 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Integrated Automated Contouring and Voxel-Based Dose Prediction in Radiotherapy
Nov 27, 2024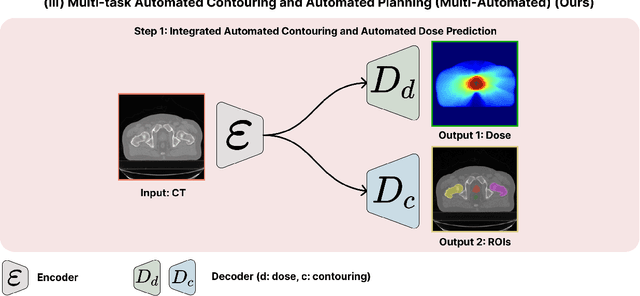
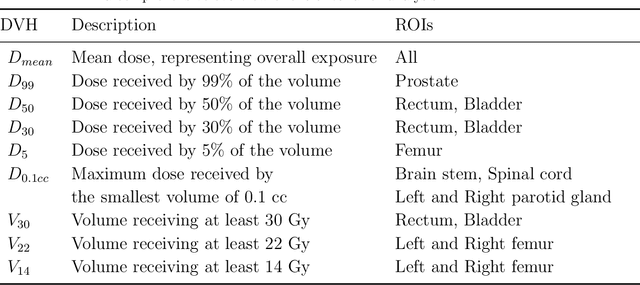
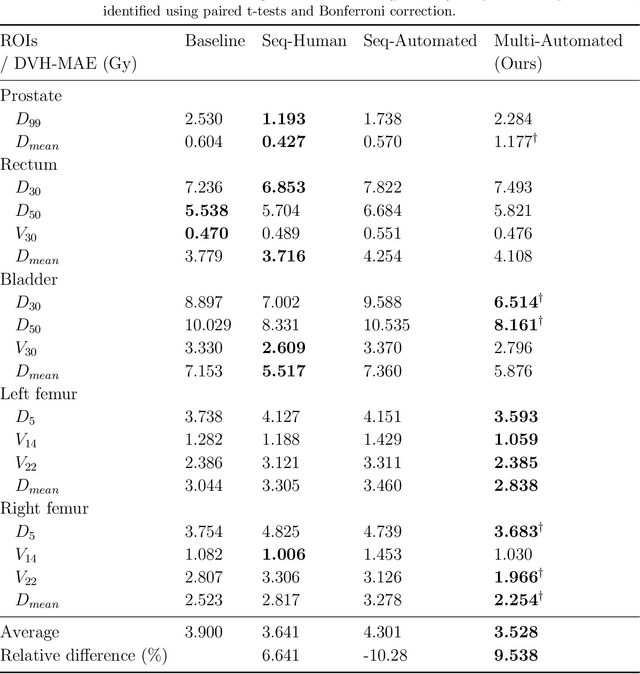
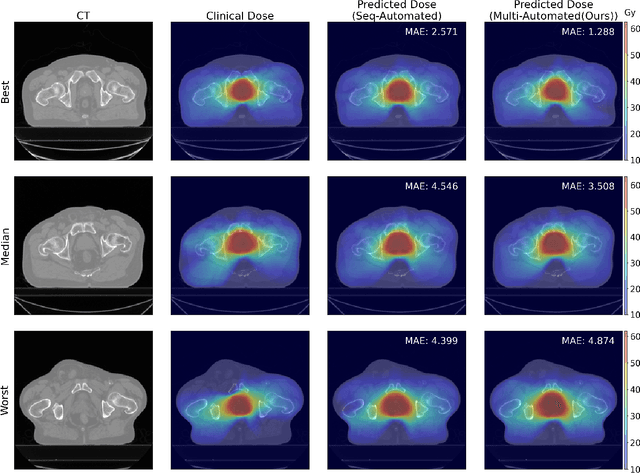
Deep learning-based automated contouring and treatment planning has been proven to improve the efficiency and accuracy of radiotherapy. However, conventional radiotherapy treatment planning process has the automated contouring and treatment planning as separate tasks. Moreover in deep learning (DL), the contouring and dose prediction tasks for automated treatment planning are done independently. In this study, we applied the multi-task learning (MTL) approach in order to seamlessly integrate automated contouring and voxel-based dose prediction tasks, as MTL can leverage common information between the two tasks and be able able to increase the efficiency of the automated tasks. We developed our MTL framework using the two datasets: in-house prostate cancer dataset and the publicly available head and neck cancer dataset, OpenKBP. Compared to the sequential DL contouring and treatment planning tasks, our proposed method using MTL improved the mean absolute difference of dose volume histogram metrics of prostate and head and neck sites by 19.82% and 16.33%, respectively. Our MTL model for automated contouring and dose prediction tasks demonstrated enhanced dose prediction performance while maintaining or sometimes even improving the contouring accuracy. Compared to the baseline automated contouring model with the dice score coefficients of 0.818 for prostate and 0.674 for head and neck datasets, our MTL approach achieved average scores of 0.824 and 0.716 for these datasets, respectively. Our study highlights the potential of the proposed automated contouring and planning using MTL to support the development of efficient and accurate automated treatment planning for radiotherapy.
Semantic-Aware Environment Perception for Mobile Human-Robot Interaction
Nov 07, 2022Current technological advances open up new opportunities for bringing human-machine interaction to a new level of human-centered cooperation. In this context, a key issue is the semantic understanding of the environment in order to enable mobile robots more complex interactions and a facilitated communication with humans. Prerequisites are the vision-based registration of semantic objects and humans, where the latter are further analyzed for potential interaction partners. Despite significant research achievements, the reliable and fast registration of semantic information still remains a challenging task for mobile robots in real-world scenarios. In this paper, we present a vision-based system for mobile assistive robots to enable a semantic-aware environment perception without additional a-priori knowledge. We deploy our system on a mobile humanoid robot that enables us to test our methods in real-world applications.
* ISPA 2012
Domain Adaptation of Automated Treatment Planning from Computed Tomography to Magnetic Resonance
Mar 07, 2022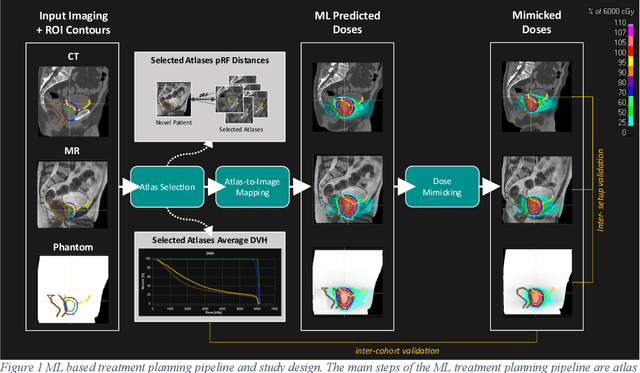
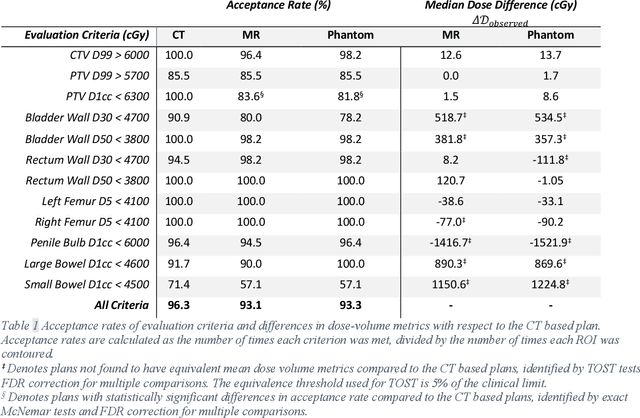
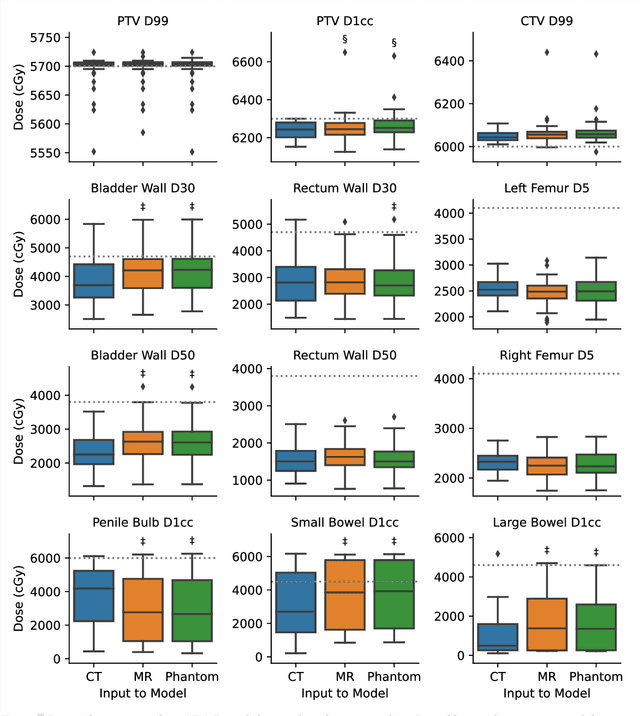
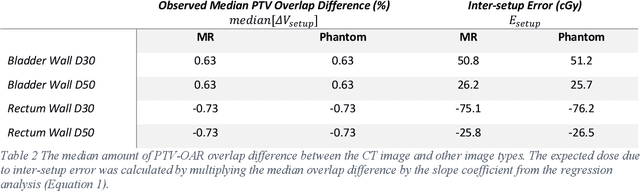
Objective: Machine learning (ML) based radiation treatment (RT) planning addresses the iterative and time-consuming nature of conventional inverse planning. Given the rising importance of Magnetic resonance (MR) only treatment planning workflows, we sought to determine if an ML based treatment planning model, trained on computed tomography (CT) imaging, could be applied to MR through domain adaptation. Methods: In this study, MR and CT imaging was collected from 55 prostate cancer patients treated on an MR linear accelerator. ML based plans were generated for each patient on both CT and MR imaging using a commercially available model in RayStation 8B. The dose distributions and acceptance rates of MR and CT based plans were compared using institutional dose-volume evaluation criteria. The dosimetric differences between MR and CT plans were further decomposed into setup, cohort, and imaging domain components. Results: MR plans were highly acceptable, meeting 93.1% of all evaluation criteria compared to 96.3% of CT plans, with dose equivalence for all evaluation criteria except for the bladder wall, penile bulb, small and large bowel, and one rectum wall criteria (p<0.05). Changing the input imaging modality (domain component) only accounted for about half of the dosimetric differences observed between MR and CT plans. Anatomical differences between the ML training set and the MR linac cohort (cohort component) were also a significant contributor. Significance: We were able to create highly acceptable MR based treatment plans using a CT-trained ML model for treatment planning, although clinically significant dose deviations from the CT based plans were observed.
L2CS-Net: Fine-Grained Gaze Estimation in Unconstrained Environments
Mar 07, 2022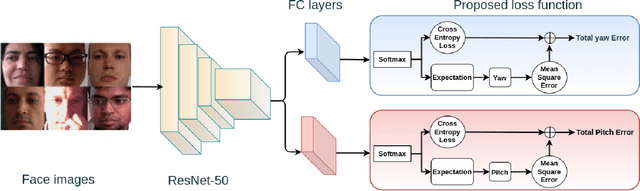
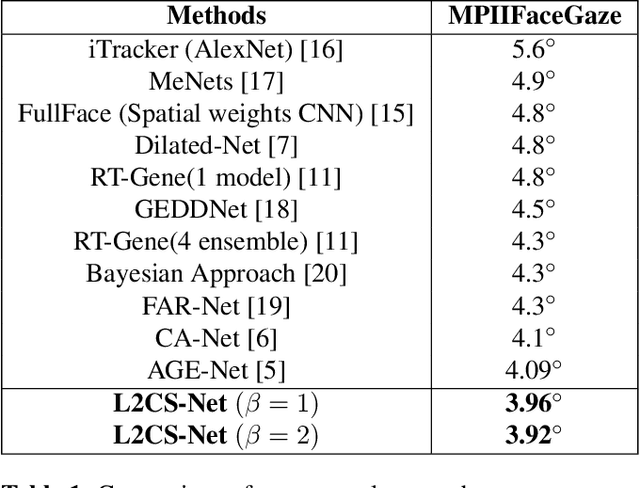
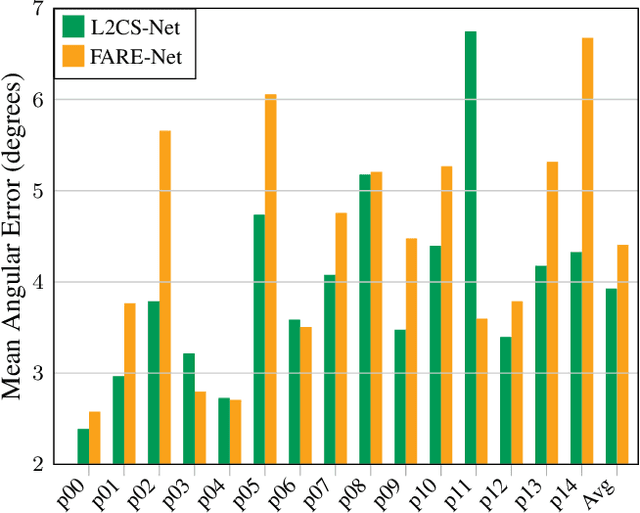
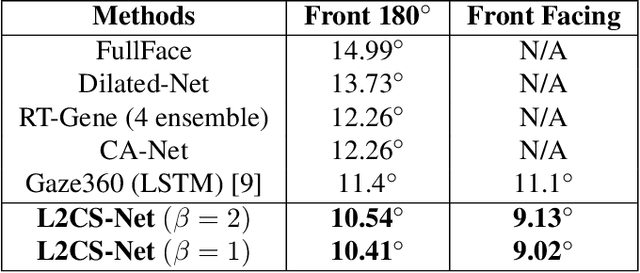
Human gaze is a crucial cue used in various applications such as human-robot interaction and virtual reality. Recently, convolution neural network (CNN) approaches have made notable progress in predicting gaze direction. However, estimating gaze in-the-wild is still a challenging problem due to the uniqueness of eye appearance, lightning conditions, and the diversity of head pose and gaze directions. In this paper, we propose a robust CNN-based model for predicting gaze in unconstrained settings. We propose to regress each gaze angle separately to improve the per-angel prediction accuracy, which will enhance the overall gaze performance. In addition, we use two identical losses, one for each angle, to improve network learning and increase its generalization. We evaluate our model with two popular datasets collected with unconstrained settings. Our proposed model achieves state-of-the-art accuracy of 3.92{\deg} and 10.41{\deg} on MPIIGaze and Gaze360 datasets, respectively. We make our code open source at https://github.com/Ahmednull/L2CS-Net.