 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Integrated Automated Contouring and Voxel-Based Dose Prediction in Radiotherapy
Nov 27, 2024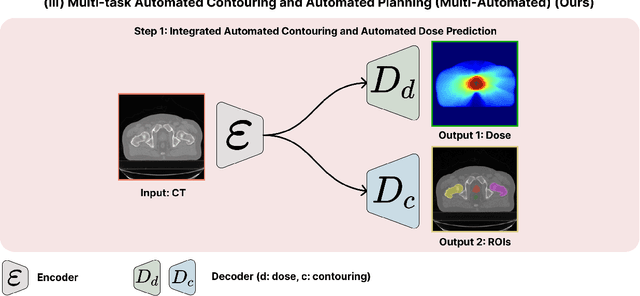
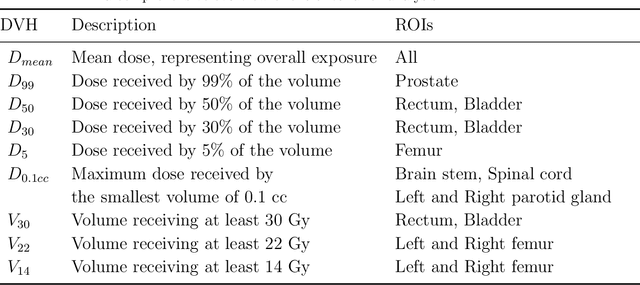
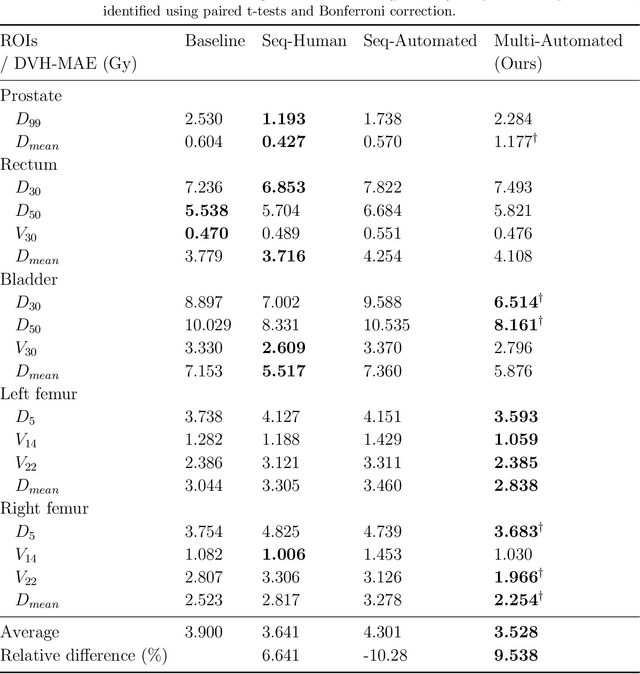
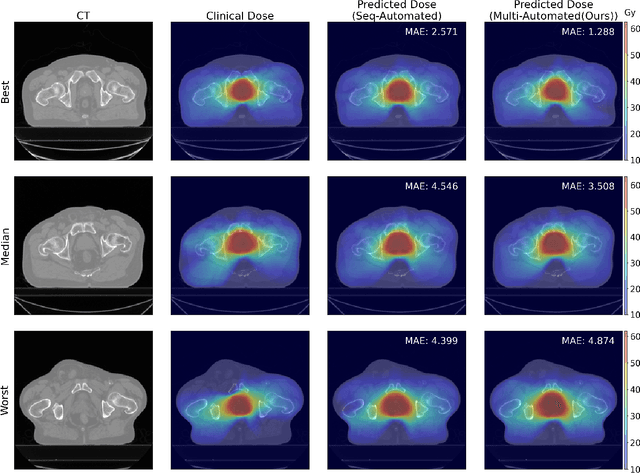
Deep learning-based automated contouring and treatment planning has been proven to improve the efficiency and accuracy of radiotherapy. However, conventional radiotherapy treatment planning process has the automated contouring and treatment planning as separate tasks. Moreover in deep learning (DL), the contouring and dose prediction tasks for automated treatment planning are done independently. In this study, we applied the multi-task learning (MTL) approach in order to seamlessly integrate automated contouring and voxel-based dose prediction tasks, as MTL can leverage common information between the two tasks and be able able to increase the efficiency of the automated tasks. We developed our MTL framework using the two datasets: in-house prostate cancer dataset and the publicly available head and neck cancer dataset, OpenKBP. Compared to the sequential DL contouring and treatment planning tasks, our proposed method using MTL improved the mean absolute difference of dose volume histogram metrics of prostate and head and neck sites by 19.82% and 16.33%, respectively. Our MTL model for automated contouring and dose prediction tasks demonstrated enhanced dose prediction performance while maintaining or sometimes even improving the contouring accuracy. Compared to the baseline automated contouring model with the dice score coefficients of 0.818 for prostate and 0.674 for head and neck datasets, our MTL approach achieved average scores of 0.824 and 0.716 for these datasets, respectively. Our study highlights the potential of the proposed automated contouring and planning using MTL to support the development of efficient and accurate automated treatment planning for radiotherapy.
Cross-Task Attention Network: Improving Multi-Task Learning for Medical Imaging Applications
Sep 07, 2023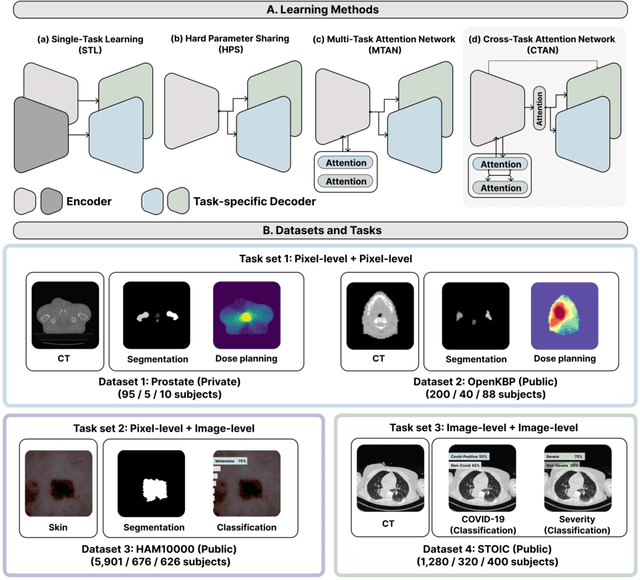

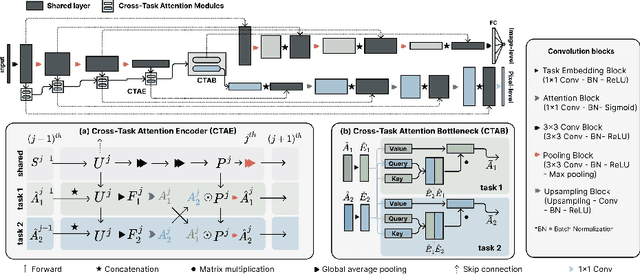
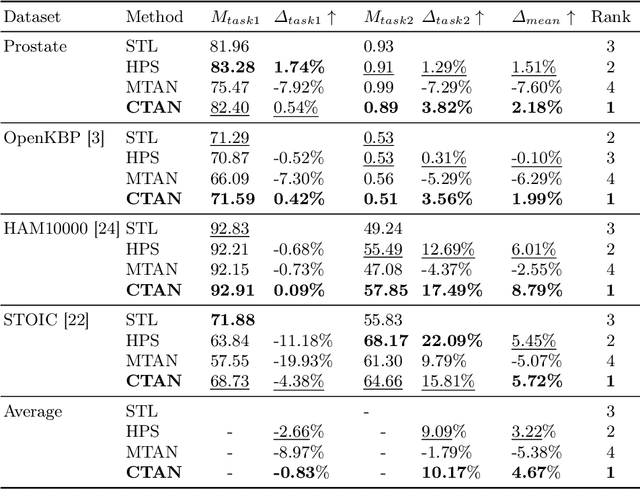
Multi-task learning (MTL) is a powerful approach in deep learning that leverages the information from multiple tasks during training to improve model performance. In medical imaging, MTL has shown great potential to solve various tasks. However, existing MTL architectures in medical imaging are limited in sharing information across tasks, reducing the potential performance improvements of MTL. In this study, we introduce a novel attention-based MTL framework to better leverage inter-task interactions for various tasks from pixel-level to image-level predictions. Specifically, we propose a Cross-Task Attention Network (CTAN) which utilizes cross-task attention mechanisms to incorporate information by interacting across tasks. We validated CTAN on four medical imaging datasets that span different domains and tasks including: radiation treatment planning prediction using planning CT images of two different target cancers (Prostate, OpenKBP); pigmented skin lesion segmentation and diagnosis using dermatoscopic images (HAM10000); and COVID-19 diagnosis and severity prediction using chest CT scans (STOIC). Our study demonstrates the effectiveness of CTAN in improving the accuracy of medical imaging tasks. Compared to standard single-task learning (STL), CTAN demonstrated a 4.67% improvement in performance and outperformed both widely used MTL baselines: hard parameter sharing (HPS) with an average performance improvement of 3.22%; and multi-task attention network (MTAN) with a relative decrease of 5.38%. These findings highlight the significance of our proposed MTL framework in solving medical imaging tasks and its potential to improve their accuracy across domains.
Domain Adaptation of Automated Treatment Planning from Computed Tomography to Magnetic Resonance
Mar 07, 2022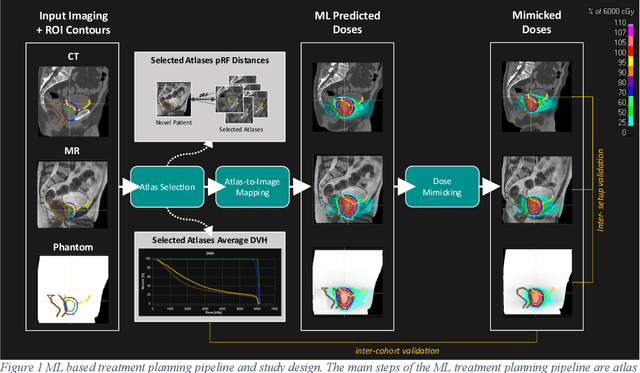
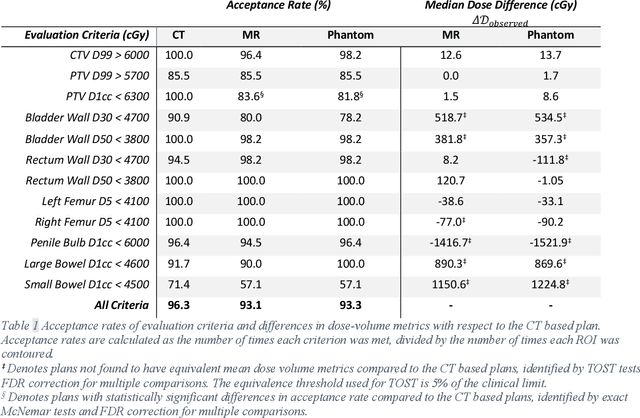
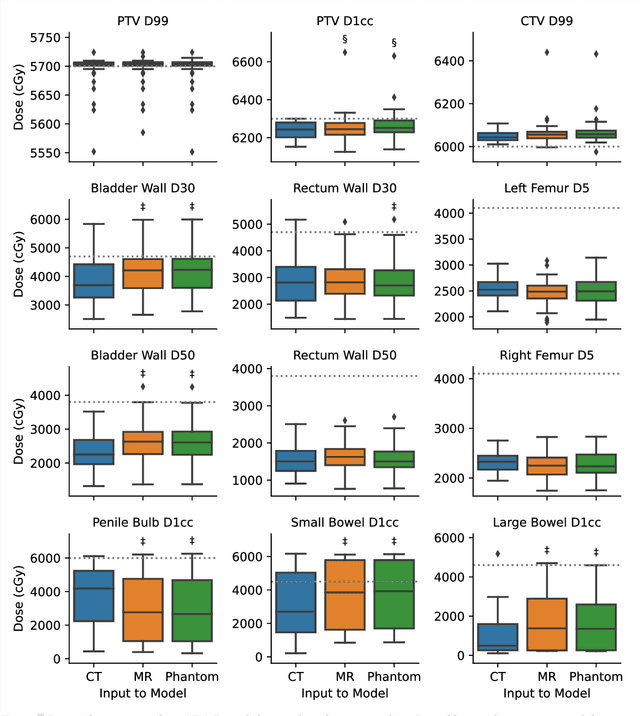
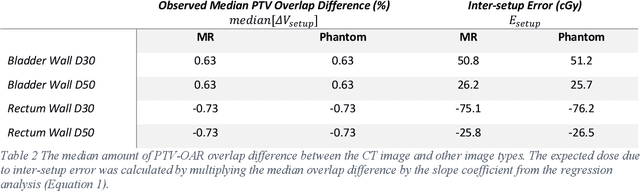
Objective: Machine learning (ML) based radiation treatment (RT) planning addresses the iterative and time-consuming nature of conventional inverse planning. Given the rising importance of Magnetic resonance (MR) only treatment planning workflows, we sought to determine if an ML based treatment planning model, trained on computed tomography (CT) imaging, could be applied to MR through domain adaptation. Methods: In this study, MR and CT imaging was collected from 55 prostate cancer patients treated on an MR linear accelerator. ML based plans were generated for each patient on both CT and MR imaging using a commercially available model in RayStation 8B. The dose distributions and acceptance rates of MR and CT based plans were compared using institutional dose-volume evaluation criteria. The dosimetric differences between MR and CT plans were further decomposed into setup, cohort, and imaging domain components. Results: MR plans were highly acceptable, meeting 93.1% of all evaluation criteria compared to 96.3% of CT plans, with dose equivalence for all evaluation criteria except for the bladder wall, penile bulb, small and large bowel, and one rectum wall criteria (p<0.05). Changing the input imaging modality (domain component) only accounted for about half of the dosimetric differences observed between MR and CT plans. Anatomical differences between the ML training set and the MR linac cohort (cohort component) were also a significant contributor. Significance: We were able to create highly acceptable MR based treatment plans using a CT-trained ML model for treatment planning, although clinically significant dose deviations from the CT based plans were observed.
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

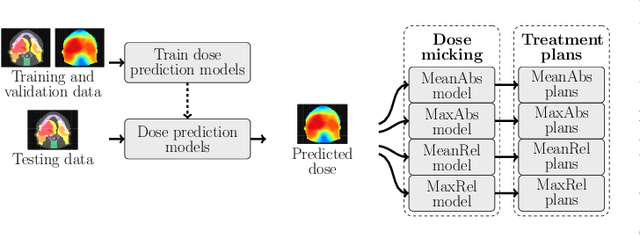
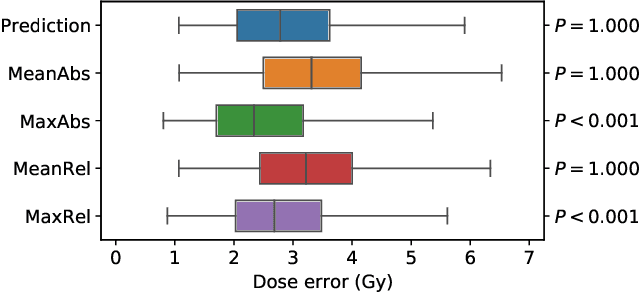
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
OpenKBP: The open-access knowledge-based planning grand challenge
Nov 28, 2020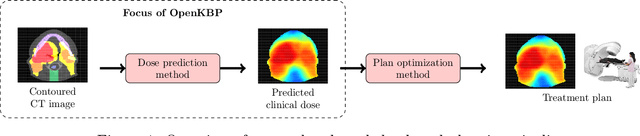

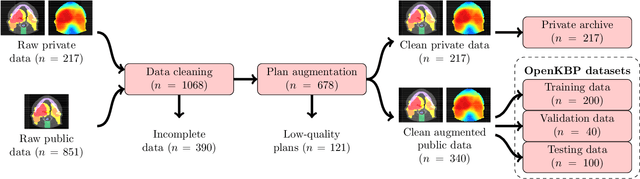
The purpose of this work is to advance fair and consistent comparisons of dose prediction methods for knowledge-based planning (KBP) in radiation therapy research. We hosted OpenKBP, a 2020 AAPM Grand Challenge, and challenged participants to develop the best method for predicting the dose of contoured CT images. The models were evaluated according to two separate scores: (1) dose score, which evaluates the full 3D dose distributions, and (2) dose-volume histogram (DVH) score, which evaluates a set DVH metrics. Participants were given the data of 340 patients who were treated for head-and-neck cancer with radiation therapy. The data was partitioned into training (n=200), validation (n=40), and testing (n=100) datasets. All participants performed training and validation with the corresponding datasets during the validation phase of the Challenge, and we ranked the models in the testing phase based on out-of-sample performance. The Challenge attracted 195 participants from 28 countries, and 73 of those participants formed 44 teams in the validation phase, which received a total of 1750 submissions. The testing phase garnered submissions from 28 teams. On average, over the course of the validation phase, participants improved the dose and DVH scores of their models by a factor of 2.7 and 5.7, respectively. In the testing phase one model achieved significantly better dose and DVH score than the runner-up models. Lastly, many of the top performing teams reported using generalizable techniques (e.g., ensembles) to achieve higher performance than their competition. This is the first competition for knowledge-based planning research, and it helped launch the first platform for comparing KBP prediction methods fairly and consistently. The OpenKBP datasets are available publicly to help benchmark future KBP research, which has also democratized KBP research by making it accessible to everyone.