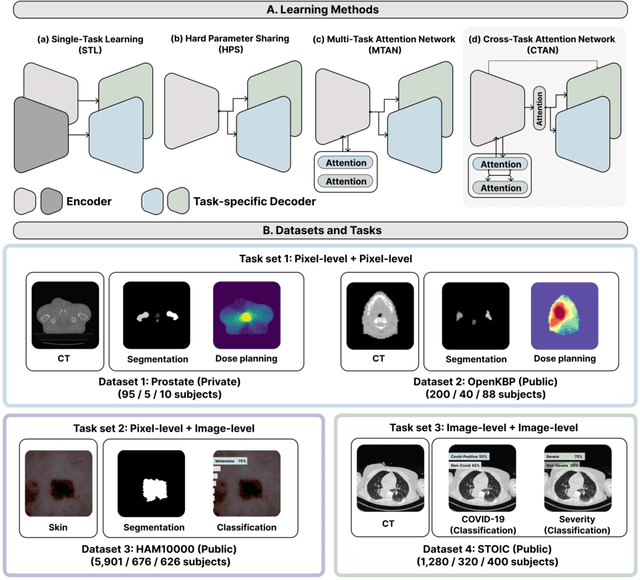

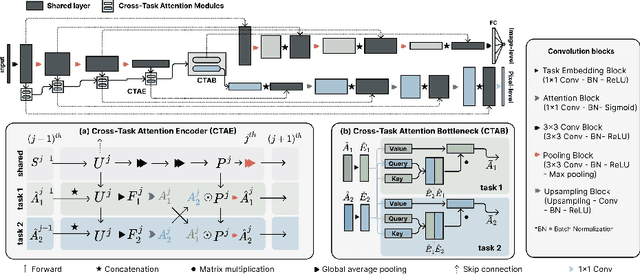
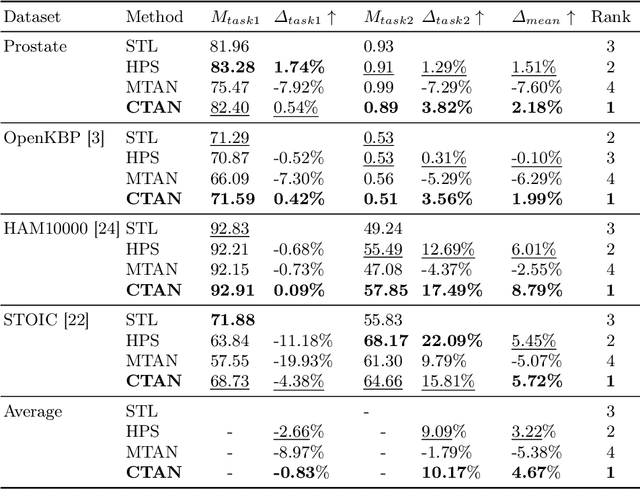
Multi-task learning (MTL) is a powerful approach in deep learning that leverages the information from multiple tasks during training to improve model performance. In medical imaging, MTL has shown great potential to solve various tasks. However, existing MTL architectures in medical imaging are limited in sharing information across tasks, reducing the potential performance improvements of MTL. In this study, we introduce a novel attention-based MTL framework to better leverage inter-task interactions for various tasks from pixel-level to image-level predictions. Specifically, we propose a Cross-Task Attention Network (CTAN) which utilizes cross-task attention mechanisms to incorporate information by interacting across tasks. We validated CTAN on four medical imaging datasets that span different domains and tasks including: radiation treatment planning prediction using planning CT images of two different target cancers (Prostate, OpenKBP); pigmented skin lesion segmentation and diagnosis using dermatoscopic images (HAM10000); and COVID-19 diagnosis and severity prediction using chest CT scans (STOIC). Our study demonstrates the effectiveness of CTAN in improving the accuracy of medical imaging tasks. Compared to standard single-task learning (STL), CTAN demonstrated a 4.67% improvement in performance and outperformed both widely used MTL baselines: hard parameter sharing (HPS) with an average performance improvement of 3.22%; and multi-task attention network (MTAN) with a relative decrease of 5.38%. These findings highlight the significance of our proposed MTL framework in solving medical imaging tasks and its potential to improve their accuracy across domains.
TMO: Textured Mesh Acquisition of Objects with a Mobile Device by using Differentiable Rendering
Mar 27, 2023



We present a new pipeline for acquiring a textured mesh in the wild with a single smartphone which offers access to images, depth maps, and valid poses. Our method first introduces an RGBD-aided structure from motion, which can yield filtered depth maps and refines camera poses guided by corresponding depth. Then, we adopt the neural implicit surface reconstruction method, which allows for high-quality mesh and develops a new training process for applying a regularization provided by classical multi-view stereo methods. Moreover, we apply a differentiable rendering to fine-tune incomplete texture maps and generate textures which are perceptually closer to the original scene. Our pipeline can be applied to any common objects in the real world without the need for either in-the-lab environments or accurate mask images. We demonstrate results of captured objects with complex shapes and validate our method numerically against existing 3D reconstruction and texture mapping methods.