 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNITEC: Versatile Hand-Annotated Eye Contact Dataset for Ego-Vision Interaction
Nov 08, 2023



Eye contact is a crucial non-verbal interaction modality and plays an important role in our everyday social life. While humans are very sensitive to eye contact, the capabilities of machines to capture a person's gaze are still mediocre. We tackle this challenge and present NITEC, a hand-annotated eye contact dataset for ego-vision interaction. NITEC exceeds existing datasets for ego-vision eye contact in size and variety of demographics, social contexts, and lighting conditions, making it a valuable resource for advancing ego-vision-based eye contact research. Our extensive evaluations on NITEC demonstrate strong cross-dataset performance, emphasizing its effectiveness and adaptability in various scenarios, that allows seamless utilization to the fields of computer vision, human-computer interaction, and social robotics. We make our NITEC dataset publicly available to foster reproducibility and further exploration in the field of ego-vision interaction. https://github.com/thohemp/nitec
Towards Robust and Unconstrained Full Range of Rotation Head Pose Estimation
Sep 14, 2023Estimating the head pose of a person is a crucial problem for numerous applications that is yet mainly addressed as a subtask of frontal pose prediction. We present a novel method for unconstrained end-to-end head pose estimation to tackle the challenging task of full range of orientation head pose prediction. We address the issue of ambiguous rotation labels by introducing the rotation matrix formalism for our ground truth data and propose a continuous 6D rotation matrix representation for efficient and robust direct regression. This allows to efficiently learn full rotation appearance and to overcome the limitations of the current state-of-the-art. Together with new accumulated training data that provides full head pose rotation data and a geodesic loss approach for stable learning, we design an advanced model that is able to predict an extended range of head orientations. An extensive evaluation on public datasets demonstrates that our method significantly outperforms other state-of-the-art methods in an efficient and robust manner, while its advanced prediction range allows the expansion of the application area. We open-source our training and testing code along with our trained models: https://github.com/thohemp/6DRepNet360.
Automated Deception Detection from Videos: Using End-to-End Learning Based High-Level Features and Classification Approaches
Jul 13, 2023Deception detection is an interdisciplinary field attracting researchers from psychology, criminology, computer science, and economics. We propose a multimodal approach combining deep learning and discriminative models for automated deception detection. Using video modalities, we employ convolutional end-to-end learning to analyze gaze, head pose, and facial expressions, achieving promising results compared to state-of-the-art methods. Due to limited training data, we also utilize discriminative models for deception detection. Although sequence-to-class approaches are explored, discriminative models outperform them due to data scarcity. Our approach is evaluated on five datasets, including a new Rolling-Dice Experiment motivated by economic factors. Results indicate that facial expressions outperform gaze and head pose, and combining modalities with feature selection enhances detection performance. Differences in expressed features across datasets emphasize the importance of scenario-specific training data and the influence of context on deceptive behavior. Cross-dataset experiments reinforce these findings. Despite the challenges posed by low-stake datasets, including the Rolling-Dice Experiment, deception detection performance exceeds chance levels. Our proposed multimodal approach and comprehensive evaluation shed light on the potential of automating deception detection from video modalities, opening avenues for future research.
Sentiment-based Engagement Strategies for intuitive Human-Robot Interaction
Jan 10, 2023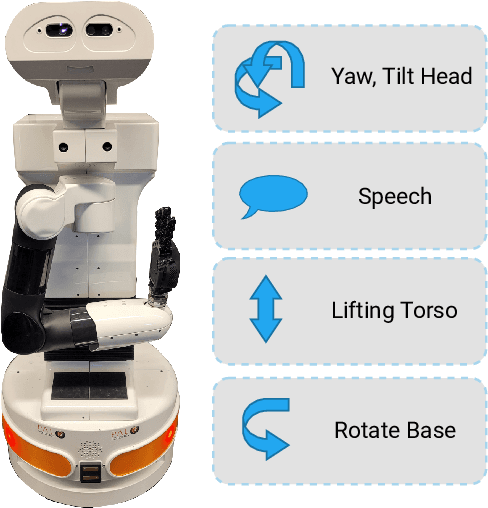
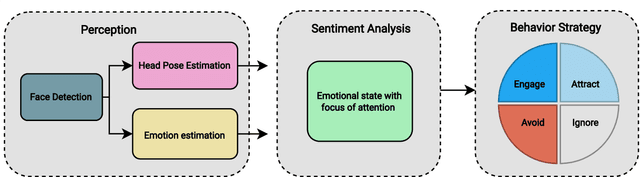
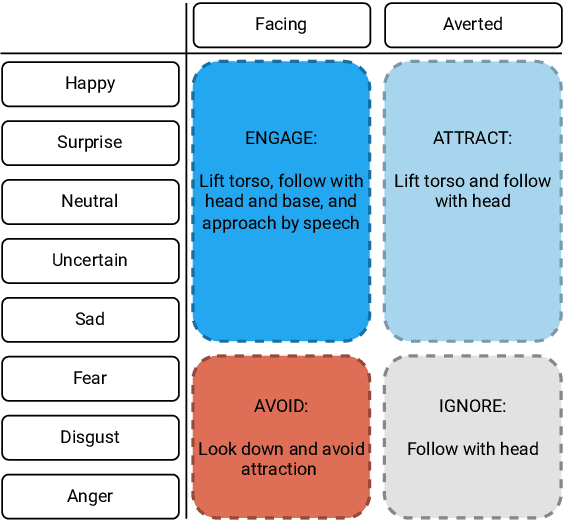

Emotion expressions serve as important communicative signals and are crucial cues in intuitive interactions between humans. Hence, it is essential to include these fundamentals in robotic behavior strategies when interacting with humans to promote mutual understanding and to reduce misjudgements. We tackle this challenge by detecting and using the emotional state and attention for a sentiment analysis of potential human interaction partners to select well-adjusted engagement strategies. This way, we pave the way for more intuitive human-robot interactions, as the robot's action conforms to the person's mood and expectation. We propose four different engagement strategies with implicit and explicit communication techniques that we implement on a mobile robot platform for initial experiments.
Semantic-Aware Environment Perception for Mobile Human-Robot Interaction
Nov 07, 2022Current technological advances open up new opportunities for bringing human-machine interaction to a new level of human-centered cooperation. In this context, a key issue is the semantic understanding of the environment in order to enable mobile robots more complex interactions and a facilitated communication with humans. Prerequisites are the vision-based registration of semantic objects and humans, where the latter are further analyzed for potential interaction partners. Despite significant research achievements, the reliable and fast registration of semantic information still remains a challenging task for mobile robots in real-world scenarios. In this paper, we present a vision-based system for mobile assistive robots to enable a semantic-aware environment perception without additional a-priori knowledge. We deploy our system on a mobile humanoid robot that enables us to test our methods in real-world applications.
* ISPA 2012
An Online Semantic Mapping System for Extending and Enhancing Visual SLAM
Mar 08, 2022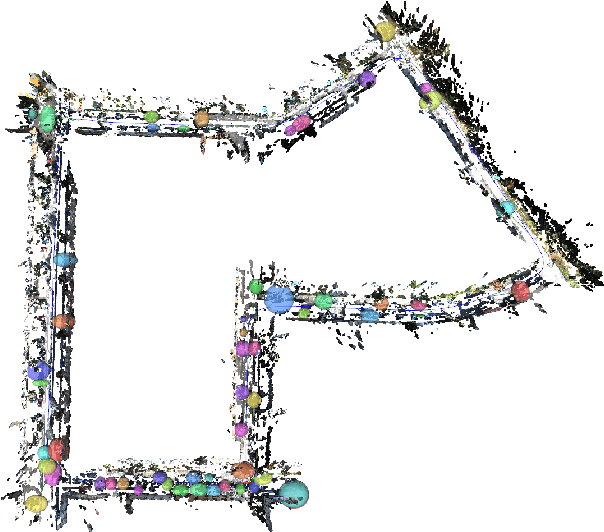
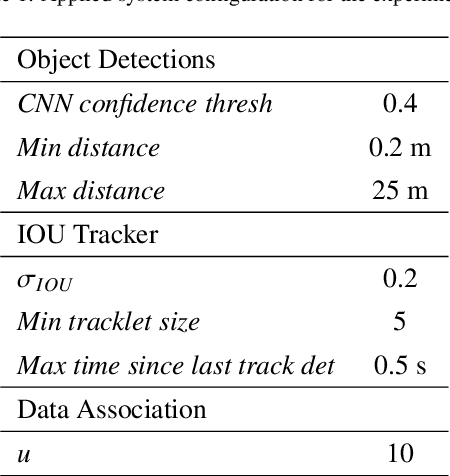
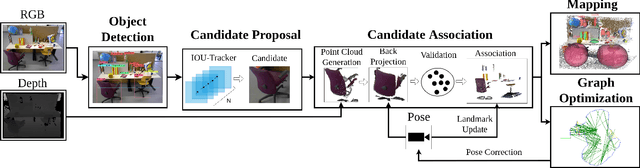
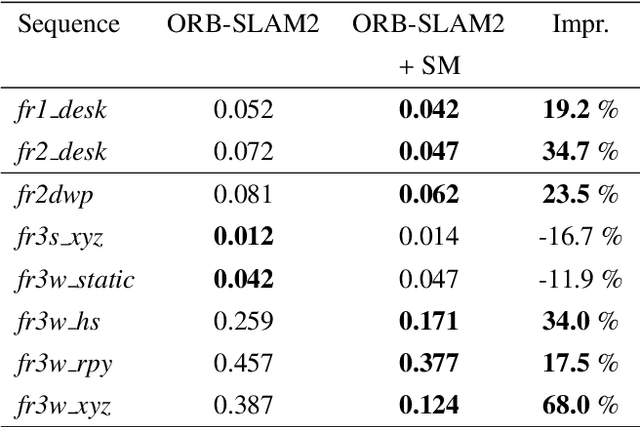
We present a real-time semantic mapping approach for mobile vision systems with a 2D to 3D object detection pipeline and rapid data association for generated landmarks. Besides the semantic map enrichment the associated detections are further introduced as semantic constraints into a simultaneous localization and mapping (SLAM) system for pose correction purposes. This way, we are able generate additional meaningful information that allows to achieve higher-level tasks, while simultaneously leveraging the view-invariance of object detections to improve the accuracy and the robustness of the odometry estimation. We propose tracklets of locally associated object observations to handle ambiguous and false predictions and an uncertainty-based greedy association scheme for an accelerated processing time. Our system reaches real-time capabilities with an average iteration duration of 65~ms and is able to improve the pose estimation of a state-of-the-art SLAM by up to 68% on a public dataset. Additionally, we implemented our approach as a modular ROS package that makes it straightforward for integration in arbitrary graph-based SLAM methods.
L2CS-Net: Fine-Grained Gaze Estimation in Unconstrained Environments
Mar 07, 2022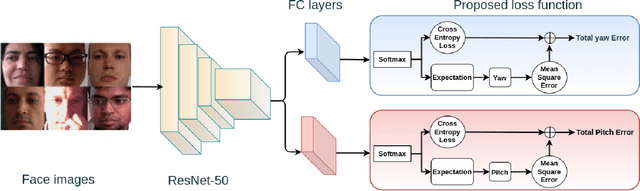
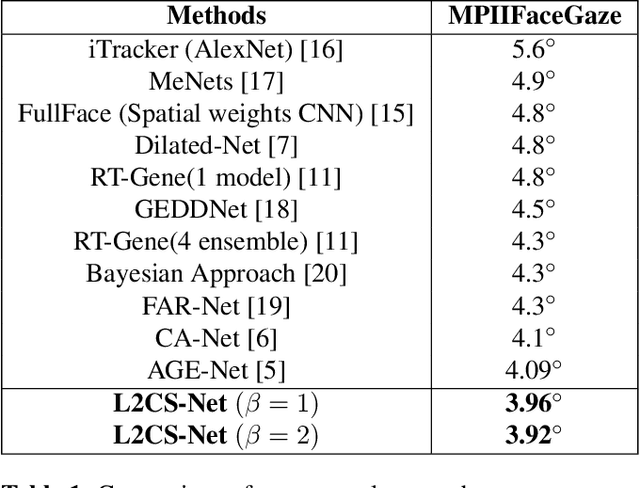
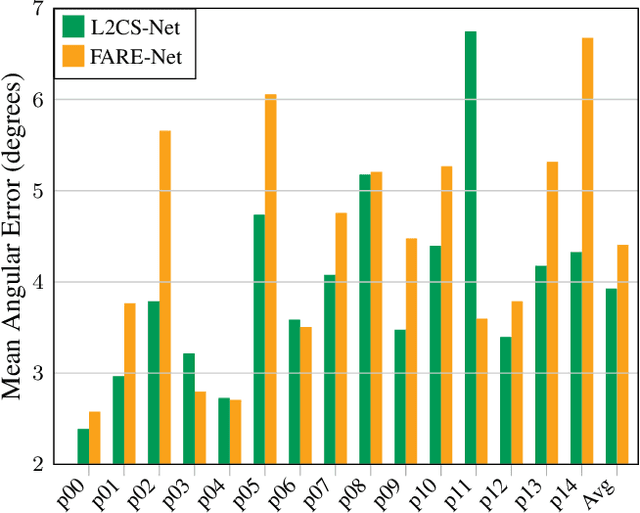
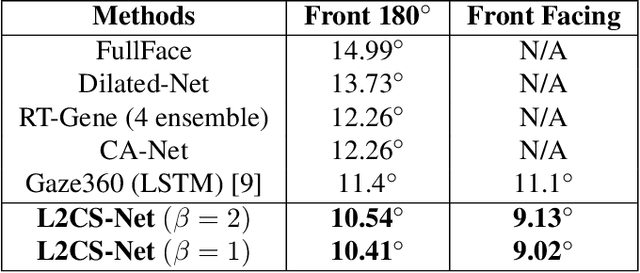
Human gaze is a crucial cue used in various applications such as human-robot interaction and virtual reality. Recently, convolution neural network (CNN) approaches have made notable progress in predicting gaze direction. However, estimating gaze in-the-wild is still a challenging problem due to the uniqueness of eye appearance, lightning conditions, and the diversity of head pose and gaze directions. In this paper, we propose a robust CNN-based model for predicting gaze in unconstrained settings. We propose to regress each gaze angle separately to improve the per-angel prediction accuracy, which will enhance the overall gaze performance. In addition, we use two identical losses, one for each angle, to improve network learning and increase its generalization. We evaluate our model with two popular datasets collected with unconstrained settings. Our proposed model achieves state-of-the-art accuracy of 3.92{\deg} and 10.41{\deg} on MPIIGaze and Gaze360 datasets, respectively. We make our code open source at https://github.com/Ahmednull/L2CS-Net.
6D Rotation Representation For Unconstrained Head Pose Estimation
Feb 25, 2022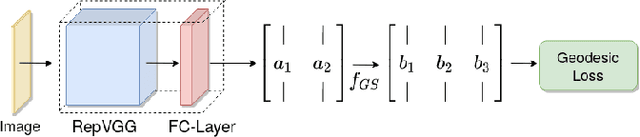
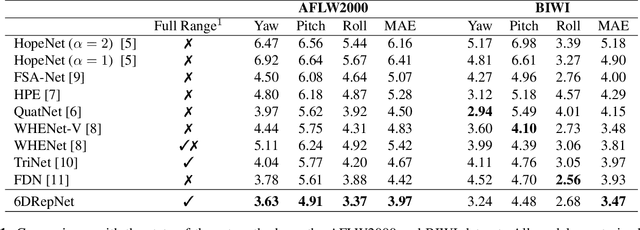

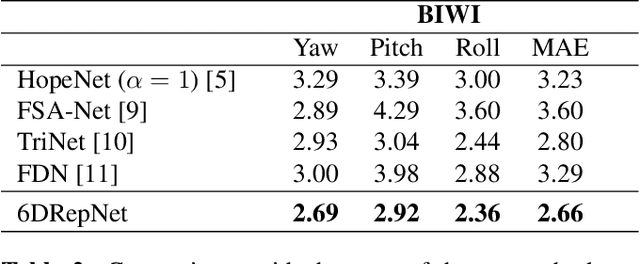
In this paper, we present a method for unconstrained end-to-end head pose estimation. We address the problem of ambiguous rotation labels by introducing the rotation matrix formalism for our ground truth data and propose a continuous 6D rotation matrix representation for efficient and robust direct regression. This way, our method can learn the full rotation appearance which is contrary to previous approaches that restrict the pose prediction to a narrow-angle for satisfactory results. In addition, we propose a geodesic distance-based loss to penalize our network with respect to the SO(3) manifold geometry. Experiments on the public AFLW2000 and BIWI datasets demonstrate that our proposed method significantly outperforms other state-of-the-art methods by up to 20\%. We open-source our training and testing code along with our pre-trained models: https://github.com/thohemp/6DRepNet.