 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Deception Detection from Videos: Using End-to-End Learning Based High-Level Features and Classification Approaches
Jul 13, 2023Deception detection is an interdisciplinary field attracting researchers from psychology, criminology, computer science, and economics. We propose a multimodal approach combining deep learning and discriminative models for automated deception detection. Using video modalities, we employ convolutional end-to-end learning to analyze gaze, head pose, and facial expressions, achieving promising results compared to state-of-the-art methods. Due to limited training data, we also utilize discriminative models for deception detection. Although sequence-to-class approaches are explored, discriminative models outperform them due to data scarcity. Our approach is evaluated on five datasets, including a new Rolling-Dice Experiment motivated by economic factors. Results indicate that facial expressions outperform gaze and head pose, and combining modalities with feature selection enhances detection performance. Differences in expressed features across datasets emphasize the importance of scenario-specific training data and the influence of context on deceptive behavior. Cross-dataset experiments reinforce these findings. Despite the challenges posed by low-stake datasets, including the Rolling-Dice Experiment, deception detection performance exceeds chance levels. Our proposed multimodal approach and comprehensive evaluation shed light on the potential of automating deception detection from video modalities, opening avenues for future research.
Sentiment-based Engagement Strategies for intuitive Human-Robot Interaction
Jan 10, 2023
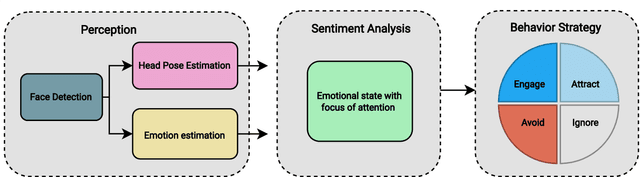
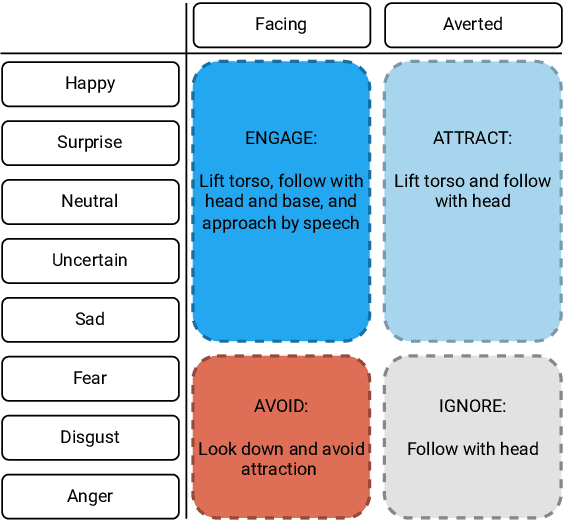

Emotion expressions serve as important communicative signals and are crucial cues in intuitive interactions between humans. Hence, it is essential to include these fundamentals in robotic behavior strategies when interacting with humans to promote mutual understanding and to reduce misjudgements. We tackle this challenge by detecting and using the emotional state and attention for a sentiment analysis of potential human interaction partners to select well-adjusted engagement strategies. This way, we pave the way for more intuitive human-robot interactions, as the robot's action conforms to the person's mood and expectation. We propose four different engagement strategies with implicit and explicit communication techniques that we implement on a mobile robot platform for initial experiments.
Semantic-Aware Environment Perception for Mobile Human-Robot Interaction
Nov 07, 2022Current technological advances open up new opportunities for bringing human-machine interaction to a new level of human-centered cooperation. In this context, a key issue is the semantic understanding of the environment in order to enable mobile robots more complex interactions and a facilitated communication with humans. Prerequisites are the vision-based registration of semantic objects and humans, where the latter are further analyzed for potential interaction partners. Despite significant research achievements, the reliable and fast registration of semantic information still remains a challenging task for mobile robots in real-world scenarios. In this paper, we present a vision-based system for mobile assistive robots to enable a semantic-aware environment perception without additional a-priori knowledge. We deploy our system on a mobile humanoid robot that enables us to test our methods in real-world applications.
* ISPA 2012
Fast and Precise Binary Instance Segmentation of 2D Objects for Automotive Applications
Aug 24, 2022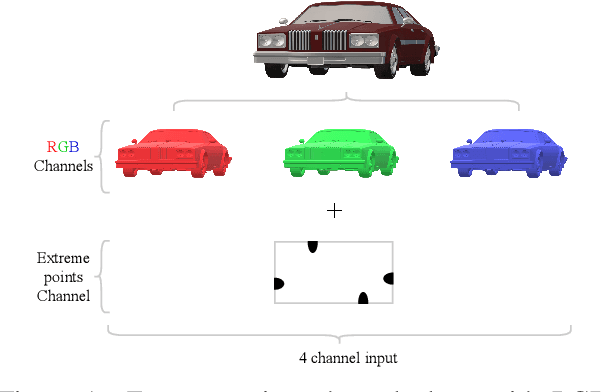
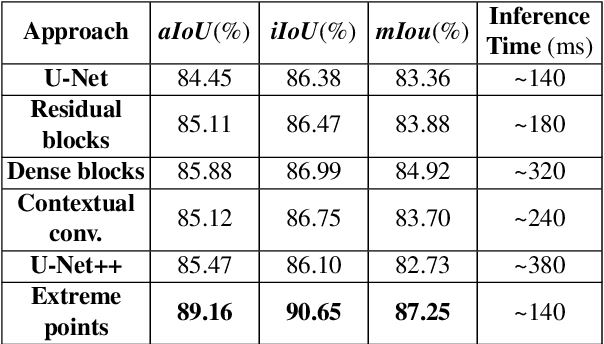
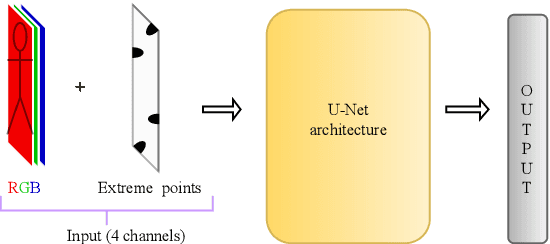
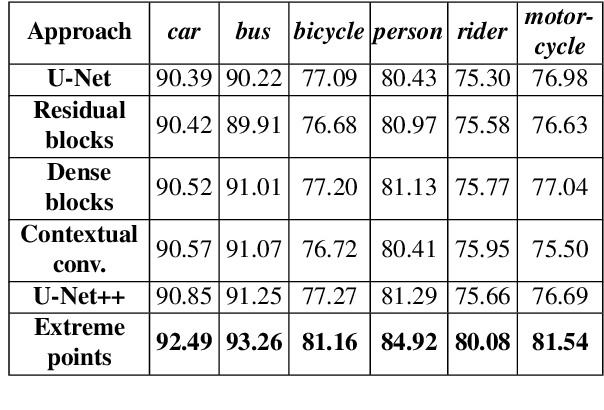
In this paper, we focus on improving binary 2D instance segmentation to assist humans in labeling ground truth datasets with polygons. Humans labeler just have to draw boxes around objects, and polygons are generated automatically. To be useful, our system has to run on CPUs in real-time. The most usual approach for binary instance segmentation involves encoder-decoder networks. This report evaluates state-of-the-art encoder-decoder networks and proposes a method for improving instance segmentation quality using these networks. Alongside network architecture improvements, our proposed method relies upon providing extra information to the network input, so-called extreme points, i.e. the outermost points on the object silhouette. The user can label them instead of a bounding box almost as quickly. The bounding box can be deduced from the extreme points as well. This method produces better IoU compared to other state-of-the-art encoder-decoder networks and also runs fast enough when it is deployed on a CPU.
* 4 pages, 4 figures, WSCG 2022 conference [WSCG 2022 Proceedings, CSRN 3201, ISSN 2464-4617]